资源调度管理 任务调度与资源是通过DAGScheduler、TaskScheduler、SchedulerBackend等进行的作业调度 资源调度是指应用程序如何获得资源 任务调度是在资源调度的基础上进行的,没有资源调度
资源调度管理
Master 资源调度的源码鉴赏
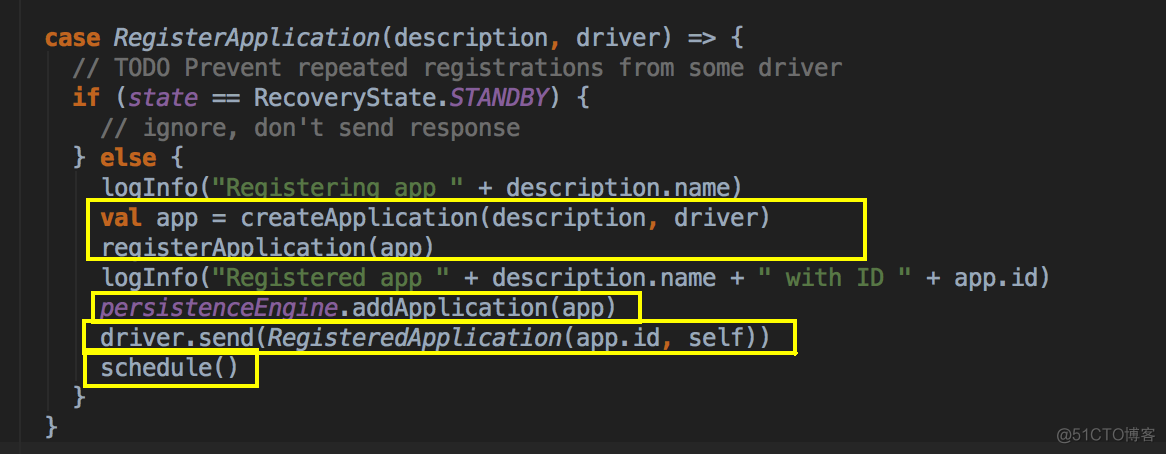


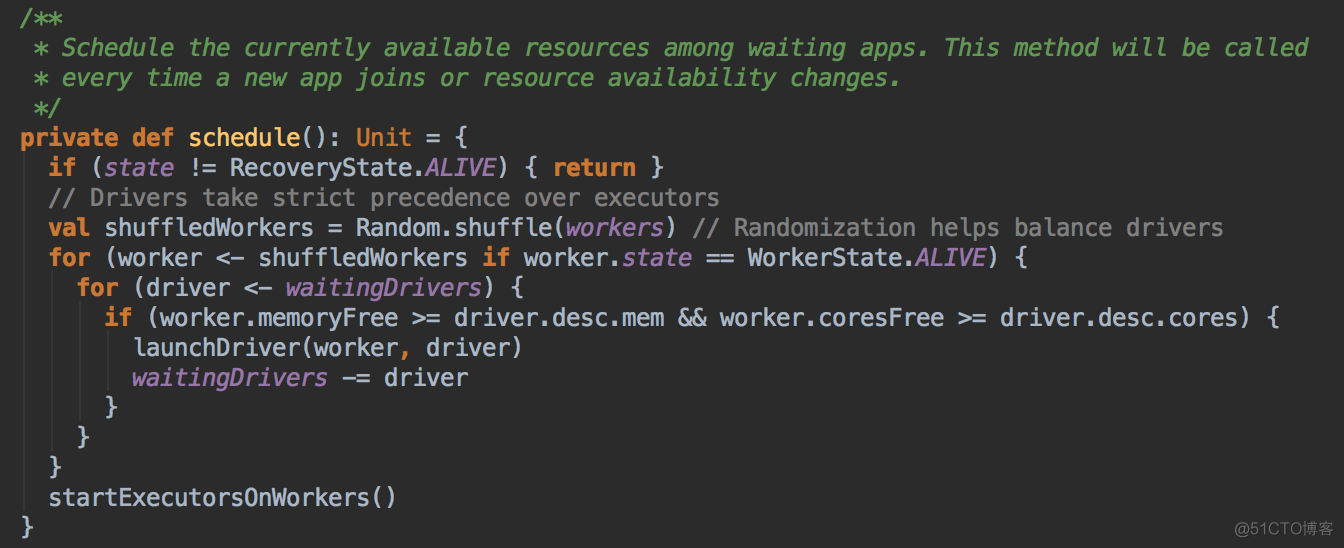

- 當前 Master 必需是 Alive 的方式才可以進行資源調度,一開始的時候會判斷一下狀態,如果不是 Alive 的狀態會直接返回,也就是 StandByMaster 不會進行 Application 的資源調用
