Python 中的数据操作几乎等同于 NumPy 数组操作,甚至新出现的Pandas 工具 也是构建在 NumPy 数组的基础之上的。
数组的属性 确定数组的大小、形状、存储大小、数据类型。
数组的索引 获取和设置数组各个元素的值。
数组的切分 在大的数组中获取或设置更小的子数组。
数组的变形 改变给定数组的形状。
数组的拼接和分裂 将多个数组合并为一个,以及将一个数组分裂成多个。
目录
数组索引:获取单个元素
数组切片:获取子数组
数组的变形:
数组拼接和分裂:
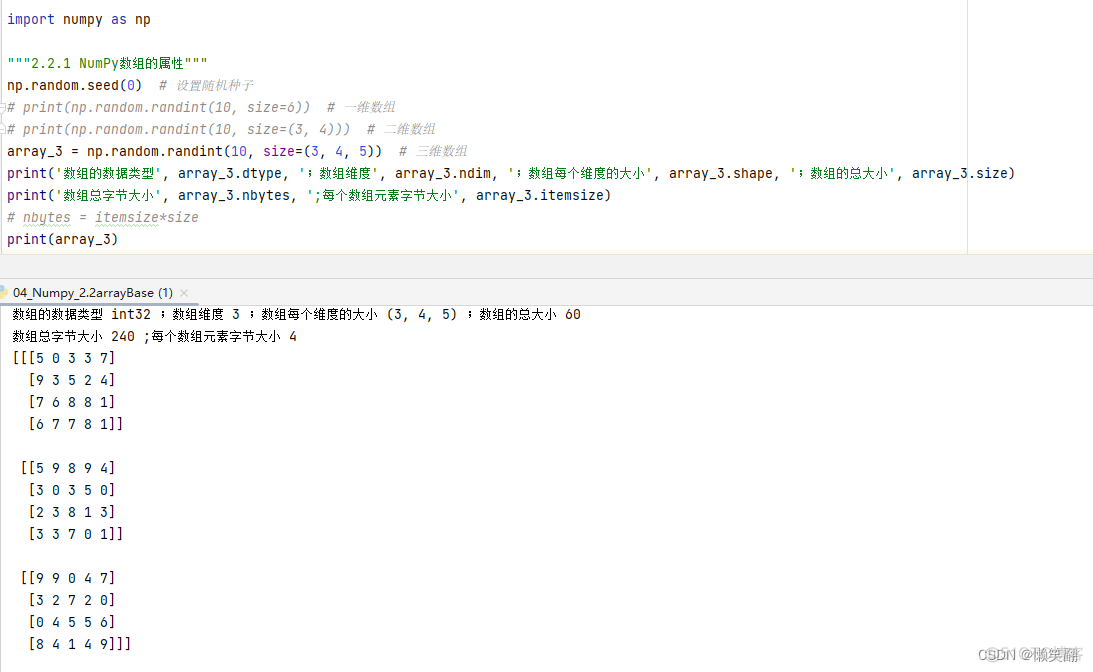
NumPy数组的属性
每个数组有 nidm(数组的维度)、shape(数组每个维度的大小)和 size(数组的总大小)属性、dtype(数组的数据类型)、itemsize(每个数组元素字节大小的) ,nbytes(表示数 组总字节大小的属性 )( 一般来说,可以认为 nbytes 跟 itemsize 和 size 的乘积大小相等。 ):
np.random.seed(0) # 设置随机种子
# print(np.random.randint(10, size=6)) # 一维数组
# print(np.random.randint(10, size=(3, 4))) # 二维数组
array_3 = np.random.randint(10, size=(3, 4, 5)) # 三维数组
print('数组的数据类型', array_3.dtype, ';数组维度', array_3.ndim, ';数组每个维度的大小', array_3.shape, ';数组的总大小', array_3.size)
print('数组总字节大小', array_3.nbytes, ';每个数组元素字节大小', array_3.itemsize)
# nbytes = itemsize*size
print(array_3)
运行结果:
数组的数据类型 int32 ;数组维度 3 ;数组每个维度的大小 (3, 4, 5) ;数组的总大小 60数组总字节大小 240 ;每个数组元素字节大小 4
[[[5 0 3 3 7]
[9 3 5 2 4]
[7 6 8 8 1]
[6 7 7 8 1]]
[[5 9 8 9 4]
[3 0 3 5 0]
[2 3 8 1 3]
[3 3 7 0 1]]
[[9 9 0 4 7]
[3 2 7 2 0]
[0 4 5 5 6]
[8 4 1 4 9]]]
Process finished with exit code 0
数组索引:获取单个元素
一维数组中:(和 Python 列表一样,在一维数组中,你也可以通过中括号指定索引获取第 i 个值(从 0 开始计数):)
array_1 = np.array([1, 2, 3, 4, 5, 6])print(array_1[0])
运行结果:
1Process finished with exit code 0
多维数组中:(用逗号分隔的索引元组获取元素:)
array_3 = np.random.randint(10, size=(3, 4, 5)) # 三维数组print(array_3[0][0][-1])
运行结果:
7Process finished with exit code 0
根据索引修改元素值:
array_3[0][0][-1] = 8 # 根据索引修改元素值print(array_3[0][0][-1])
运行结果:
8Process finished with exit code 0
数组切片:获取子数组
正如此前用中括号获取单个数组元素,我们也可以用切片(slice)符号获取子数组,切片符号用冒号( : )表示。 NumPy 切片语法和 Python 列 表的标准切片语法相同。为了获取数组 x 的一个切片,可以用以下方式:
x[start:stop:step]
如果以上 3 个参数都未指定,那么它们会被分别设置默认值 start=0 、stop= 维度的大小( size of dimension )和 step=1 。我们将详细介 绍如何在一维和多维数组中获取子数组。
一维子数组:
# 一维子数组array_1 = np.arange(1, 11)
print(array_1)
print(array_1[:5]) # 获取前5个元素
