Kubernetes 同样将操作系统和 Docker 的 Volume 概念延续了下来,并且对其进一步细化。Kubernetes 将 Volume 分为持久化的 PersistentVolume 和非持久化的普通 Volume 两类。为了不与前面定义的 Volume 这个概念产生混淆,后面特指 Kubernetes 中非持久化的 Volume 时,都会带着“普通”前缀。
普通 Volume 的设计目标不是为了持久地保存数据,而是为同一个 Pod 中多个容器提供可共享的存储资源,因此 Volume 具有十分明确的生命周期——与挂载它的 Pod 相同的生命周期,这意味着尽管普通 Volume 不具备持久化的存储能力,但至少比 Pod 中运行的任何容器的存活期都更长,Pod 中不同的容器能共享相同的普通 Volume,当容器重新启动时,普通 Volume 中的数据也会能够得到保留。当然,一旦整个 Pod 被销毁,普通 Volume 也将不复存在,数据在逻辑上也会被销毁掉,至于实质上会否会真正删除数据,就取决于存储驱动具体是如何实现 Unmount、Detach、Delete 接口的。
从操作系统里传承下来的 Volume 概念,在 Docker 和 Kubernetes 中继续按照一致的逻辑延伸拓展,只不过 Kubernetes 为将其与普通 Volume 区别开来,专门取了 PersistentVolume 这个名字,你可以从下图直观地看出普通 Volume、PersistentVolume 和 Pod 之间的关系差异。
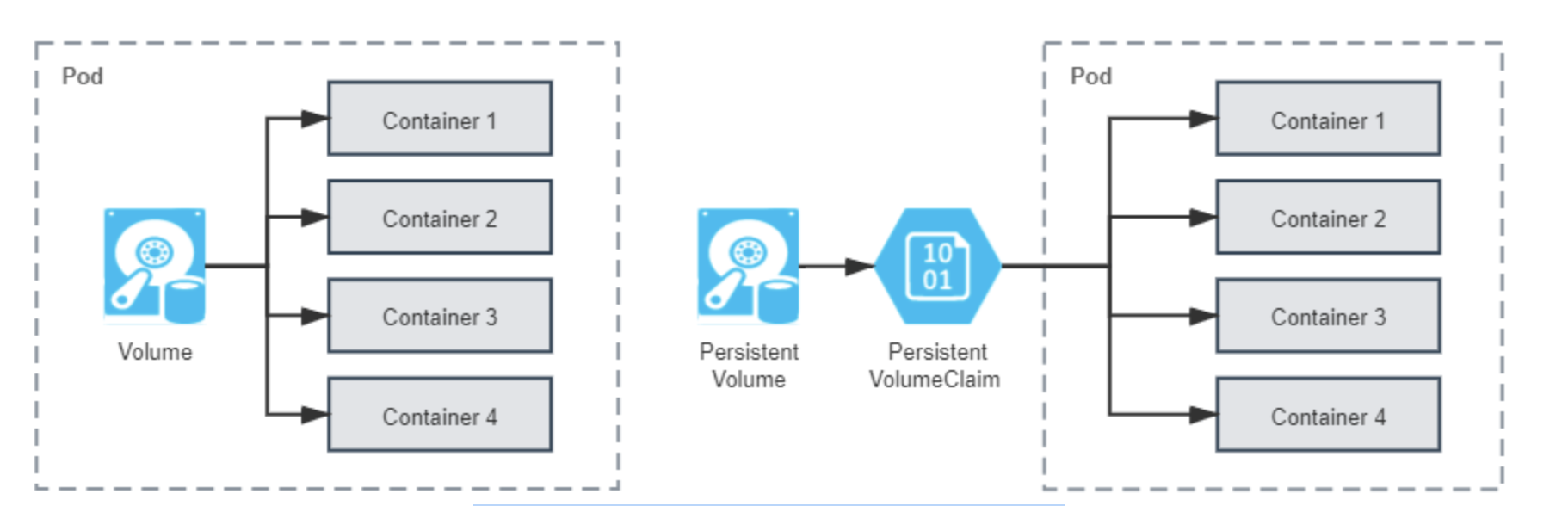
从“Persistent”这个单词就能顾名思义,PersistentVolume 是指能够将数据进行持久化存储的一种资源对象,它可以独立于 Pod 存在,生命周期与 Pod 无关,因此也决定了 PersistentVolume 不应该依附于任何一个宿主机节点,否则必然会对 Pod 调度产生干扰限制。
将 PersistentVolume 与 Pod 分离后,便需要专门考虑 PersistentVolume 该如何被 Pod 所引用的问题。原本在 Pod 中引用其他资源是常有的事,要么直接通过资源名称直接引用,要么通过标签选择器(Selectors)间接引用。但是这种方法在这里却不太妥当。那应该是系统管理员(运维人员)说的算,还是由用户(开发人员)说的算?最合理的答案是他们一起说的才算,因为只有开发能准确评估 Pod 运行需要消耗多大的存储空间,只有运维能清楚知道当前系统可以使用的存储设备状况,为了让他们得以各自提供自己擅长的信息,Kubernetes 又额外设计出了 PersistentVolumeClaim 资源。Kubernetes 官方给出的概念定义也特别强调了 PersistentVolume 是由管理员(运维人员)负责维护的,用户(开发人员)通过 PersistentVolumeClaim 来匹配到合乎需求的 PersistentVolume。