- 使用 Random.shuffle 把 Master 中保留的集群中所有 Worker 的信息隨機打亂;其算法內部是循環隨機交換所有 Worker 在 Master 緩存的數據結構中的位置
- 接下來要判斷所有 Worker 中那些是 ALIVE 級別的 Worker 才能夠參與資源的分配工作
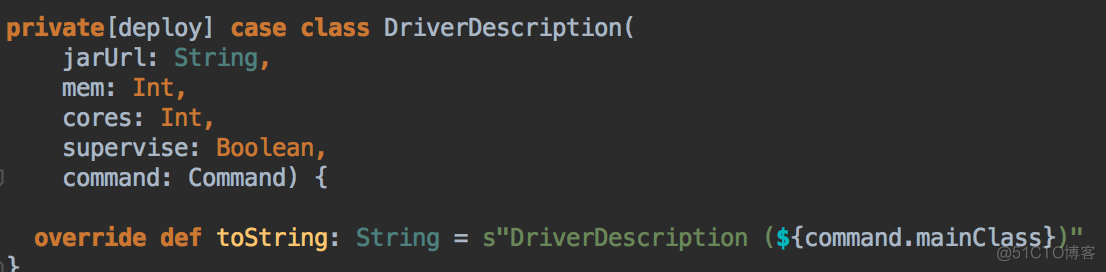
- 當 SparkSubmit 指定 Driver 在 Cluster 模式的情況下,此時 Driver 會加入 waitingDrivers 