pprof的基本操作, 上次博客有记录, 这里进一步研究pprof
接下来开始今天的学习内容. 计划今天研究以下几个部分的内容
1. pprof扩展
a. 在单元测试testing.B中测试检测程序的性能
b. web项目中检测程序的性能
2. pprof的使用, 以及如何看生成的svg图.
3. 使用pprof分析近期做过的一个beego项目
4. 调研pprof是否能够使用在生成环境.
5. 研究testing.T, testing.B testing.TB testing.N的区别
一. pprof扩展
Go语言自带了强大的性能测试工具pprof,位于 net/http 包下的 pprof, 官方文档
go中有pprof包来做代码的性能监控,在两个地方有包:net/http/pprof 和 runtime/pprof
其实net/http/pprof中只是使用runtime/pprof包来进行封装了一下,并在http端口上暴露出来.
- net/http/pprof : 可以做到直接看到当前 web 服务的状态,包括 CPU 占用情况和内存使用情况等。如果服务是一直运行的,如 web 应用,可以很方便的使用第一种方式 import "net/http/pprof"。
- runtime/pprof : 可以用来产生 dump 文件,再使用 Go Tool PProf 来分析这运行日志。
我们研究pprof的使用从两个方面研究 :
1. 如何查看单元测试中对性能的测试分析
2. 查看web服务的性能
1. 查看单元测试中对性能的测试分析
我们借用上一次的一个例子. 对异常处理的代码部分进行性能分析
第一步: 写性能分析的测试用例.
比如: 我们模拟用户错误的输出情况
func BenchmarkWrapError(t *testing.B) {h := handlerUserError