PersistentVolume & PersistentVolumeClaim
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator.
A PersistentVolumeClaim (PVC) is a request for storage by a user.
PersistentVolume 是由管理员负责提供的集群存储。
PersistentVolumeClaim 是由用户负责提供的存储请求。
PersistentVolume 是 Volume 这个抽象概念的具象化表现,通俗地说就它是已经被管理员分配好的具体的存储,这里的“具体”是指有明确的存储系统地址,有明确的容量、访问模式、存储位置等信息;而 PersistentVolumeClaim 则是 Pod 对其所需存储能力的声明,通俗地说就是满足这个 Pod 正常运行要满足怎样的条件,譬如要消耗多大的存储空间、要支持怎样的访问方式。因此两者并不是谁引用谁的固定关系,而是根据实际情况动态匹配的,两者配合工作的具体过程如下。
- 管理员准备好要使用的存储系统,它应是某种网络文件系统(NFS)或者云储存系统,一般来说应该具备跨主机共享的能力。
- 管理员根据存储系统的实际情况,手工预先分配好若干个 PersistentVolume,并定义好每个 PersistentVolume 可以提供的具体能力。譬如以下例子所示:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nginx-html
spec:
capacity:
storage: 5Gi # 最大容量为5GB
accessModes:
- ReadWriteOnce # 访问模式为RWO
persistentVolumeReclaimPolicy: Retain # 回收策略是Retain
nfs: # 存储驱动是NFS
path: /html
server: 172.16.10.10
以上 YAML 中定义的存储能力具体为:
- 存储的最大容量是 5GB。
- 存储的访问模式是“只能被一个节点读写挂载”(ReadWriteOnce,RWO),另外两种可选的访问模式是“可以被多个节点以只读方式挂载”(ReadOnlyMany,ROX)和“可以被多个节点读写挂载”(ReadWriteMany,RWX)。