等待列表中,在每個 DriverInfo 中的 DriverDescription 中要啟動 Driver 時候對 Worker 的內存及 CPU 要求等內容:
- 在符合資源要求的情況下然後採用隨時打亂後的一個 Worker 來啟動 Driver,Master 發指令給 Worker 讓遠程的 Worker 啟動 Driver,这就可以保证负载均衡。先啟動 Driver 才會發生後續的一切的資源調度的模式

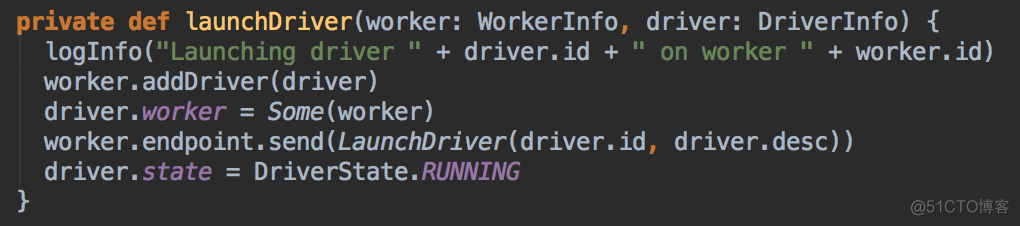
正式启动在Worker中启动Executor
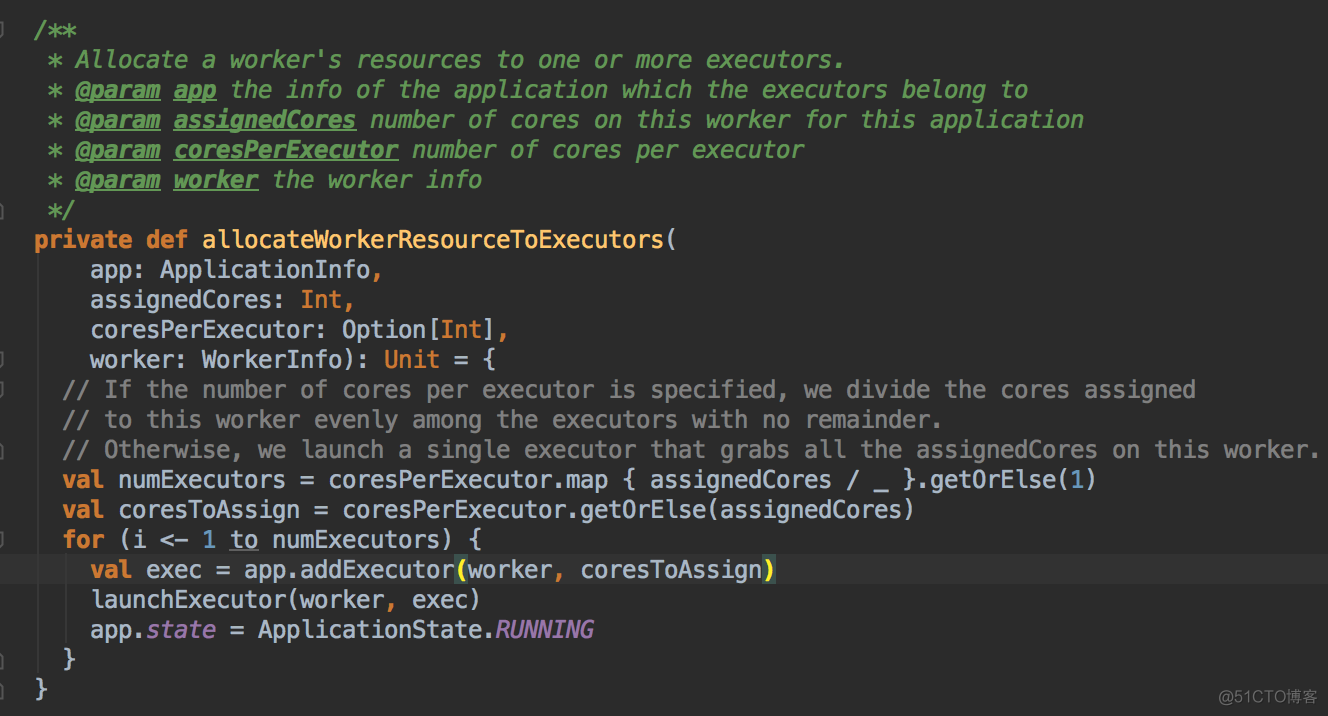
