本文实例讲述了大数据java spark编程。分享给大家供大家参考,具体如下:
上节搭建好了eclipse spark编程环境
在测试运行scala 或java 编写spark程序 ,在eclipse平台都可以运行,但打包导出jar,提交 spark-submit运行,都不能执行,最后确定是版本问题,就是你在eclipse调试的spark版本需和spark-submit 提交spark的运行版本一致,还有就是scala版本一致,才能正常运行。
以下是java spark程序运行
1.新建maven项目 SparkApps

注意 pom.xml 中spark-core 的版本
我原来调试使用的是
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.0</version> </dependency>
打包成jar到提交 spark-submit 运行,总是提示错误,因为spark下载的是spark-1.6.0-cdh5.16.0版本的,与eclipse中spark2.4.0版本有些语句用法不一致。
2. 项目中新建类JavaWordCount
package com.linbin.SparkApps;
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.regex.Pattern;
public class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
// setMaster 在打包导出时无需设定
sparkConf.setMaster("local[2]");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
/* 以下spark2.X
*
* public Iterator<String> call(String s) {
* return (Arrays.asList(SPACE.split(s)).iterator();
* }
*/
// 以下spark1.X
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(SPACE.split(s));
}
});
JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
ctx.close();
}
}
3. 在eclipse中运行 as “java Application”

正常输出结果
4. Eclipse中打包导出为 sparkapps.jar
5. 提交给spark中执行
[root@centos7 bin]# ./spark-submit --master spark://centos7:7077 --class com.linbin.SparkApps.JavaWordCount /home/linbin/workspace/sparkapps.jar hdfs://centos7:8020/hello.txt
6. 执行结果,正常输出
[root@centos7 bin]# ./spark-submit --master spark://centos7:7077 --class com.linbin.SparkApps.JavaWordCount /home/linbin/workspace/sparkapps.jar hdfs://centos7:8020/hello.txt
18/11/29 14:37:38 INFO spark.SparkContext: Running Spark version 1.6.0
18/11/29 14:37:39 INFO spark.SecurityManager: Changing view acls to: root
18/11/29 14:37:39 INFO spark.SecurityManager: Changing modify acls to: root
18/11/29 14:37:39 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
18/11/29 14:37:39 INFO util.Utils: Successfully started service 'sparkDriver' on port 40507.
18/11/29 14:37:39 INFO slf4j.Slf4jLogger: Slf4jLogger started
18/11/29 14:37:39 INFO Remoting: Starting remoting
18/11/29 14:37:39 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@172.16.48.71:35776]
18/11/29 14:37:39 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriverActorSystem@172.16.48.71:35776]
18/11/29 14:37:39 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 35776.
18/11/29 14:37:39 INFO spark.SparkEnv: Registering MapOutputTracker
18/11/29 14:37:39 INFO spark.SparkEnv: Registering BlockManagerMaster
18/11/29 14:37:39 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-dd9c0da7-1d22-45ba-9f9d-05d027801ccc
18/11/29 14:37:39 INFO storage.MemoryStore: MemoryStore started with capacity 530.0 MB
18/11/29 14:37:39 INFO spark.SparkEnv: Registering OutputCommitCoordinator
18/11/29 14:37:39 INFO server.Server: jetty-8.y.z-SNAPSHOT
18/11/29 14:37:39 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
18/11/29 14:37:39 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
18/11/29 14:37:39 INFO ui.SparkUI: Started SparkUI at http://172.16.48.71:4040
18/11/29 14:37:39 INFO spark.SparkContext: Added JAR file:/home/linbin/workspace/sparkapps.jar at spark://172.16.48.71:40507/jars/sparkapps.jar with timestamp 1543473459974
18/11/29 14:37:40 INFO client.AppClient$ClientEndpoint: Connecting to master spark://centos7:7077...
18/11/29 14:37:40 INFO cluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20181129143740-0003
18/11/29 14:37:40 INFO client.AppClient$ClientEndpoint: Executor added: app-20181129143740-0003/0 on worker-20181129113634-172.16.48.71-34880 (172.16.48.71:34880) with 2 cores
18/11/29 14:37:40 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20181129143740-0003/0 on hostPort 172.16.48.71:34880 with 2 cores, 1024.0 MB RAM
18/11/29 14:37:40 INFO client.AppClient$ClientEndpoint: Executor updated: app-20181129143740-0003/0 is now RUNNING
18/11/29 14:37:40 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 40438.
