以上是普通的情况,存在可以定位的属性,当某个元素的各个属性及其组合都不足以定位时,我们可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,先看看xpath中支持的
以上是普通的情况,存在可以定位的属性,当某个元素的各个属性及其组合都不足以定位时,我们可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,先看看xpath中支持的方法:
、child 选取当前节点的所有子元素
、parent 选取当前节点的父节点
、descendant选取当前节点的所有后代元素(子、孙等)
、ancestor 选取当前节点的所有先辈(父、祖父等)
、descendant-or-self选取当前节点的所有后代元素(子、孙等)以及当前节点本身
、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
、preceding-sibling选取当前节点之前的所有同级节点
、following-sibling选取当前节点之后的所有同级节点
、preceding 选取文档中当前节点的开始标签之前的所有节点
、following 选取文档中当前节点的结束标签之后的所有节点
、self 选取当前节点
、attribute 选取当前节点的所有属性
、namespace选取当前节点的所有命名空间节点
driver = webdriver.PhantomJS()
driver.get("https://www.readnovel.com/free/all?pageNum=1&pageSize=10&gender=1&catId=20001&isFinish=1&isVip=1&size=-1&updT=-1&orderBy=0")
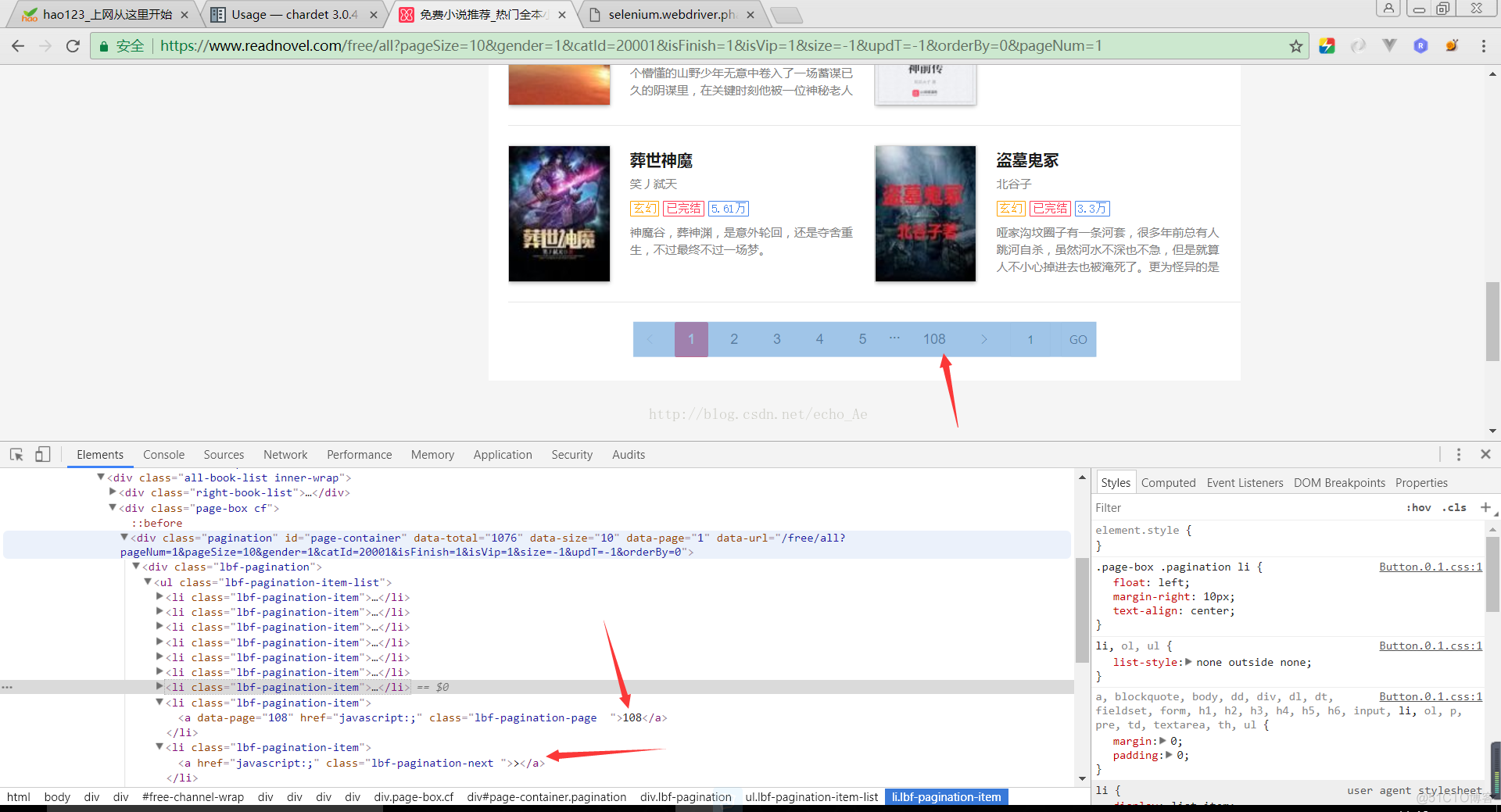
# getPage_text = driver.find_element_by_class_name('lbf-pagination-item-list').find_element_by_xpath("li/a[@class='lbf-pagination-next ']").get_attribute("innerHTML")
# 打印 >
# getPage_text = driver.find_element_by_class_name('lbf-pagination-item-list').find_element_by_xpath("li/a[@class='lbf-pagination-next ']/parent::li[1]").get_attribute("innerHTML")
# 打印 <a href="javascript:;" class="lbf-pagination-next ">></a>
getPage_text = driver.find_element_by_class_name('lbf-pagination-item-list').find_element_by_xpath("li/a[@class='lbf-pagination-next ']/parent::li[1]/preceding-sibling::li[1]").get_attribute("innerHTML")
# 打印 <a data-page="108" href="javascript:;" class="lbf-pagination-page ">108</a>
getPage_text = driver.find_element_by_class_name('lbf-pagination-item-list').find_element_by_xpath("li/a[@class='lbf-pagination-next ']/parent::li[1]/preceding-sibling::li[1]/descendant::a[1]").get_attribute("innerHTML")
print(getPage_text) # 打印 108