- 存储的回收策略是 Retain,即在 Pod 被销毁时并不会删除数据。另外两种可选的回收策略分别是 Recycle ,即在 Pod 被销毁时,由 Kubernetes 自动执行rm -rf /volume/*这样的命令来自动删除资料;以及 Delete,它让 Kubernetes 自动调用 AWS EBS、GCE PersistentDisk、OpenStack Cinder 这些云存储的删除指令。
- 存储驱动是 NFS,其他常见的存储驱动还有 AWS EBS、GCE PD、iSCSI、RBD(Ceph Block Device)、GlusterFS、HostPath,等等。
- 用户根据业务系统的实际情况,创建 PersistentVolumeClaim,声明 Pod 运行所需的存储能力。譬如以下例子所示:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-html-claim
spec:
accessModes:
- ReadWriteOnce # 支持RWO访问模式
resources:
requests:
storage: 5Gi # 最小容量5GB
# 以上 YAML 中声明了要求容量不得小于 5GB,必须支持 RWO 的访问模式。
-
Kubernetes 创建 Pod 的过程中,会根据系统中 PersistentVolume 与 PersistentVolumeClaim 的供需关系对两者进行撮合,如果系统中存在满足 PersistentVolumeClaim 声明中要求能力的 PersistentVolume 则撮合成功,将它们绑定。如果撮合不成功,Pod 就不会被继续创建,直至系统中出现新的或让出空闲的 PersistentVolume 资源。
-
以上几步都顺利完成的话,意味着 Pod 的存储需求得到满足,继续 Pod 的创建过程,整个过程如下图:
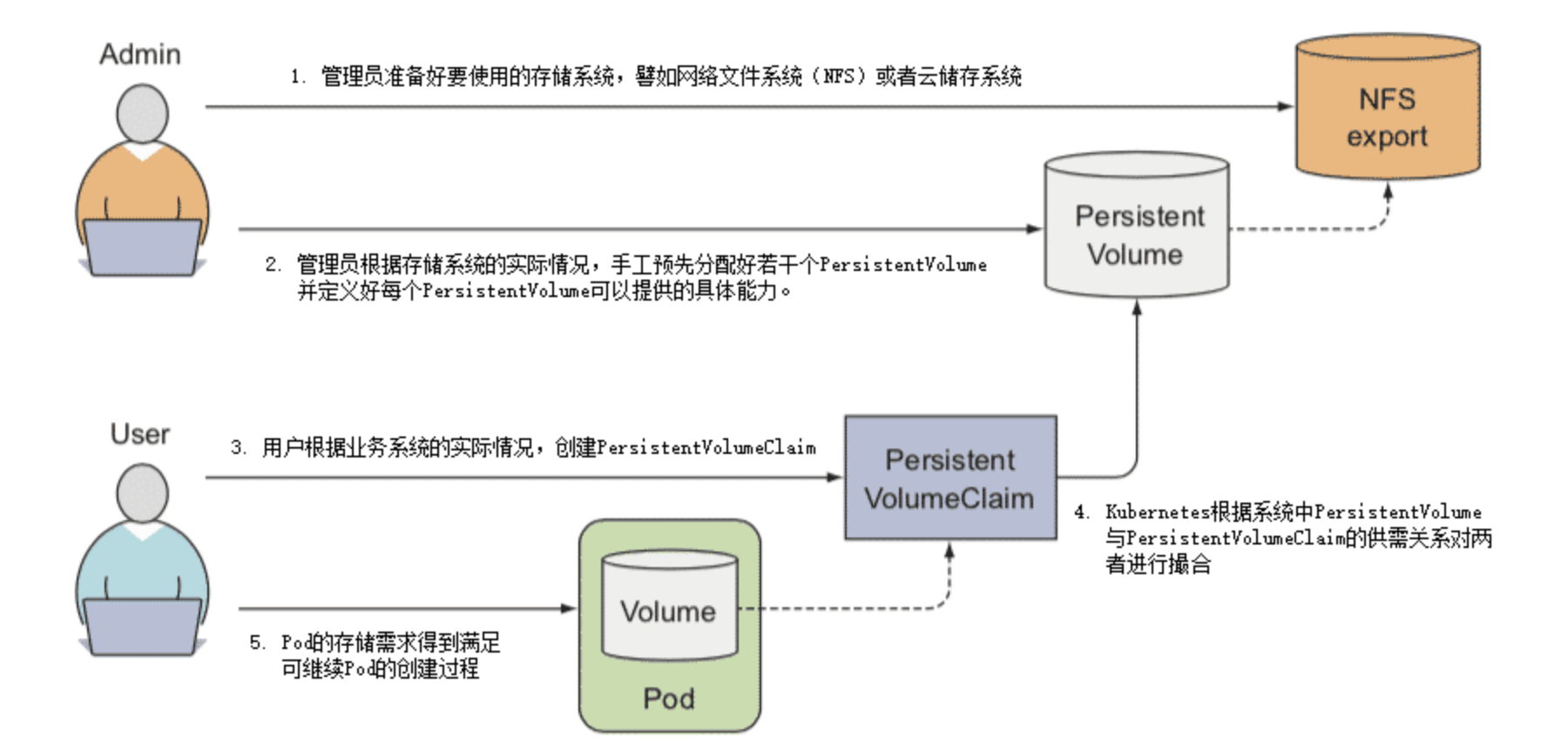
Kubernetes 对 PersistentVolumeClaim 与 PersistentVolume 撮合的结果是产生一对一的绑定关系,“一对一”的意思是 PersistentVolume 一旦绑定在某个 PersistentVolumeClaim 上,直到释放以前都会被这个 PersistentVolumeClaim 所独占,不能再与其他 PersistentVolumeClaim 进行绑定。这意味着即使 PersistentVolumeClaim 申请的存储空间比 PersistentVolume 能够提供的要少,依然要求整个存储空间都为该 PersistentVolumeClaim 所用,这有可能会造成资源的浪费。