code := 400
message := "user error"
for i := 0; i < t.N ; i ++ {
f := WrapError(h)
// 模拟Request和response
response := httptest.NewRecorder()
request := httptest.NewRequest(http.MethodGet, "http://www.baidu.com", nil)
f(response, request)
//读取reponse返回的body
b, _ := ioutil.ReadAll(response.Body)
body := strings.Trim(string(b), "\n")
if code != response.Code || message != body {
t.Errorf("except--code: %d, message: %s \n actual--code:%d, message:%s",
code, message, response.Code, body)
}
}
}
第二步: 进入到文件目录, 在命令行执行 go test -bench . -cpuprofile cpu.out 性能测试cpu的消耗情况
go test -bench . -cpuprofile cpu.out第三步: 执行pprof分析
go tool pprof cpu.out第四步: 输入web, 会生成一个svg的文件, 然后使用浏览器查看视图.
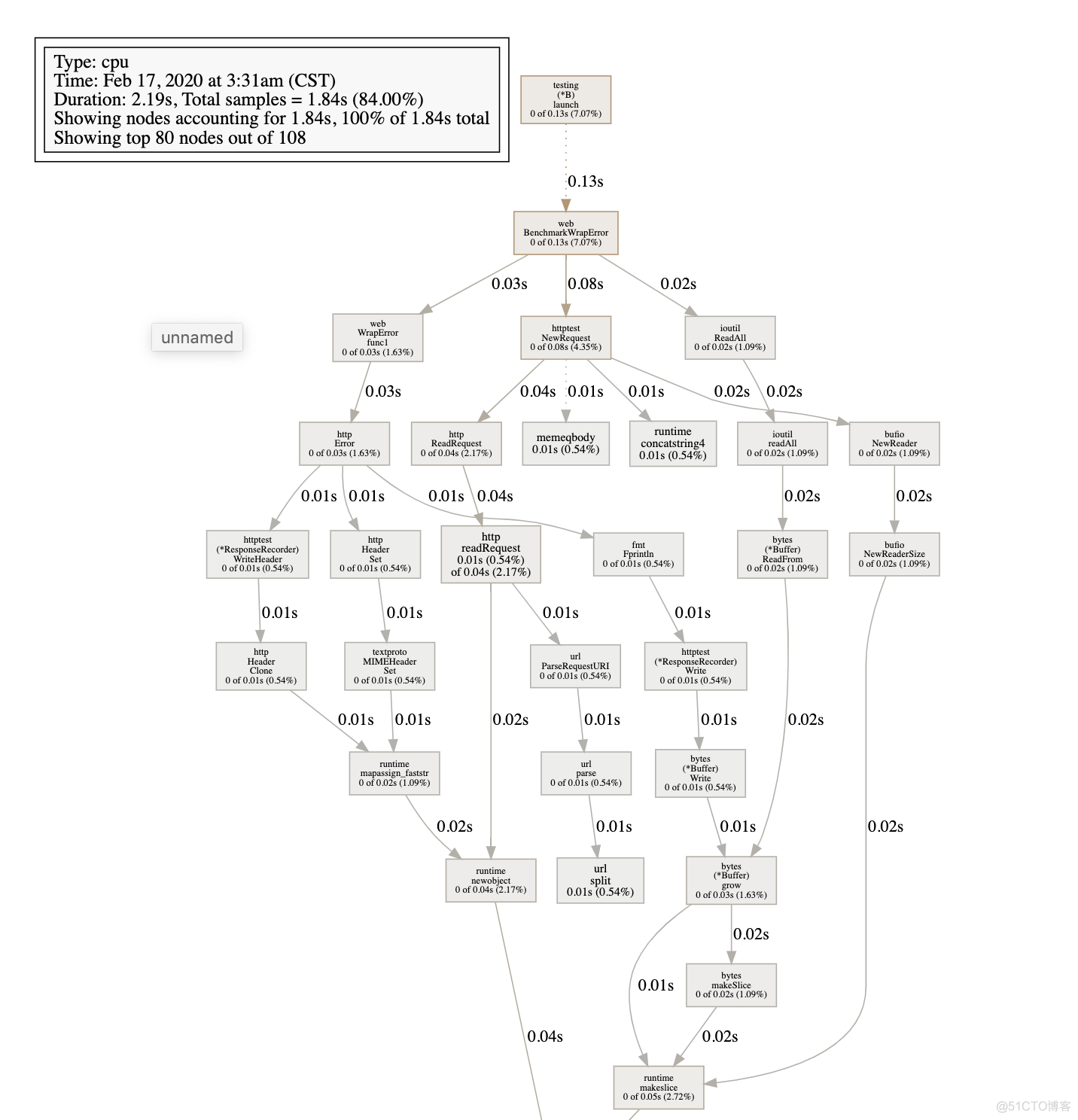
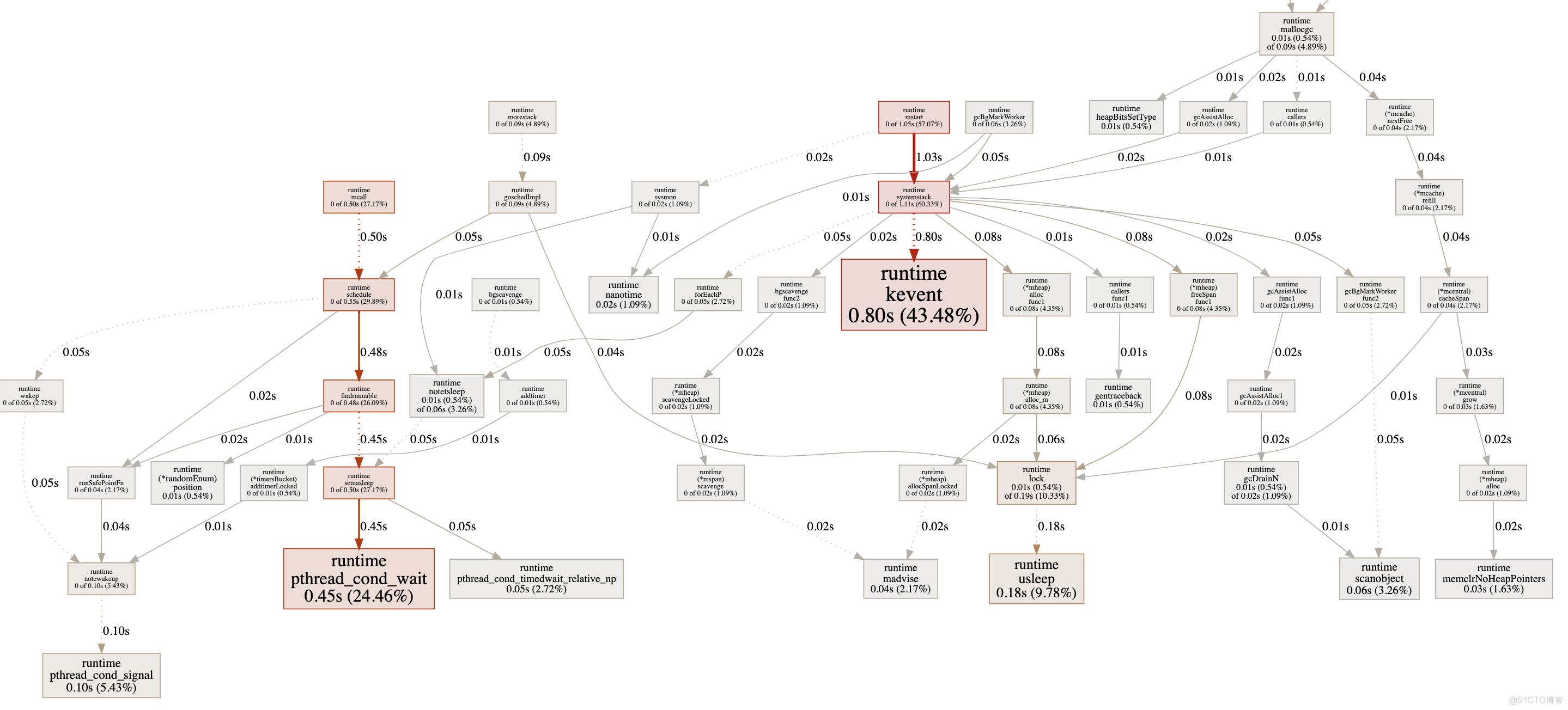
从图中可以看出每一步花费的时间大概是多少. 其中哪一个步骤花费的时间最长. 然后我们就可以针对其进行优化了