Spark 默认为应用程序启动 Executor 的方式是 FIFO 的方式,也就是說所有的提交的應用程序都是放在調度的等待隊列中的,先進先出,只有滿足了出面應用程序的分配的基础上才能夠滿足下一個應用程序資源的分配。正式启动在Worker中启动Executor:為应用程序具体分配 Executor 之前要判断应用程序是否還需要分配 Core 如果不需要則不会為应用程序分配 Executor
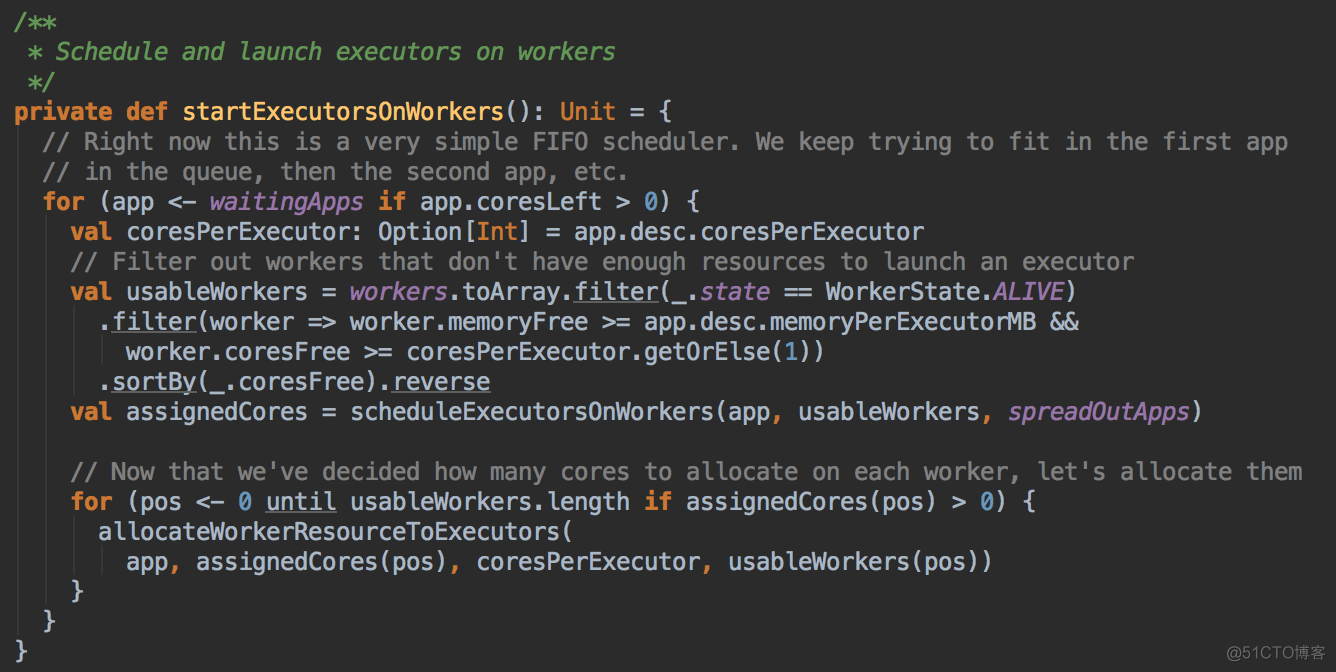
- 具體分配 Executor 之前要求 Worker 必需是 Alive 的狀態且必需滿足 