譬如,某个 PersistentVolumeClaim 要求 3GB 的存储容量,当前 Kubernetes 手上只剩下一个 5GB 的 PersistentVolume 了,此时 Kubernetes 只好将这个 PersistentVolume 与申请资源的 PersistentVolumeClaim 进行绑定,平白浪费了 2GB 空间。假设后续有另一个 PersistentVolumeClaim 申请 2GB 的存储空间,那它也只能等待管理员分配新的 PersistentVolume,或者有其他 PersistentVolume 被回收之后才被能成功分配。
动态存储对于中小规模的 Kubernetes 集群,PersistentVolume 已经能够满足有状态应用的存储需求,PersistentVolume 依靠人工介入来分配空间的设计算是简单直观,却算不上是先进,一旦应用规模增大,PersistentVolume 很难被自动化的问题就会突显出来。这是由于 Pod 创建过程中去挂载某个 Volume,要求该 Volume 必须是真实存在的,否则 Pod 启动可能依赖的数据(如一些配置、数据、外部资源等)都将无从读取。Kubernetes 有能力随着流量压力和硬件资源状况,自动扩缩 Pod 的数量,但是当 Kubernetes 自动扩展出一个新的 Pod 后,并没有办法让 Pod 去自动挂载一个还未被分配资源的 PersistentVolume。想解决这个问题,要么允许多个不同的 Pod 都共用相同的 PersistentVolumeClaim,这种方案确实只靠PersistentVolume 就能解决,却损失了隔离性,难以通用;要么就要求每个 Pod 用到的 PersistentVolume 都是已经被预先建立并分配好的,这种方案靠管理员提前手工分配好大量的存储也可以实现,却损失了自动化能力。
无论哪种情况,都难以符合 Kubernetes 工业级编排系统的产品定位,对于大型集群,面对成百上千,乃至成千上万的 Pod,靠管理员手工分配存储肯定是捉襟见肘疲于应付的。在 2017 年 Kubernetes 发布 1.6 版本后,终于提供了今天被称为动态存储分配(Dynamic Provisioning)的解决方案,让系统管理员摆脱了人工分配的 PersistentVolume 的窘境,与之相对,人们把此前的分配方式称为静态存储分配(Static Provisioning)。