备注: 要想以web视图的方式查看上述结果, 需要下载graphviz, 下载方式参考的第四点, 附截图

2. 查看web服务的性能
第一步: import 增加net/http/pprof包
import(_ net/http/pprof
)
第二步: 打开http端的监听端口
go func() {http.ListenAndServe("localhost:8888", nil)
}()
第三步: 在网页上查看, 输入http://localhost:8888/debug/profile, 这是会看到如下页面

这个页面分为两部分. 第一部分是当前服务的使用情况. 第二部分, 对命令的解析
使用情况截图如下

Count 表示当前服务使用数, 比如2, 是消耗内存的进程数. 21表示线程创建数, 2 表示历史数据. 等等
Profile 是性能指标名
命令说明如下:
- allocs: 过去所有内存分配的样本
- block: 堆栈导致对原始同步的阻塞
- cmline: 当前程序的命令行调用
- goroutine: 当前所有goroutine的堆栈跟踪
- heap: 活动对象内存分配的采样。您可以指定gc GET参数以在获取堆样本之前运行GC。
- mutex: 竞争互斥持有人的堆栈痕迹
- profile: CPU配置文件。您可以在GET参数中指定持续时间。获取概要文件后,请使用go tool pprof命令调查文件。
- threadcreate: 导致创建新OS线程的堆栈跟踪
- trace: 当前程序执行的痕迹。您可以在GET参数中指定持续时间。获取跟踪文件后,使用go工具trace命令调查跟踪。
第四步: 通过Graphviz, 查看heap
从图中看, cpu的使用是0, heap的使用是2, 所以, 我们查看heap.
