@[toc]
ForkJoin
ForkJoin是Java7提供的一个并行执行任务的框架,是把大任务分割成若干个小任务,待小任务完成后将结果汇总成大任务结果的框架。主要采用的是工作窃取算法,工作窃取算法是指某个线程从其他队列里窃取任务来执行。Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行.假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应.比如A线程负责处理A列里的任务。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。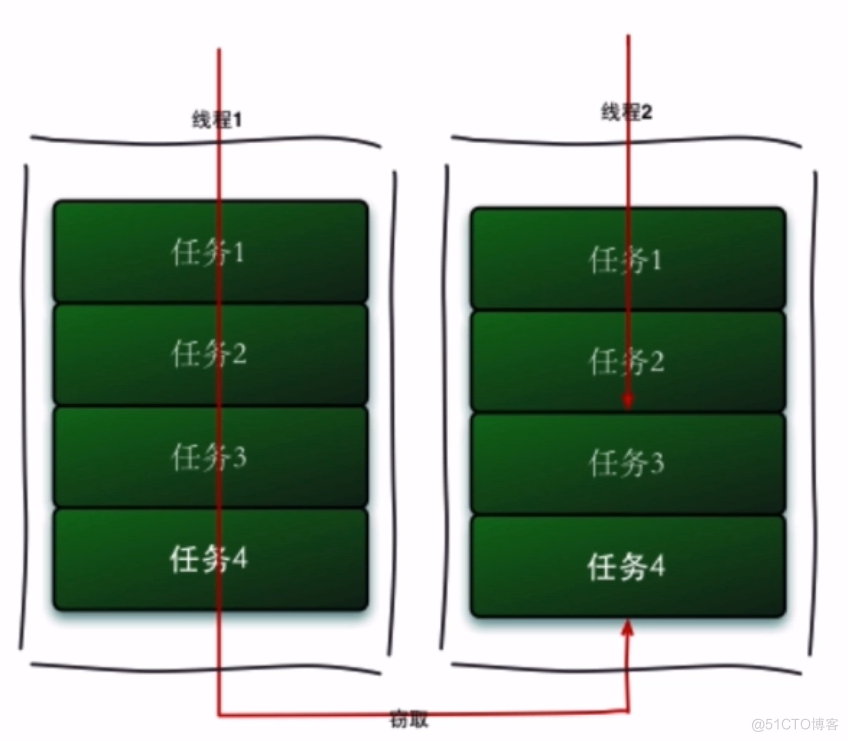 优点
优点
- 充分利用线程进行并行计算,减少了线程间的竞争。
缺点
- 在某些情况下还是存在竞争,比如双端队列里只有一个任务时。
- 该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列
参考案例:
/** * ForkJoinTask * 通常情况下,我们不需要直接继承ForkJoinTask类,只需要继承它的子类。 * Fork/Join框架提供了以下两个子类: * RecursiveAction:用于没有返回结果的任务 * RecursiveTask:用于有返回结果的任务 * @author zjq */ @Slf4j public class ForkJoinTaskExample extends RecursiveTask<Integer> { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskExample(int start, int end) { this.start = start; this.end = end; } /** * 执行fork()和join()操作 * @return */ @Override protected Integer compute() { int sum = 0; //如果任务足够小就计算任务 boolean canCompute = (end - start) <= threshold; if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } } else { // 如果任务大于阈值,就分裂成两个子任务计算 int middle = (start + end) / 2; ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end); // 执行子任务 leftTask.fork(); rightTask.fork(); // 等待任务执行结束合并其结果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); // 合并子任务 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { //ForkJoinTask需要通过ForkJoinPool来执行 ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一个计算任务,计算1+2+3+4 ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100); //执行一个任务 Future<Integer> result = forkjoinPool.submit(task); try { log.info("result:{}", result.get()); } catch (Exception e) { log.error("exception", e); } } }BlockingQueue阻塞队列
主要应用场景:生产者消费者模型,是线程安全的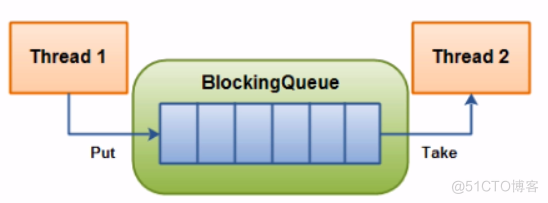
阻塞情况
1、当队列满了进行入队操作2、当队列空了的时候进行出队列操作
四套方法
BlockingQueue提供了四套方法,分别来进行插入、移除、检查。每套方法在不能立刻执行时都有不同的反应。
- Throws Exceptions :如果不能立即执行就抛出异常。
- Special Value:如果不能立即执行就返回一个特殊的值。
- Blocks:如果不能立即执行就阻塞
-
Times Out:如果不能立即执行就阻塞一段时间,如果过了设定时间还没有被执行,则返回一个值
实现类
- ArrayBlockingQueue:它是一个有界的阻塞队列,内部实现是数组,初始化时指定容量大小,一旦指定大小就不能再变。采用FIFO方式存储元素。
- DelayQueue:阻塞内部元素,内部元素必须实现Delayed接口,Delayed接口又继承了Comparable接口,原因在于DelayQueue内部元素需要排序,一般情况按过期时间优先级排序。
DalayQueue内部采用PriorityQueue与ReentrantLock实现。
public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E> { private final transient ReentrantLock lock = new ReentrantLock(); private final PriorityQueue<E> q = new PriorityQueue<E>(); ... }-
LinkedBlockingQueue:大小配置可选,如果初始化时指定了大小,那么它就是有边界的。不指定就无边界(最大整型值)。内部实现是链表,采用FIFO形式保存数据。
public LinkedBlockingQueue() { this(Integer.MAX_VALUE);//不指定大小,无边界采用默认值,最大整型值 } - PriorityBlockingQueue:带优先级的阻塞队列。无边界队列,允许插入null。插入的对象必须实现Comparator接口,队列优先级的排序规则就是按照我们对Comparable接口的实现来指定的。我们可以从PriorityBlockingQueue中获取一个迭代器,但这个迭代器并不保证能按照优先级的顺序进行迭代。
- SynchronusQueue:只能插入一个元素,同步队列,无界非缓存队列,不存储元素。
本文内容到此结束了, 如有收获欢迎点赞