所谓的动态存储分配方案,是指在用户声明存储能力的需求时,不是通过 Kubernetes 管理员人工预置或者是创建的 PersistentVolume,而是由特定的资源分配器(Provisioner)自动地在存储资源池或者云存储系统中分配符合用户存储需要的 PersistentVolume,然后挂载到 Pod 中使用,完成这项工作的资源被命名为 StorageClass,它的具体工作过程如下:
- 管理员根据存储系统的实际情况,先准备好对应的 Provisioner。Kubernetes 官方已经提供了一系列预置的 In-Tree Provisioner,放置在kubernetes.io的 API 组之下。其中部分 Provisioner 已经有了官方的 CSI 驱动,比如 vSphere 的 Kubernetes 自带驱动为kubernetes.io/vsphere-volume,VMware 的官方驱动为csi.vsphere.vmware.com。
- 管理员不再是手工去分配 PersistentVolume,而是根据存储去配置 StorageClass。Pod 是可以动态扩缩的,而存储则是相对固定的,哪怕使用的是具有扩展能力的云存储,也会将它们视为存储容量、IOPS 等参数可变的固定存储来看待,譬如你可以将来自不同云存储提供商、不同性能、支持不同访问模式的存储配置为各种类型的 StorageClass,这也是它名字中“Class”(类型)的由来,譬如以下例子所示:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs #AWS EBS的Provisioner
parameters:
type: gp2
reclaimPolicy: Retain
- 用户依然通过 PersistentVolumeClaim 来声明所需的存储,但是应在声明中明确指出该由哪个 StorageClass 来代替 Kubernetes 处理该 PersistentVolumeClaim 的请求,譬如以下例子所示:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: standard-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard #明确指出该由哪个StorageClass来处理该PersistentVolumeClaim的请求
resource:
requests:
storage: 5Gi
- 如果 PersistentVolumeClaim 中要求的 StorageClass 及它用到的 Provisioner 均是可用的话,那这个 StorageClass 就会接管掉原本由 Kubernetes 撮合 PersistentVolume 与 PersistentVolumeClaim 的操作,按照 PersistentVolumeClaim 中声明的存储需求,自动产生出满足该需求的 PersistentVolume 描述信息,并发送给 Provisioner 处理。