print(array_1[5:]) # 获取索引5之后的元素
print(array_1[::2]) # 每间隔一个元素
print(array_1[5::2]) # 每间隔一个元素,从索引5开始
print(array_1[::-1]) # 所有元素逆序输出
print(array_1[5::-2]) # 逆序 每间隔一个元素,从索引5开始
print(array_1[:5:-2]) # 逆序 每间隔一个元素,到索引5为止
运行结果:
[ 1 2 3 4 5 6 7 8 9 10][1 2 3 4 5]
[ 6 7 8 9 10]
[1 3 5 7 9]
[ 6 8 10]
[10 9 8 7 6 5 4 3 2 1]
[6 4 2]
[10 8]
Process finished with exit code 0
多维子数组:
# 多维子数组array_3 = np.random.randint(10, size=(3, 4, 5)) # 三维数组
print(array_3)
print('-----------')
print(array_3[:2, :2]) # 前两个子数组 每个取前两行
print('-----------')
print(array_3[:, 0]) # 每一个子数组的第一行
print('-----------')
print(array_3[0, :]) # 索引为0的数组 所有内容
运行结果:
[[[5 0 3 3 7][9 3 5 2 4]
[7 6 8 8 1]
[6 7 7 8 1]]
[[5 9 8 9 4]
[3 0 3 5 0]
[2 3 8 1 3]
[3 3 7 0 1]]
[[9 9 0 4 7]
[3 2 7 2 0]
[0 4 5 5 6]
[8 4 1 4 9]]]
-----------
[[[5 0 3 3 7]
[9 3 5 2 4]]
[[5 9 8 9 4]
[3 0 3 5 0]]]
-----------
[[5 0 3 3 7]
[5 9 8 9 4]
[9 9 0 4 7]]
-----------
[[5 0 3 3 7]
[9 3 5 2 4]
[7 6 8 8 1]
[6 7 7 8 1]]
Process finished with exit code 0
数组的变形:
数组变形最灵活的实现方式是通过 reshape() 函数来实现。
如果希望该方法可行,那么原始数组的大小必须和变形后数组 的大小一致。如果满足这个条件, reshape 方法将会用到原始数组的一 个非副本视图。但实际情况是,在非连续的数据缓存的情况下,返回非副本视图往往不可能实现。
另外一个常见的变形模式是将一个一维数组转变为二维的行或列的矩阵。你也可以通过 reshape 方法来实现,或者更简单地在一个切片操作中利用 newaxis 关键字:
代码复现:
# 将数字 1~12 放入一个 4×3 的矩阵中
grid = np.arange(1, 13).reshape((4, 3))
print(grid)
print("---获取行向量")
print(grid[np.newaxis, 2:, :])
print("---获取列向量")
print(grid[:, np.newaxis, :1])
运行结果:
[[ 1 2 3][ 4 5 6]
[ 7 8 9]
[10 11 12]]
---获取行向量
[[[ 7 8 9]
[10 11 12]]]
---获取列向量
[[[ 1]]
[[ 4]]
[[ 7]]
[[10]]]
Process finished with exit code 0
数组拼接和分裂:
以上所有的操作都是针对单一数组的,但有时也需要将多个数组合并为一个,或将一个数组分裂成多个。接下来将详细介绍这些操作。
数组的拼接:
拼接或连接 NumPy 中的两个数组主要由 np.concatenate 、 np.vstack 和 np.hstack 例程实 现。
代码复现:
# 一次性拼接三个一维数组x = np.array([1, 2, 3])
y = np.array([3, 2, 1])
z = np.array([4, 5, 6])
print(np.concatenate([x, y, z]))
# 拼接二维数组
print("拼接二维数组")
grid = np.array([[1, 2, 3], [4, 5, 6]])
