大家好,我是老彭。今天是周五,我加班刚到家。
虽然工作很辛苦,但是我今天着实被这帮可爱的彭友萌笑死了。。。
事情是这样的:
一个正常的问题
在数据治理大群里,有个哥们问了这样一个问题:
是不是很正常?有没有问题?没有吧?
乍一看,还是很正常的,这题没超纲,我能答!

一群不正常的数据人
但是,你知道的,肯定有一个但是!有人跳出来了!而且还不止一个!!!
emmmm????好像不太对啊?我想了想我的硕士学位证,的确是这样的。
又有一位大佬过来科普了:


但是,又有一位小伙伴来补充了一句:

我赶紧翻出了我的博士学位证书,哦...我没有博士学位 zhuangbility失败!
zhuangbility失败!
这时候,有人看不下去了:

然后,大家就吵成一团了...我都没法截图给大家看了,太乱了
然后.....有一个朋友贴了一张图,终结了这个问题:
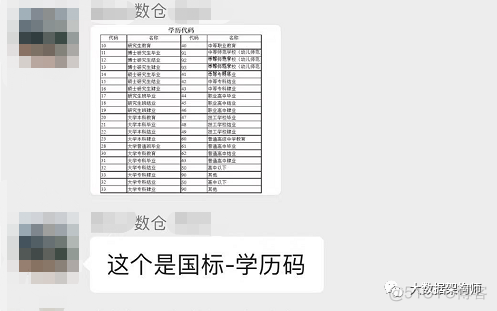
嗯,就是这个,你看看:
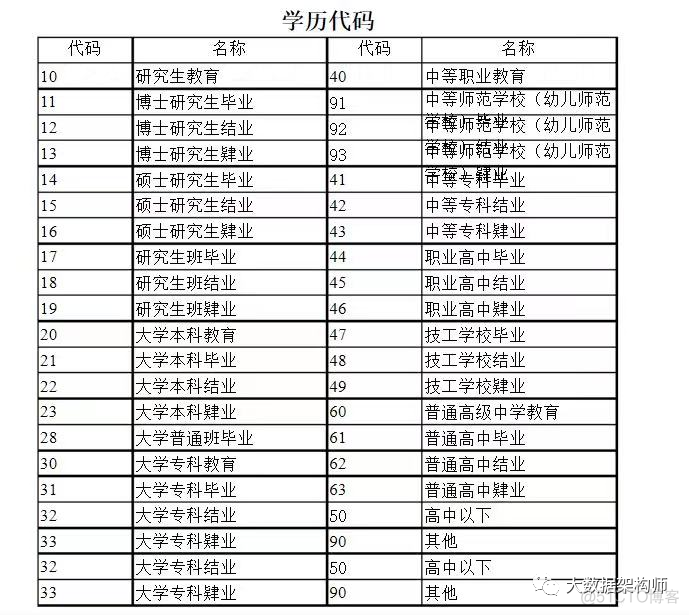
然后有人马上改口了:








我忍不住了,快让我笑一下......你如果不是做数据的,肯定认为我们这帮人有病......。
数据标准中的数据标准
你笑了吗?
如果你笑了,请尽情的笑吧......
但是,当你笑完了,你不妨思考一下,为什么这帮人会为了这个看上去并不重要的问题,一本正经的讨论这么久呢?
因为,这就是数据标准的意义。
大家知道,语言是用来交流的,有非常多的歧义、模糊、含混不清的表述。因为语言是为了快速的达到相互简单理解的目的,追求的是效率。
全球几乎所有语言都这个德行,尤其以中文最为繁复。有很多人还以“中文博大精深”自豪。
语义相反的词,在有些时候居然表达统一个意思,比如“红方大败蓝方”和“红方大胜蓝方”居然是一个意思。
更不用说同一个词,语调不一样,结果都不一样。所以有了质疑全世界的锦州话。
在沟通的时候,追求效率,所以失去一些准确性,这没啥,再确认一次就可以了。但是这些准确性在数据层面就会出大事儿!
因为数据一旦发布,可不能撤回来再解释一通,这不闹笑话了么?所以,在数据的领域,追求的是信息的精确性。
因此,在国家数据标准DCMM中,就把数据标准单独拿出来了:
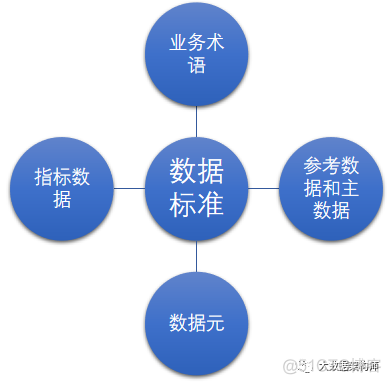
数据标准分为业务术语、参考数据和主数据、数据元、指标数据四大块。其中,像学历、学位这种数据一般会被认定为参考数据。
嗯,你不用管这些乱七八糟的专业术语,反正你只需要记住:国家数据标准里,还有一个数据标准的定义,并且内容还非常丰富。
嗯,你是不是更乱了?
语言和数据
其实,无论哪个行当,一旦想要变得专业,就立刻会变得非常严肃,不近人情,生冷勿近。
比如数学,小学入门就是各种符号...多么不容理解啊?画个小猫小狗不好么?那么容易理解!
比如学术,你看看这些论文写得,就是要让人看不懂。
我前两天在朋友圈吐槽:编辑给我的新书提了非常多的意见,嫌弃我的书里到处都是“口语化”。然后一个朋友这么劝我:

唉...这是要把我平易近人的形象生生变成高冷无比啊...
其实数据也是这样,数据人自然也就这样了。每个数据人看到一个词,立刻会条件反射般的判定是否标准、可量化、可度量。
所以,严格来说,你想的没错,我们有病,你看,我们自己都承认了:
所以,请关爱我们这群有“病”的数据人,我们还是个宝宝...需要抱抱...包包也行
结语
没啥,散了散了!
啥?还要分享资料?emmm,诺,这个给你吧。

公众号“大数据架构师”后台回复“治理标准”,即可获取文件。