- Provisioner 接收到 StorageClass 发来的创建 PersistentVolume 请求后,会操作其背后存储系统去分配空间,如果分配成功,就生成并返回符合要求的 PersistentVolume 给 Pod 使用。
- 以上几步都顺利完成的话,意味着 Pod 的存储需求得到满足,继续 Pod 的创建过程,整个过程如下图所示。
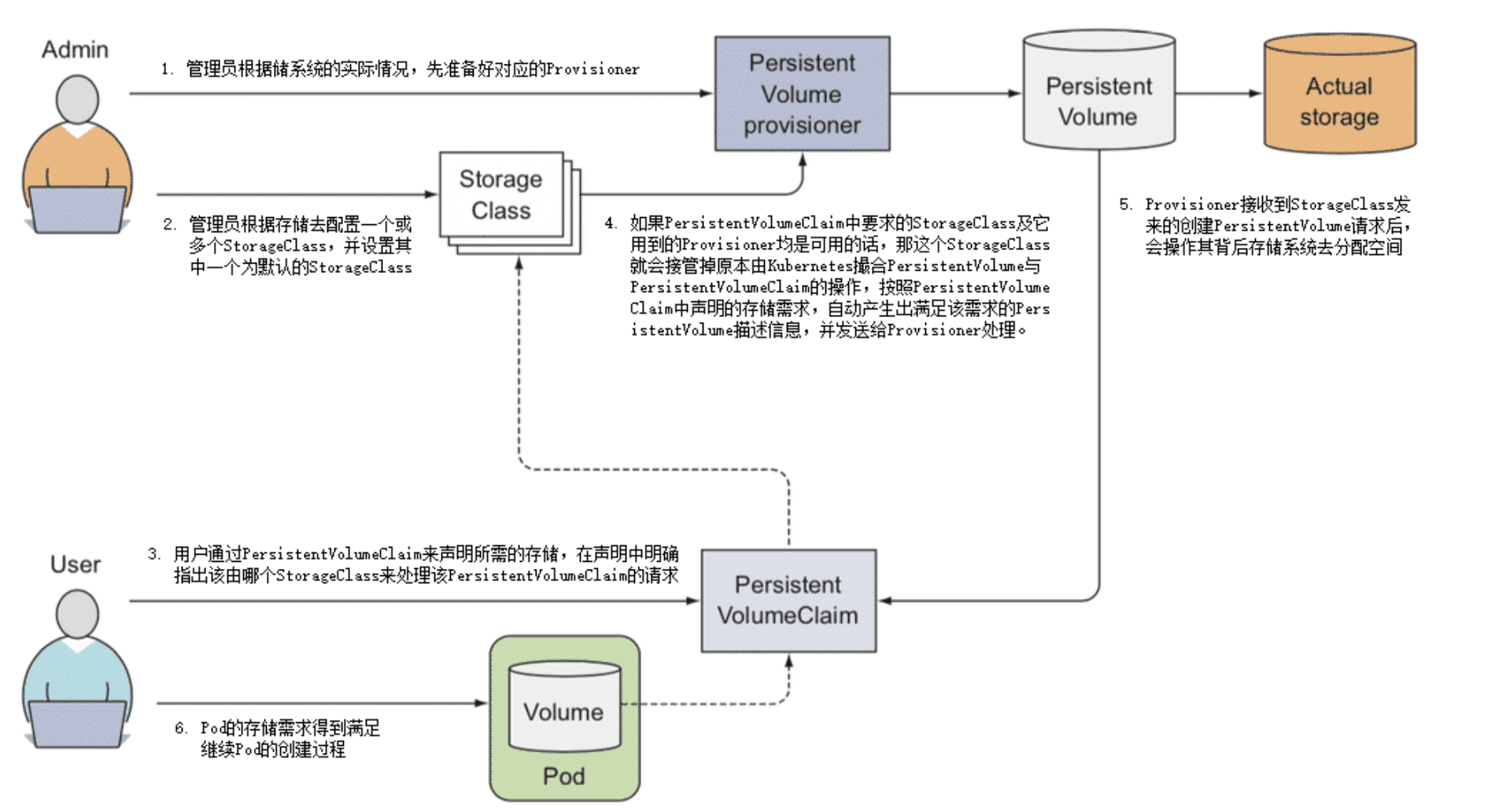
使用 Dynamic Provisioning 来分配存储无疑是更合理的设计,不仅省去了管理员的人工操作的中间层,也不再需要将 PersistentVolume 这样的概念暴露给最终用户,因为 Dynamic Provisioning 里的 PersistentVolume 只是处理过程的中间产物,用户不再需要接触和理解它,只需要知道由 PersistentVolumeClaim 去描述存储需求,由 StorageClass 去满足存储需求即可。只描述意图而不关心中间具体的处理过程是声明式编程的精髓,也是流程自动化的必要基础。
由 Dynamic Provisioning 来分配存储还能获得更高的可管理性,譬如前面提到的回收策略,当希望 PersistentVolume 跟随 Pod 一同被销毁时,以前经常会配置回收策略为 Recycle 来回收空间,即让系统自动执行rm -rf /volume/*命令,这种方式往往过于粗暴,遇到更精细的管理需求,譬如“删除到回收站”或者“敏感信息粉碎式彻底删除”这样的功能实现起来就很麻烦。而 Dynamic Provisioning 中由于有 Provisioner 的存在,如何创建、如何回收都是由 Provisioner 的代码所管理的,这就带来了更高的灵活性。现在 Kubernetes 官方已经明确建议废弃掉 Recycle 策略,如有这类需求就应改由 Dynamic Provisioning 去实现了。
Static Provisioning 的主要使用场景已局限于管理员能够手工管理存储的小型集群,它符合很多小型系统,尤其是私有化部署系统的现状,但并不符合当今运维自动化所提倡的思路。Static Provisioning 的存在,某种意义上也可以视为是对历史的一种兼容,在可见的将来,Kubernetes 肯定仍会把 Static Provisioning 作为用户分配存储的一种主要方案供用户选用。
参考文献来自凤凰架构