为什么需要代理? 我们爬取数据的时候,开始可以正常爬取,但是过了一段时间,网站可能就会提示“您的IP访问频率过高”,然后就无法正常访问网站。这是因为网站采取了反爬策略
为什么需要代理?
我们爬取数据的时候,开始可以正常爬取,但是过了一段时间,网站可能就会提示“您的IP访问频率过高”,然后就无法正常访问网站。这是因为网站采取了反爬策略,某个ip访问频率超过一个阈值后,就会被禁止访问。这时候我们就可以利用代理ip,来正常访问该网站。(或者,你可以等第二天,ip恢复正常后再访问)
使用代理
首先你要获取一个代理,获取方法很多,网上有免费和付费的代理。这里我使用的是utanshu.com。免费版单日ip上限是5000个,足够个人使用了。用手机号注册,完成职业认证和身份认证就可以使用了。(这个认证是防止滥用ip做一些违法的事情) 目前这个网站主要功能就是提供分布式代理池,后面估计其它的两个功能也会开放。
目前这个网站主要功能就是提供分布式代理池,后面估计其它的两个功能也会开放。
我已经申请了一个账号。登陆后选择分布式代理池,网页会有一个提取API选项,通过网页访问该API(或requests.get(api_url))就会返回一个txt或json格式的数据。里面包含了ip和port。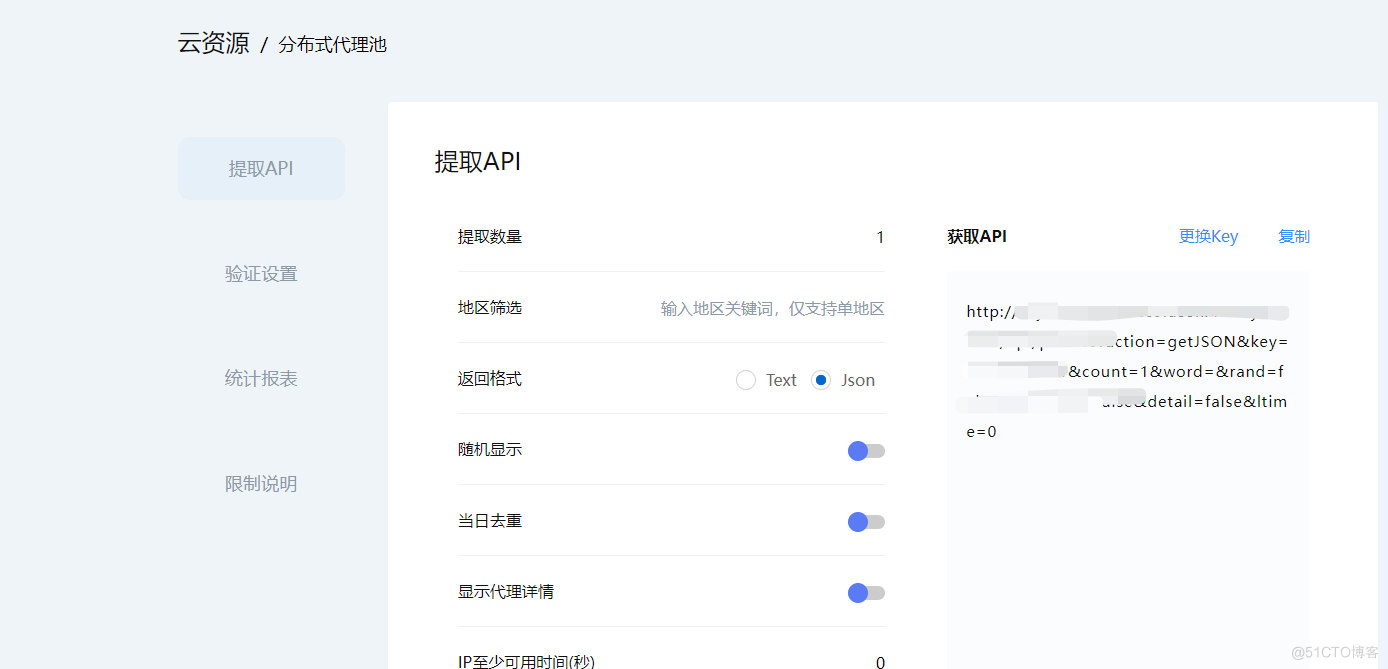
将下面代码中的代理ip、代理端口、代理账号、代理密码替换成自己的即可使用代理获取网页。
import requests import time url='http://www.httpbin.org/get' proxyaddr = "代理IP地址" #代理IP地址 proxyport = 57114 #代理IP端口 proxyusernm = "代理帐号t" #代理帐号 proxypasswd = "代理密码" #代理密码 #name = input(); proxyurl="http://"+proxyusernm+":"+proxypasswd+"@"+proxyaddr+":"+"%d"%proxyport t1 = time.time() r = requests.get(url,proxies={'http':proxyurl,'https':proxyurl},headers={ "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.9", "Cache-Control":"max-age=0", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}) r.encoding='gb2312' t2 = time.time() print(r.text) print("时间差:" , (t2 - t1));打印的内容包含了请求ip地址,发现该地址变成了代理ip,而不是自己的本机ip了。