Application 對每個 Executor 的內存和 Cores 的要求,並且在此基礎上進行排序,誰的 Cores 多就排在前面。計算資源由大到小的 usableWorkers 數據結構。把最好的資源放在前面。
- 在 FIFO 的情況下默認是 spreadOutApps 來讓應用程序盡可能多的運行在所有的 Node 上。
- 然后调用scheduleExecutorsOnWorkers方法,為應用程序分配 executor 有兩種情況,第一種方式是盡可能在集群的所有 Worker 上分配 Executor ,這種方式往往會帶來潛在的更好的數據本地性。具體在集群上分配 Cores 的時候會盡可能的滿足我們的要求,如果是每個 Worker 下面只能夠為當前的應用程序分配一個 Executor 的話,每次是分配一個 Core! (每次為這個 Executor 增加一個 Core)。每次給 Executor 增加的時候都是堵加一個 Core, 如果是 spreadout 的方式,循環一論下一論,假設有4個 Executors,如果 spreadout 的方式,它會在每個 Worker 中啟動一個 Executor, 第一次為每個 Executor 分配一個線程,第二次再次循環後再分配一條線程。
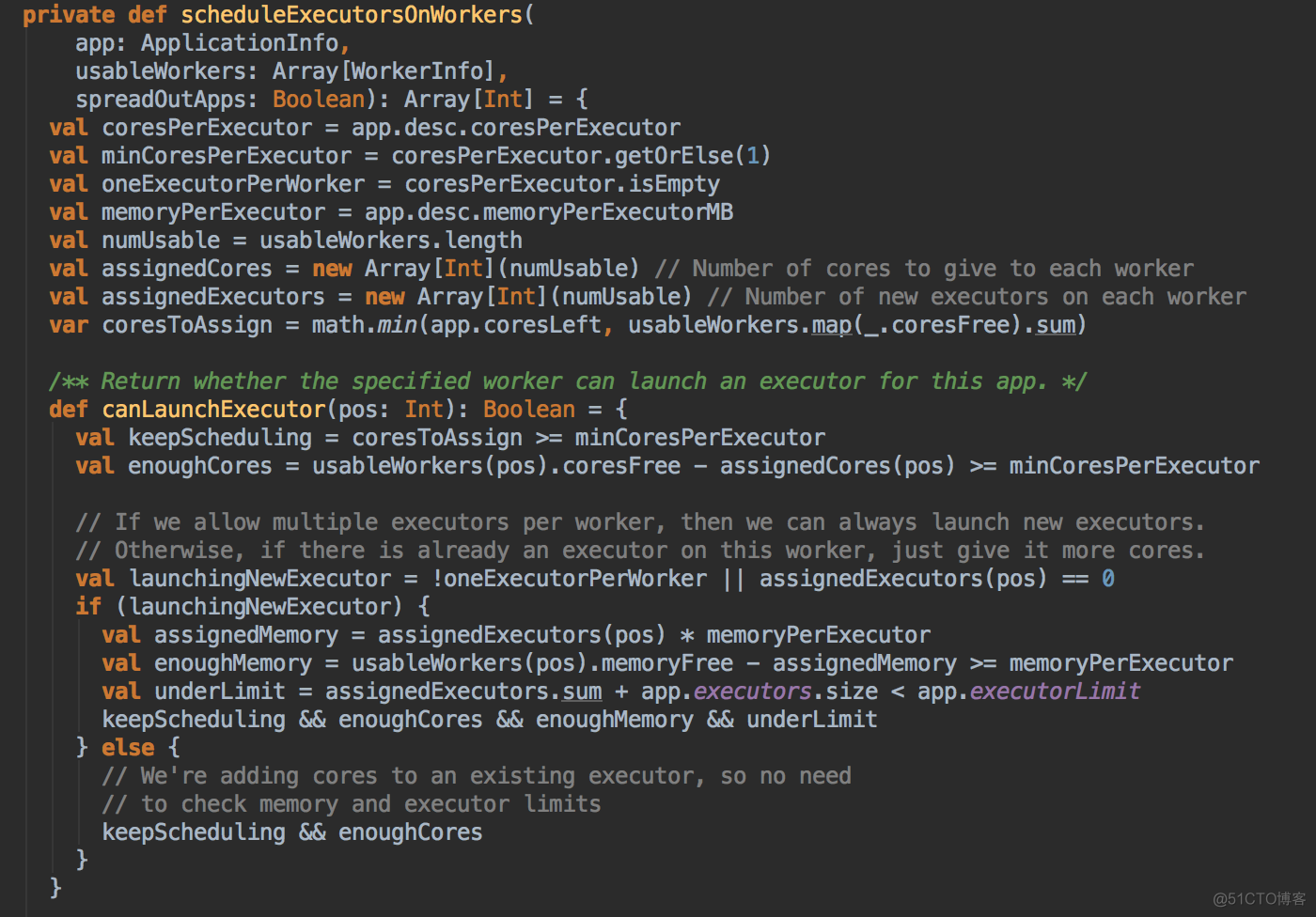