18/11/29 14:37:40 INFO netty.NettyBlockTransferService: Server created on 40438
18/11/29 14:37:40 INFO storage.BlockManagerMaster: Trying to register BlockManager
18/11/29 14:37:40 INFO storage.BlockManagerMasterEndpoint: Registering block manager 172.16.48.71:40438 with 530.0 MB RAM, BlockManagerId(driver, 172.16.48.71, 40438)
18/11/29 14:37:40 INFO storage.BlockManagerMaster: Registered BlockManager
18/11/29 14:37:40 INFO cluster.SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
18/11/29 14:37:40 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 156.5 KB, free 529.9 MB)
18/11/29 14:37:40 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 16.5 KB, free 529.8 MB)
18/11/29 14:37:40 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.16.48.71:40438 (size: 16.5 KB, free: 530.0 MB)
18/11/29 14:37:40 INFO spark.SparkContext: Created broadcast 0 from textFile at JavaWordCount.java:45
18/11/29 14:37:41 INFO mapred.FileInputFormat: Total input paths to process : 1
18/11/29 14:37:41 INFO spark.SparkContext: Starting job: collect at JavaWordCount.java:103
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Registering RDD 3 (mapToPair at JavaWordCount.java:73)
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Got job 0 (collect at JavaWordCount.java:103) with 1 output partitions
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Final stage: ResultStage 1 (collect at JavaWordCount.java:103)
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0)
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at JavaWordCount.java:73), which has no missing parents
18/11/29 14:37:41 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.8 KB, free 529.8 MB)
18/11/29 14:37:41 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.7 KB, free 529.8 MB)
18/11/29 14:37:41 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on 172.16.48.71:40438 (size: 2.7 KB, free: 530.0 MB)
18/11/29 14:37:41 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1004
18/11/29 14:37:41 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at JavaWordCount.java:73) (first 15 tasks are for partitions Vector(0))
18/11/29 14:37:41 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
18/11/29 14:37:41 INFO cluster.SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (centos7:35702) with ID 0
18/11/29 14:37:41 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, centos7, executor 0, partition 0, NODE_LOCAL, 2175 bytes)
18/11/29 14:37:41 INFO storage.BlockManagerMasterEndpoint: Registering block manager centos7:34022 with 530.0 MB RAM, BlockManagerId(0, centos7, 34022)
18/11/29 14:37:42 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on centos7:34022 (size: 2.7 KB, free: 530.0 MB)
18/11/29 14:37:42 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on centos7:34022 (size: 16.5 KB, free: 530.0 MB)
18/11/29 14:37:42 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1146 ms on centos7 (executor 0) (1/1)
18/11/29 14:37:42 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
18/11/29 14:37:42 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (mapToPair at JavaWordCount.java:73) finished in 1.445 s
18/11/29 14:37:42 INFO scheduler.DAGScheduler: looking for newly runnable stages