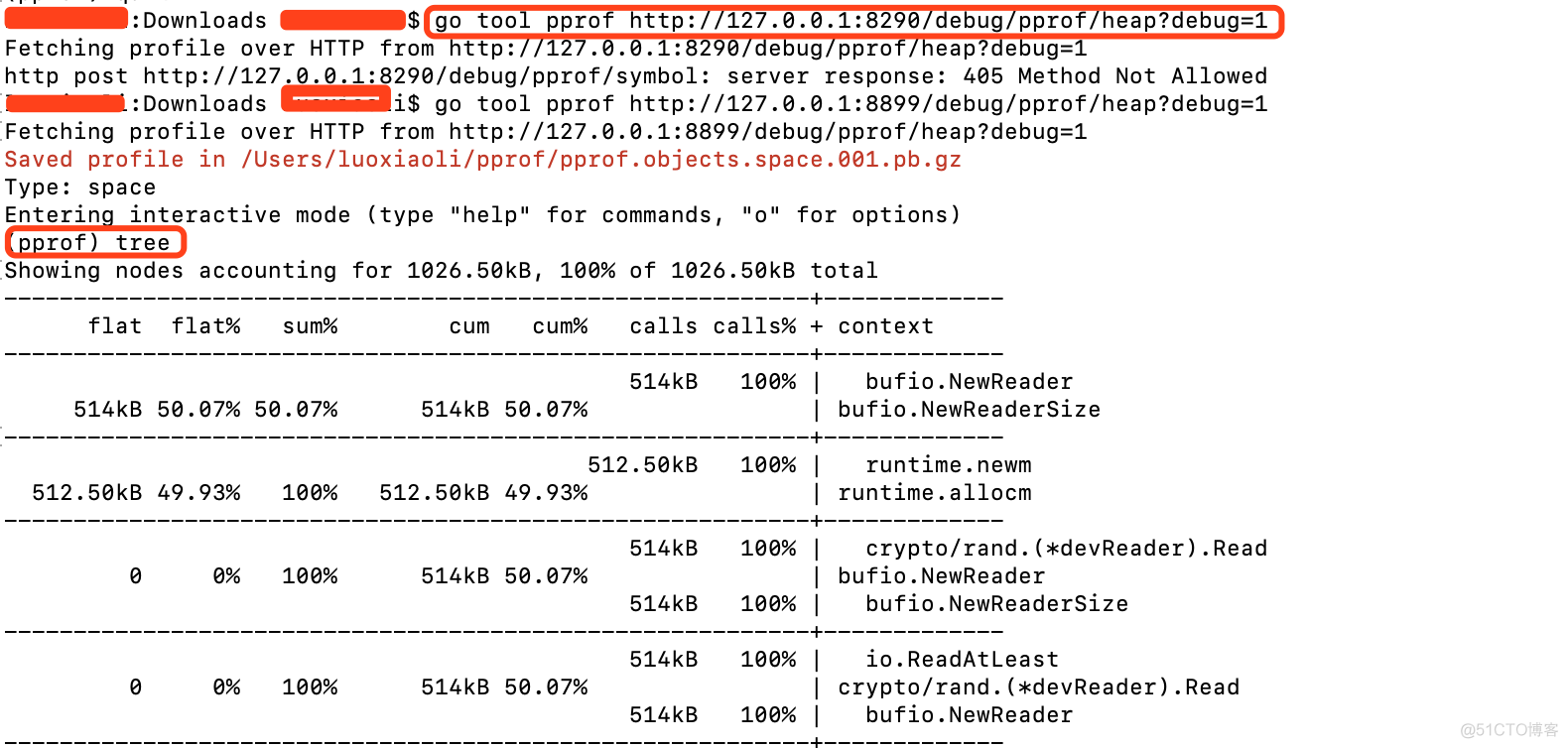
go tool pprof http://127.0.0.1:8888/debug/pprof/heap接下来我们可以通过help 查看pprof都有哪些命令. 常用的命令有. tree, top, web
我们用tree查看内存的使用情况
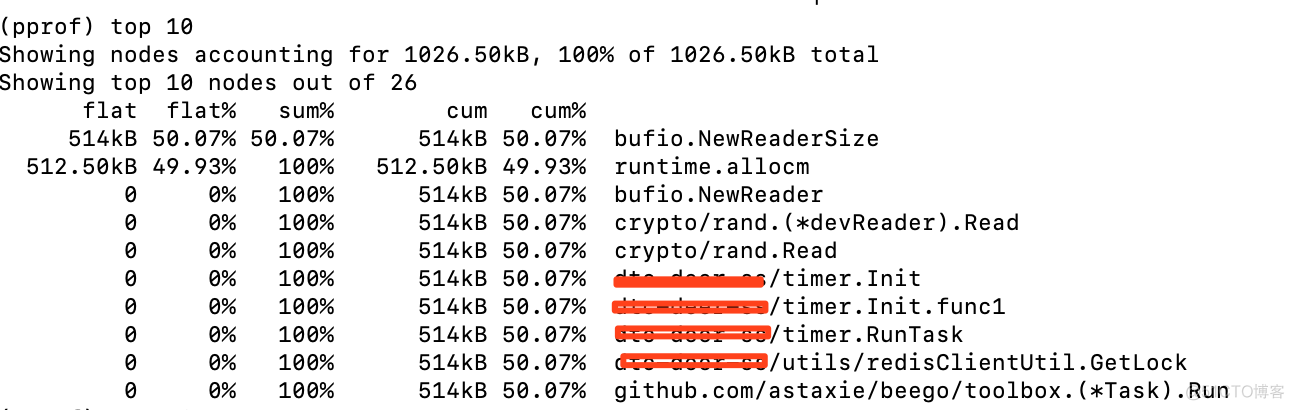
还可以使用top查看最消耗内存的地方
接下来还是使用web查看视图
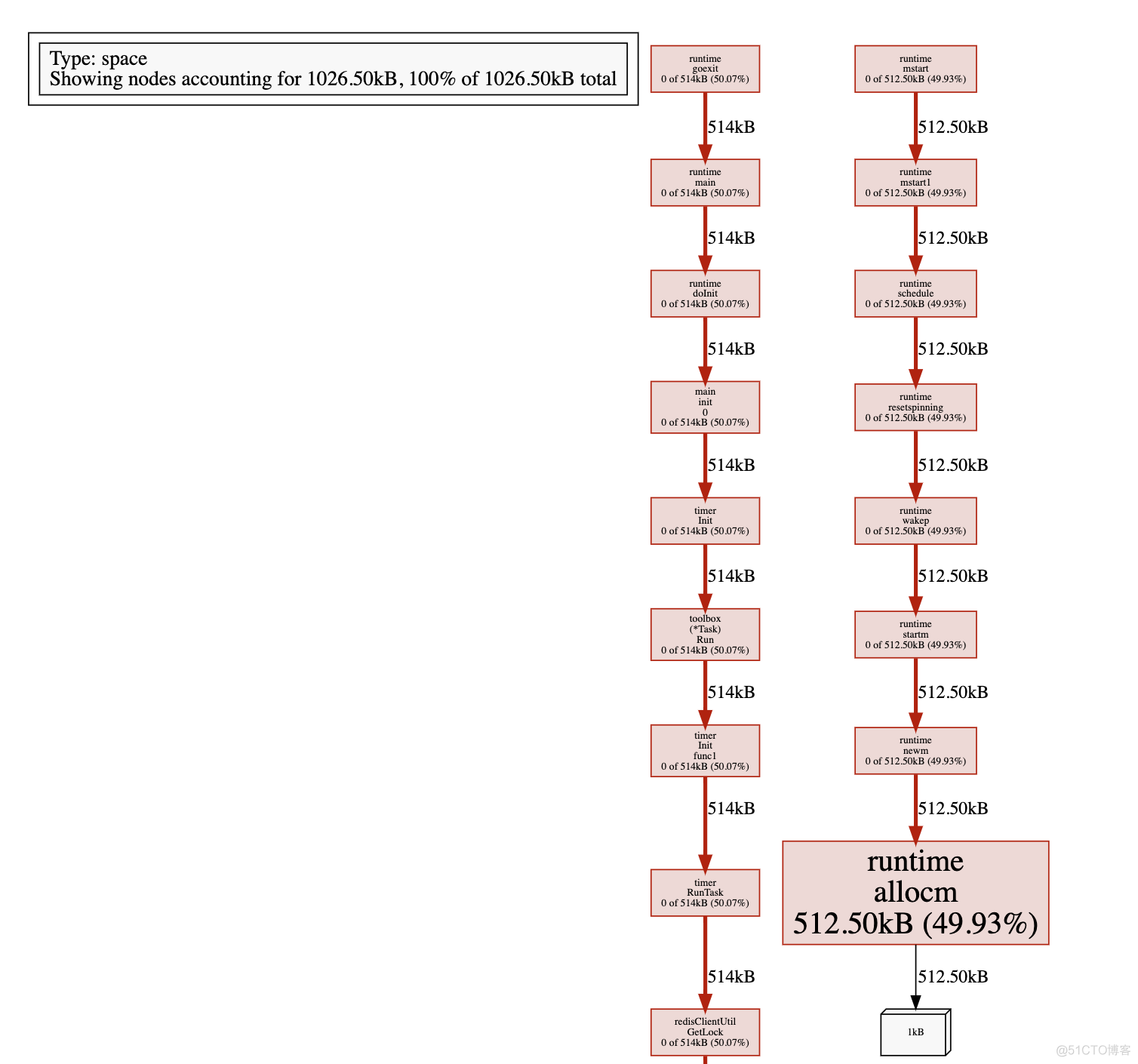
视图更加直观, 哪一步消耗了多少内存
第五步: 模拟并发, 测试性能
这样的程序都是刚刚运行, 所以内存消耗, cpu消耗都比较少. 接下来我们模拟大量请求, 试一试性能如何
1. 下载一个模拟http请求的工具wrk(模拟现实, 了解系统瓶颈, 将服务器置于一个繁忙的状态, 就像生产环境一样. ), 下载地址: https://github.com/wg/wrk.git
在github上也有这个工具的介绍,
git clonehttps://github.com/wg/wrk.gitcd wrk
make
备注: 整个操作参考github上的说明即可.
