原文链接:当我们在聊「开源大数据调度系统Taier」的数据开发功能时,到底在讨论什么?
课件获取:关注公众号__ “数栈研习社”,后台私信 “Taier”__ 获得直播课件
视频回放:点击这里
Taier 开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下摘月同学的直播分享《Taier数据开发介绍》
之前三期内容,我们为大家分享了Taier入门、控制台以及Web前端架构的介绍。本次分享我们将从Taier的数据开发功能,到任务运行、功能可扩展点以及未来规划为大家进行讲解。
一、数据开发功能介绍Taier 是袋鼠云开源项目之一,是一个分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,Taier的数据开发功能主要分为以下三种:
1、资源管理资源管理通常使用在UDF等自定义函数的场景中,也可以在任务开发中使用。在Taier中,对于函数引用,主要用在Spark、Flink自定义函数中,而在任务引用中,则主要用于Flink任务。

自定义函数处理流程如下图所示:
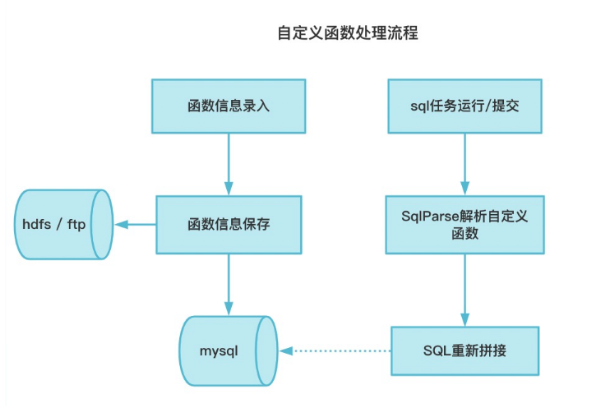
函数管理在Taier中的具体实现主要包括以下两个方面:
-
基于calcite完成不同数据源SQL自定义函数解析
-
使用SQL运行前创建临时函数替代创建永久函数,使函数使用更加灵活
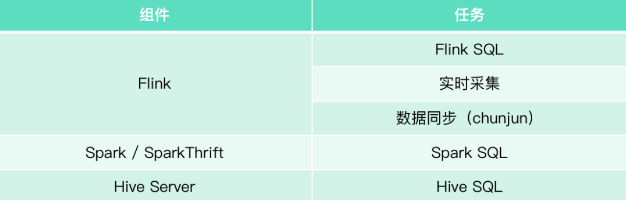
Taier现支持任务:Flink SQL、实时采集、数据同步(ChunJun)、Spark SQL、HiveSQL
Taier中有两块区分,分别为集群和数据开发,如果想在Taier中跑一个任务,需要先在集群中进行配置,具体组件与任务关系如下图:
了解完Taier数据开发的功能介绍后,我们来为大家分享Taier的任务运行逻辑。
1、Spark Sql、Hive Sql临时运行流程Spark Sql、Hive Sql 临时运行流程主要分为任务编写、SQL处理、SQL执行三步,以下图为SparkSql执行流程:
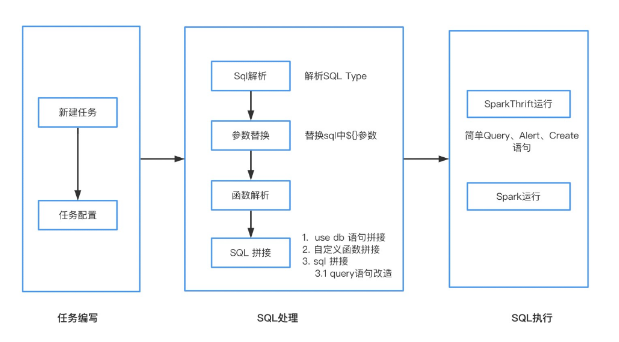
Spark Sql 、Hive Sql 运行依赖主要包括以下两类:
● Sql解析(基于calcite进行)
· Sql Type 解析
· 函数、表名解析
● 数据源插件
· 统一不同数据源操作入口
· 封装数据源对应的数据操作方法
三、功能可扩展点介绍当前而言,Taier中的功能还较为简单,只开放了主要流程的功能,在开源中还有许多可扩展点,接下来为大家介绍Taier的功能可扩展点。
1、功能扩展——数据权限控制在sparkThrift、hiveserver中去进行create、insert into、alter、select时,不同的公司、不同的人有不一样的数据权限控制,面对这种情况,可以利用Apache Ranger大数据权限管理框架进行权限配置。
具体地址为:
github:https://github.com/ranger/ranger
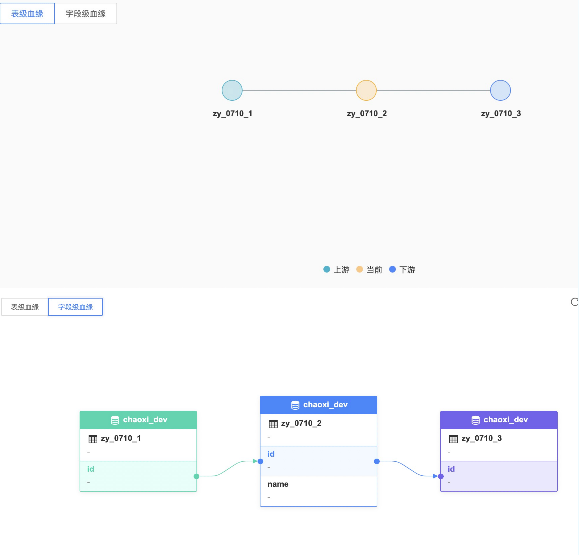
2、功能扩展——数据血源追踪通过SQL解析可以得到表和表之间的关系,以及不同表中字段之间的血源关系。
● 实现工具:calcite
● 可操作任务:SparkSql、HiveSql、数据同步(ChunJun)
用sql举例:
create table zy_0710_1 (id int, name string);
create table zy_0710_2 as select id , name from zy_0710_1;
create table zy_0710_3 as select id , name from zy_0710_2;
最后为大家介绍未来不久将发布的Taier1.2新版本尝鲜:
●集群管理
控制台ui升级
● 数据开发
-
集群租户绑定流程简化
-
任务开发代码层面优化
-
任务新增schema配置
● 新增功能
-
FlinkSql支持jar包方式
-
新增工作流任务
-
自定义扩展开发任务
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
【文章原创作者:香港服务器 http://www.558idc.com/hk.html提供,感谢支持】