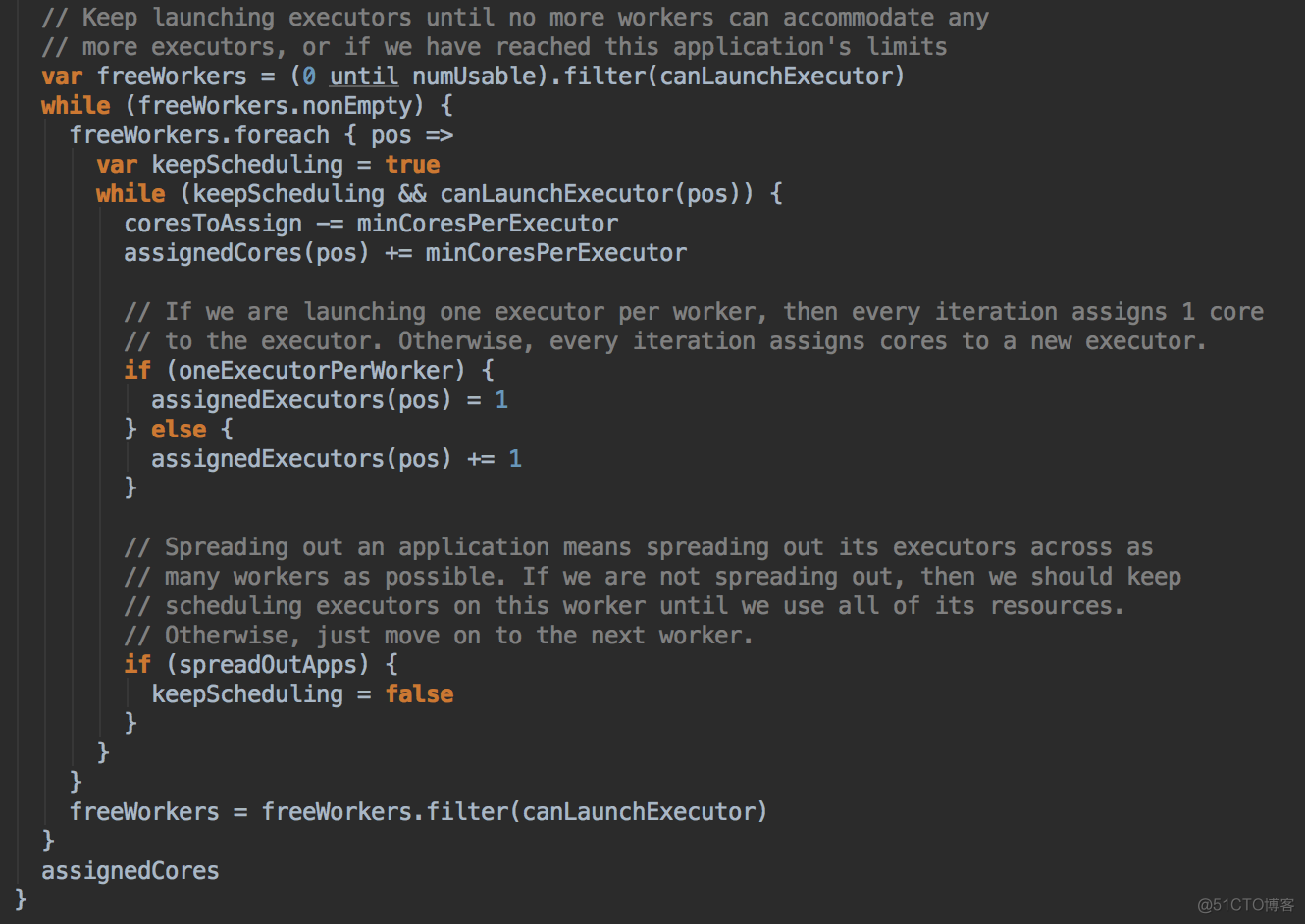
- 然后调用 allocateWorkerResourceToExecutors 方法
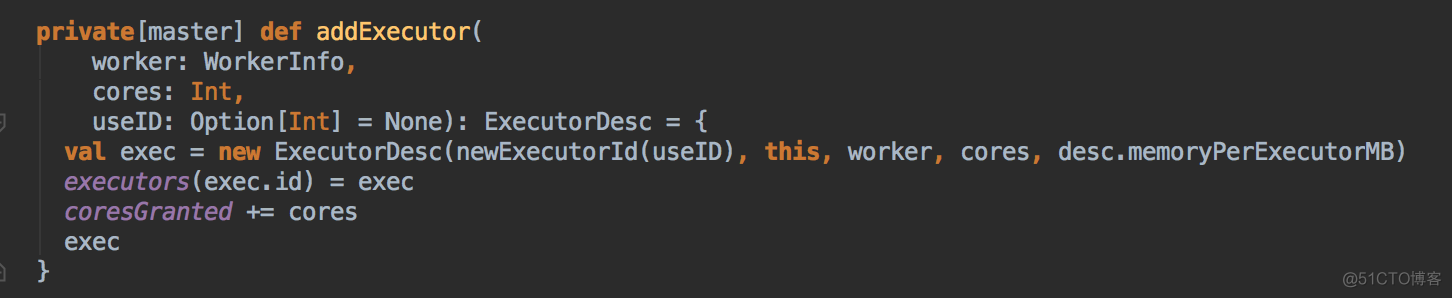
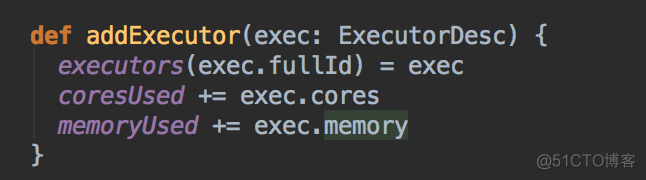
- 然后会调用 addExecutor 方法
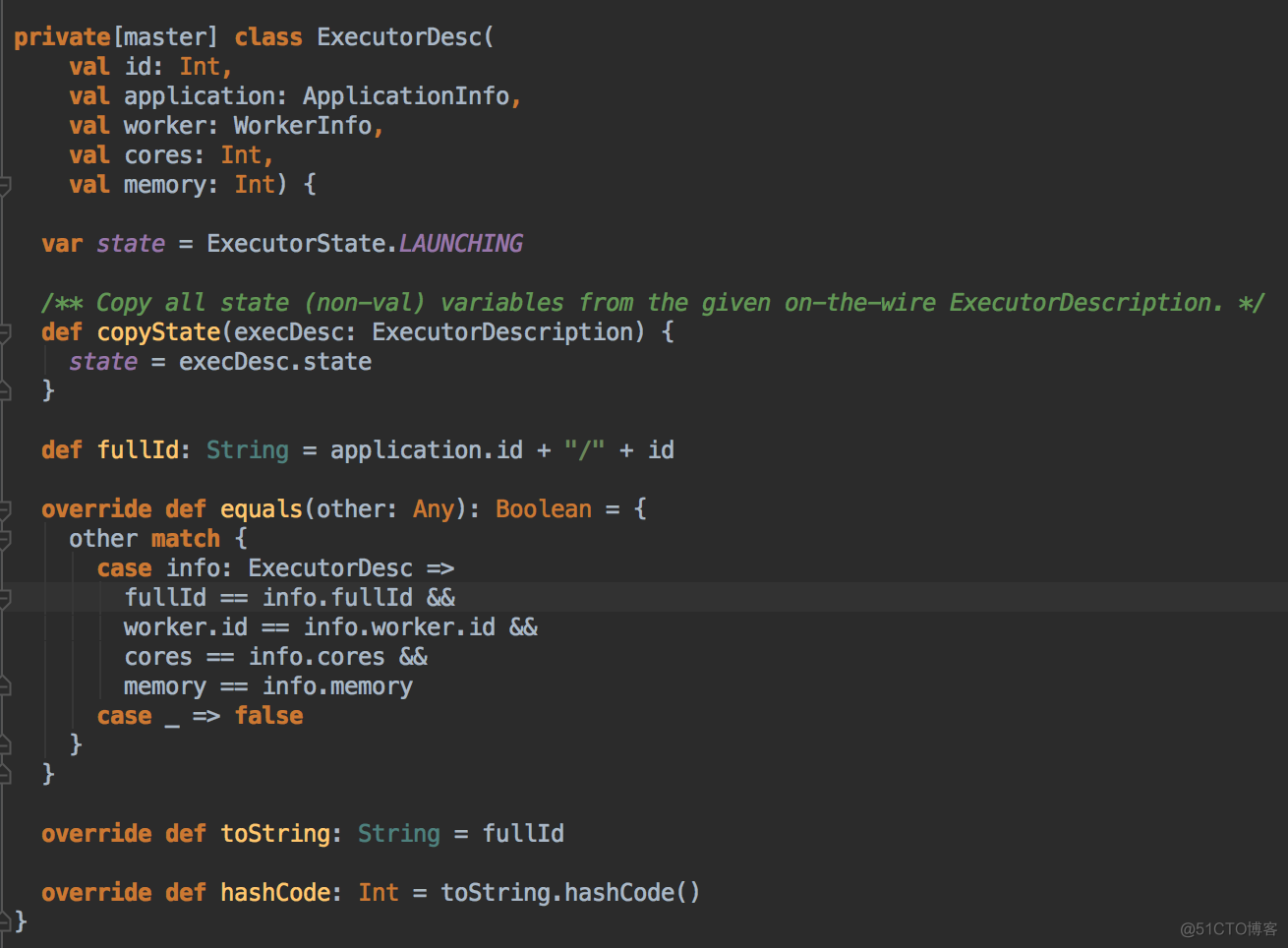
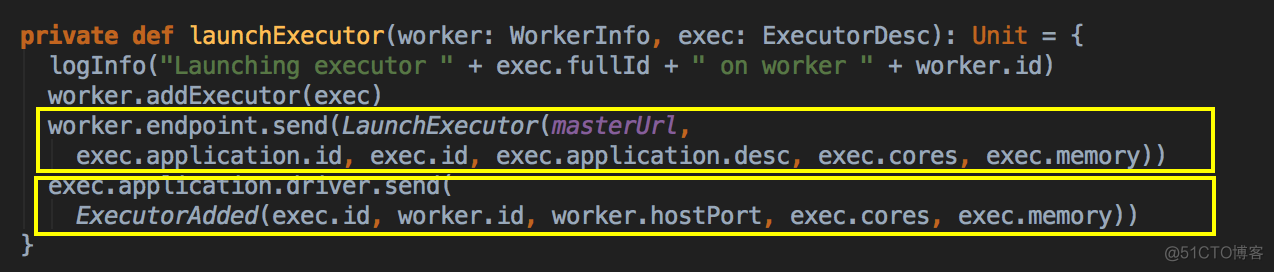
- 新增 Executor 后然后就真正的启动 Executor,準備具體要為當前應用程序分配的 Executor 信息後,Master 要通過遠程通信發指令給 Worker 來具體啟動 ExecutorBackend 進程,緊接給我們應用程序的 Driver 發送一個 ExecutorAdded 的信息。(Worker收到由Master发送LaunchExector信息之后如何处理可以参考我的下一篇博客!)
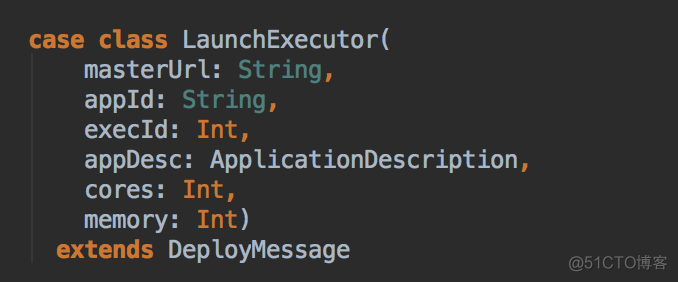
- LaunchExecutor case class 数据结构,Master 会把这个数据发送到 Worker
- Master 会把这个数据发送到 Driver