18/11/29 14:37:42 INFO scheduler.DAGScheduler: running: Set()
18/11/29 14:37:42 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 1)
18/11/29 14:37:42 INFO scheduler.DAGScheduler: failed: Set()
18/11/29 14:37:42 INFO scheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at JavaWordCount.java:90), which has no missing parents
18/11/29 14:37:42 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.9 KB, free 529.8 MB)
18/11/29 14:37:42 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1754.0 B, free 529.8 MB)
18/11/29 14:37:42 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 172.16.48.71:40438 (size: 1754.0 B, free: 530.0 MB)
18/11/29 14:37:42 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1004
18/11/29 14:37:42 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at JavaWordCount.java:90) (first 15 tasks are for partitions Vector(0))
18/11/29 14:37:42 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
18/11/29 14:37:42 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, centos7, executor 0, partition 0, NODE_LOCAL, 1949 bytes)
18/11/29 14:37:42 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on centos7:34022 (size: 1754.0 B, free: 530.0 MB)
18/11/29 14:37:42 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to centos7:35702
18/11/29 14:37:42 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 137 bytes
18/11/29 14:37:42 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 70 ms on centos7 (executor 0) (1/1)
18/11/29 14:37:42 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
18/11/29 14:37:42 INFO scheduler.DAGScheduler: ResultStage 1 (collect at JavaWordCount.java:103) finished in 0.074 s
18/11/29 14:37:42 INFO scheduler.DAGScheduler: Job 0 finished: collect at JavaWordCount.java:103, took 1.603764 s
went: 1
driver: 1
The: 3
hitting: 1
road,: 1
avoid: 1
colorful: 1
had: 1
highway,: 1
basket: 1
across: 1
guilty: 1
A: 1
blissfully: 1
Easter: 1
he: 1
in: 1
eggs: 1
dead.: 1
side: 1
cry.: 1
over: 2
Bunny,: 1
Much: 1
along: 1
unfortunately: 1
man: 2
what: 1
out: 1
felt: 1
lover,: 1
swerved2: 1
well: 1
road.: 1
the: 12
got: 1
his: 2
He: 1
hit.: 1
began: 1
animal: 1
was: 3
front: 1
a: 1
rabbit: 1
when: 1
sensitive: 1
pulled: 1
car: 1
all: 1
carrying: 1
to: 5
driver,: 1
as: 2
: 1
hopping1: 1
see: 1
of: 5
driving: 1
become: 1
basket.: 1
an: 1
place.: 1
saw: 1
but: 1
jumped: 1
and: 3
Bunny: 3
middle: 1
flying: 1
being: 1
dismay,: 1
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
18/11/29 14:37:42 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
18/11/29 14:37:43 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
18/11/29 14:37:43 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
18/11/29 14:37:43 INFO ui.SparkUI: Stopped Spark web UI at http://172.16.48.71:4040
18/11/29 14:37:43 INFO cluster.SparkDeploySchedulerBackend: Shutting down all executors
18/11/29 14:37:43 INFO cluster.SparkDeploySchedulerBackend: Asking each executor to shut down
18/11/29 14:37:43 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
7. 在浏览器可以看到作业记录
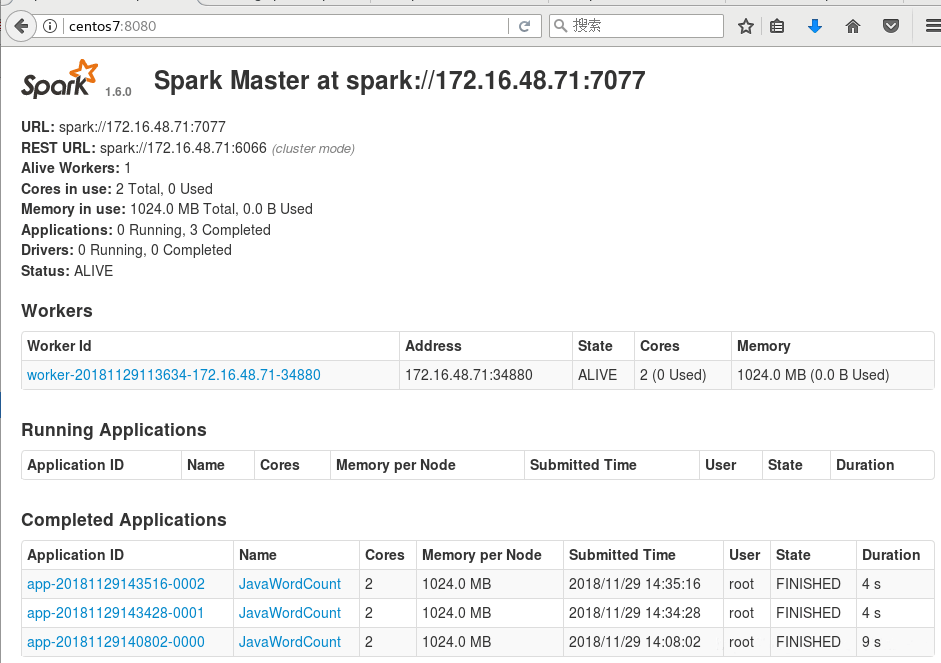
更多关于java算法相关内容感兴趣的读者可查看本站专题:《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《Java文件与目录操作技巧汇总》和《Java缓存操作技巧汇总》
希望本文所述对大家java程序设计有所帮助。