print(np.concatenate([grid, grid, grid]))
print(np.concatenate([grid, grid, grid], axis=1))
# 垂直栈数组
print("垂直栈数组")
x = np.array([1, 2, 3])
grid = np.array([[1, 2, 3], [4, 5, 6]])
print(np.vstack([x, grid]))
# 水平栈数组
print("水平栈数组")
x = np.array([[4], [7]])
grid = np.array([[1, 2, 3], [4, 5, 6]])
print(np.hstack([grid, x]))
# dstack 沿着第三个维度拼接数组
print("沿着第三个维度拼接数组")
a = np.array((1, 2, 3))
b = np.array((2, 3, 4))
print(np.dstack((a, b)))
print("沿着第三个维度拼接数组")
a = np.array([[1], [2], [3]])
b = np.array([[2], [3], [4]])
print(np.dstack((a, b)))
运行结果:
[1 2 3 3 2 1 4 5 6]拼接二维数组
[[1 2 3]
[4 5 6]
[1 2 3]
[4 5 6]
[1 2 3]
[4 5 6]]
[[1 2 3 1 2 3 1 2 3]
[4 5 6 4 5 6 4 5 6]]
垂直栈数组
[[1 2 3]
[1 2 3]
[4 5 6]]
水平栈数组
[[1 2 3 4]
[4 5 6 7]]
沿着第三个维度拼接数组
[[[1 2]
[2 3]
[3 4]]]
沿着第三个维度拼接数组
[[[1 2]]
[[2 3]]
[[3 4]]]
Process finished with exit code 0
数组的分裂:
与拼接相反的过程是分裂。分裂可以通过 np.split 、 np.hsplit和 np.vsplit 函数来实现。可以向以上函数传递一个索引列表作为参数,索引列表记录的是分裂点位置:
代码复现:
# 数组的分裂
x = [1, 2, 3, 99, 99, 3, 2, 1]
x1, x2, x3 = np.split(x, [3, 5])
print(x1, x2, x3)
运行结果:
[1 2 3] [99 99] [3 2 1]Process finished with exit code 0
值得注意的是,N 分裂点会得到 N + 1 个子数组。相关的np.hsplit 和 np.vsplit 的用法也类似,np.dsplit 将数组沿着第三个维度分裂。
grid = np.arange(16).reshape((4, 4))
print(grid)
print("vsplit----")
upper, lower = np.vsplit(grid, [2])
print(upper)
print(lower)
print("hsplit----")
left, right = np.hsplit(grid, [2])
print(left)
print(right)
print("dsplit----")
x = np.arange(16).reshape(2, 2, 4)
print(x)
print(np.dsplit(x, 2))
运行结果:
[[ 0 1 2 3][ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
vsplit----
[[0 1 2 3]
[4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]
hsplit----
[[ 0 1]
[ 4 5]
[ 8 9]
[12 13]]
[[ 2 3]
[ 6 7]
[10 11]
[14 15]]
dsplit----
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
[array([[[ 0, 1],
[ 4, 5]],
[[ 8, 9],
[12, 13]]]), array([[[ 2, 3],
[ 6, 7]],
[[10, 11],
[14, 15]]])]
Process finished with exit code 0