第1章 引言 最近要从SEC证券分析报告中提取分析师的相关信息,目前写的code提取率在95%以上,其实也算不错了,但还有小几百份无法提取,主要原因是分析报告的pdf文档被加密了,转码
第1章 引言
最近要从SEC证券分析报告中提取分析师的相关信息,目前写的code提取率在95%以上,其实也算不错了,但还有小几百份无法提取,主要原因是分析报告的pdf文档被加密了,转码后识别全部为乱码,所以想到了用OCR文字识别来完成这项任务 (百度提供了一千次有效识别次数) 。
第2章 正文
本文使用的是百度接口,以下为百度官方相关教程链接官方文档教程直通车:百度OCR文字识别官方文档教程官方视频教程直通车:百度OCR文字识别官方视频教程
2.1百度图片识别
2.1.1 登录/注册百度账号,完成实名认证,领取免费权利,创建新应用
这一步参考上面给的官方视频教程直通车进行操作即可
2.1.2 获取Token

2.1.3 将得到的Token粘贴至代码相应位置,即可成功运行~
各种语言的相关代码可以查看以下链接:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhuhttps://ai.baidu.com/ai-doc/OCR/1k3h7y3db
2.1.4 完整代码如下
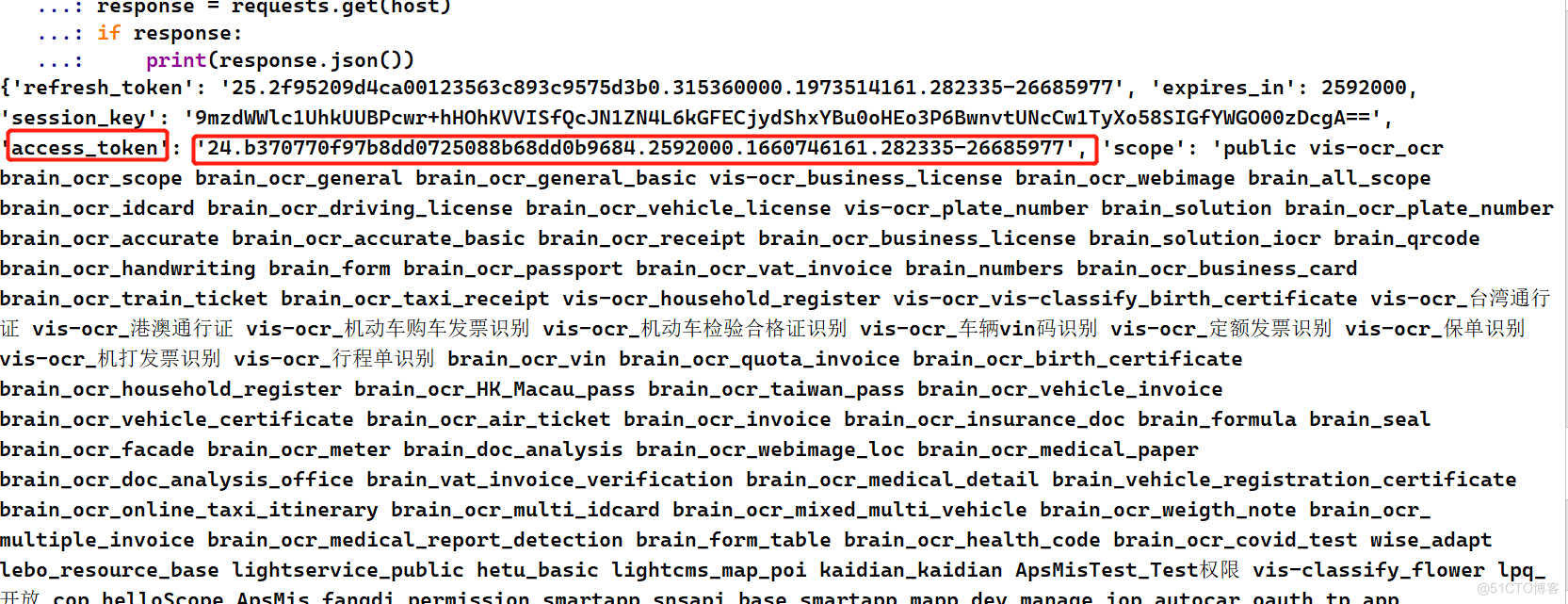
第一步:传入AK和SK获取access_token
# -*- coding: utf-8 -*- # 导入需要的第三方库 import requests import base64 # client_id 为官网获取的AK, client_secret 为官网获取的SK AK = '【修改为你的AK】' SK = '【修改为你的SK】' host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(AK, SK) response = requests.get(host) if response: print(response.json())在返回值提取access_token
第二步:传入access_token进行识别
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" # 二进制方式打开图片文件 f = open('【修改为你要进行识别的图片的路径】', 'rb') img = base64.b64encode(f.read()) access_token = '【上一步中得到的access_token】' params = {"image": img} request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) if response: print(response.json())2.1.5 运行结果
- 被识别的图片:

- 识别结果:

识别效果还是不错的~
2.2 pdf文档识别
2.2.1修改步骤
对于识别pdf,主要是要在代码中将pdf文本以base64编码后传输
官网提供的文档链接:https://ai.baidu.com/ai-doc/OCR/ykg9c09ji
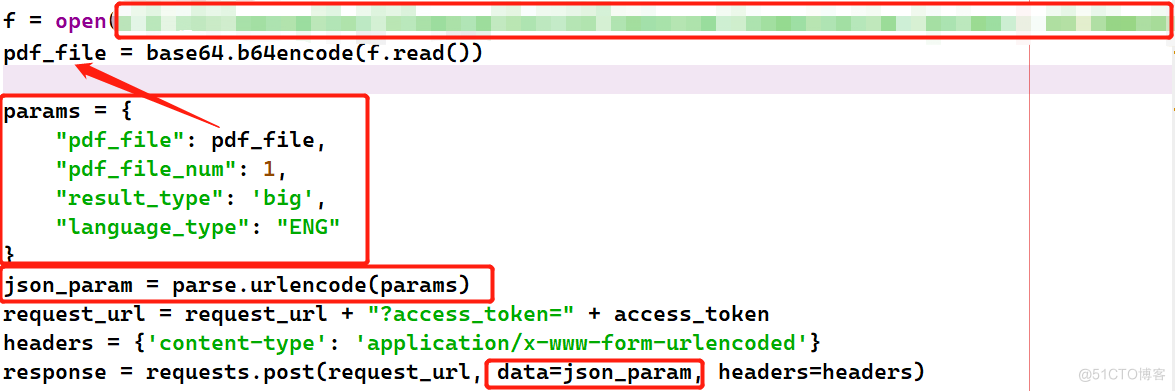
但是上面并没有讲如何传输base64格式的信息,所以这里说一下再提一下。首先可以了解到官方文档中提供了不少所需要的参数,源代码中需要修改的地方见下图
2.2.2 pdf文档提取结果
返回了四个参数,相关参数含义也可以查看相关文档,文本提取的结果存储在reuults当中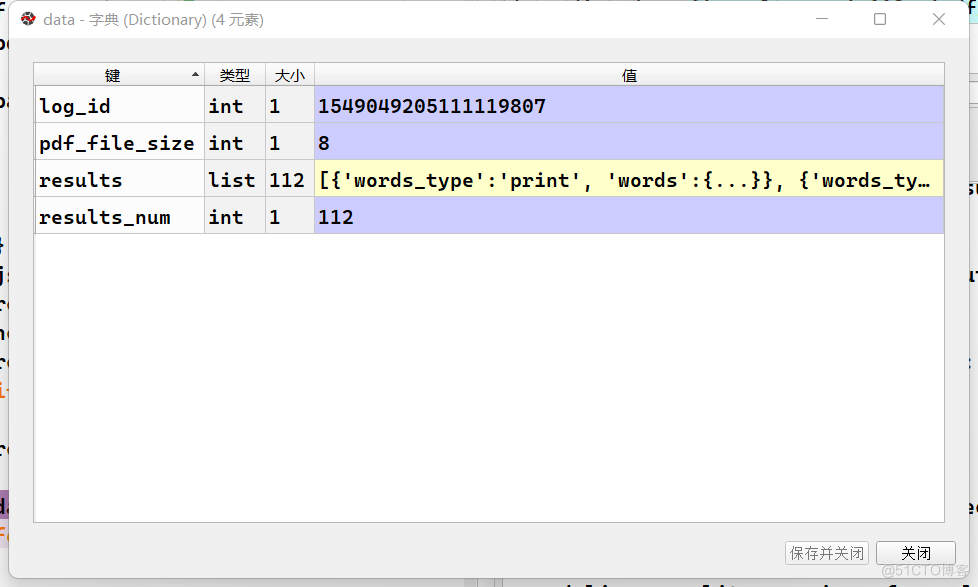
https://ai.baidu.com/ai-doc/OCR/ykg9c09ji
2.3 异常情况
相关异常情况及原因可以查看以下官方文档
https://ai.baidu.com/ai-doc/OCR/dk3h7y5vr
【文章转自日本多IP站群服务器 http://www.558idc.com/japzq.html提供,感恩】