2. 安装好wrk以后, 模拟批量请求
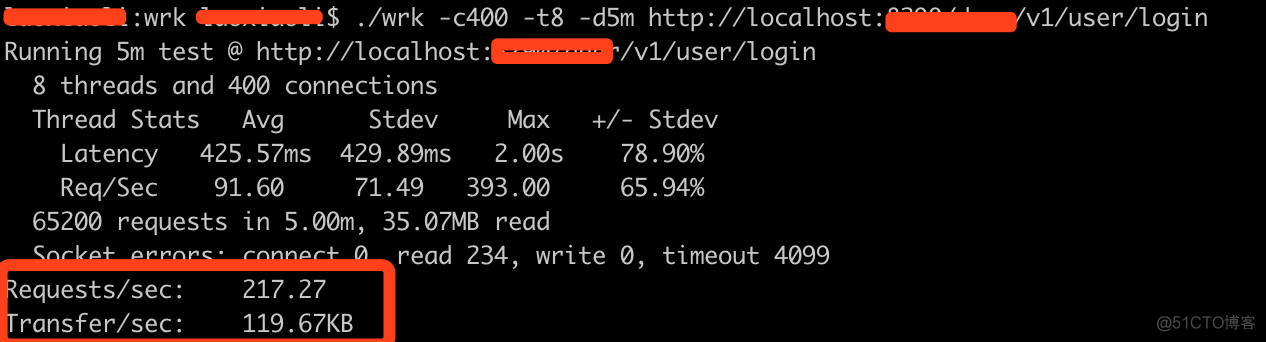
./wrk -c400 -t8 -d5m http://localhost:8899/v1/user/login我模拟的是批量登录, 参数含义如下
- -c400: 我们有400个连接可以保持打开状态
- -t8 :意味着我们使用8个线程来构建请求
- -d5m 表示测试时间将持续5分钟
3. 在浏览器输入
http://localhost:8899/debug/pprof/查看使用情况
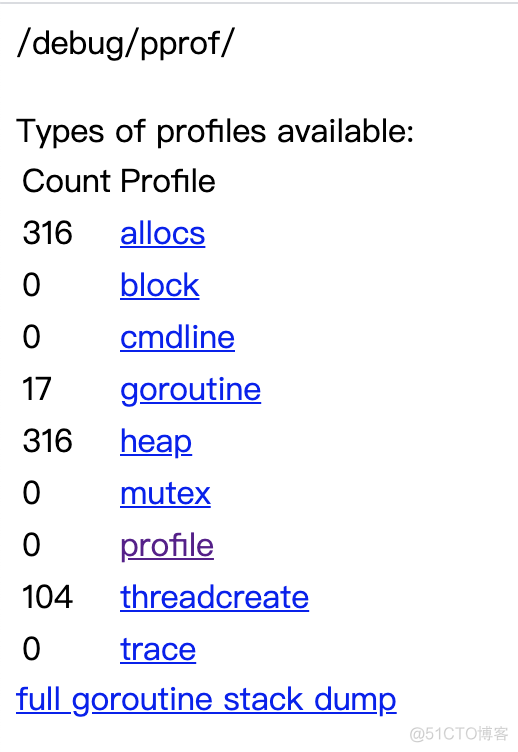
4. awk执行完以后, 查看执行结果汇总
5. 接下来用go tool pprof 查看 heap
go tool pprof -alloc_space/-inuse_space http://localhost:8899/debug/pprof/heap-alloc_space: 过去使用的内存数据-inuse_space: 正在使用的内存数据返回的视图
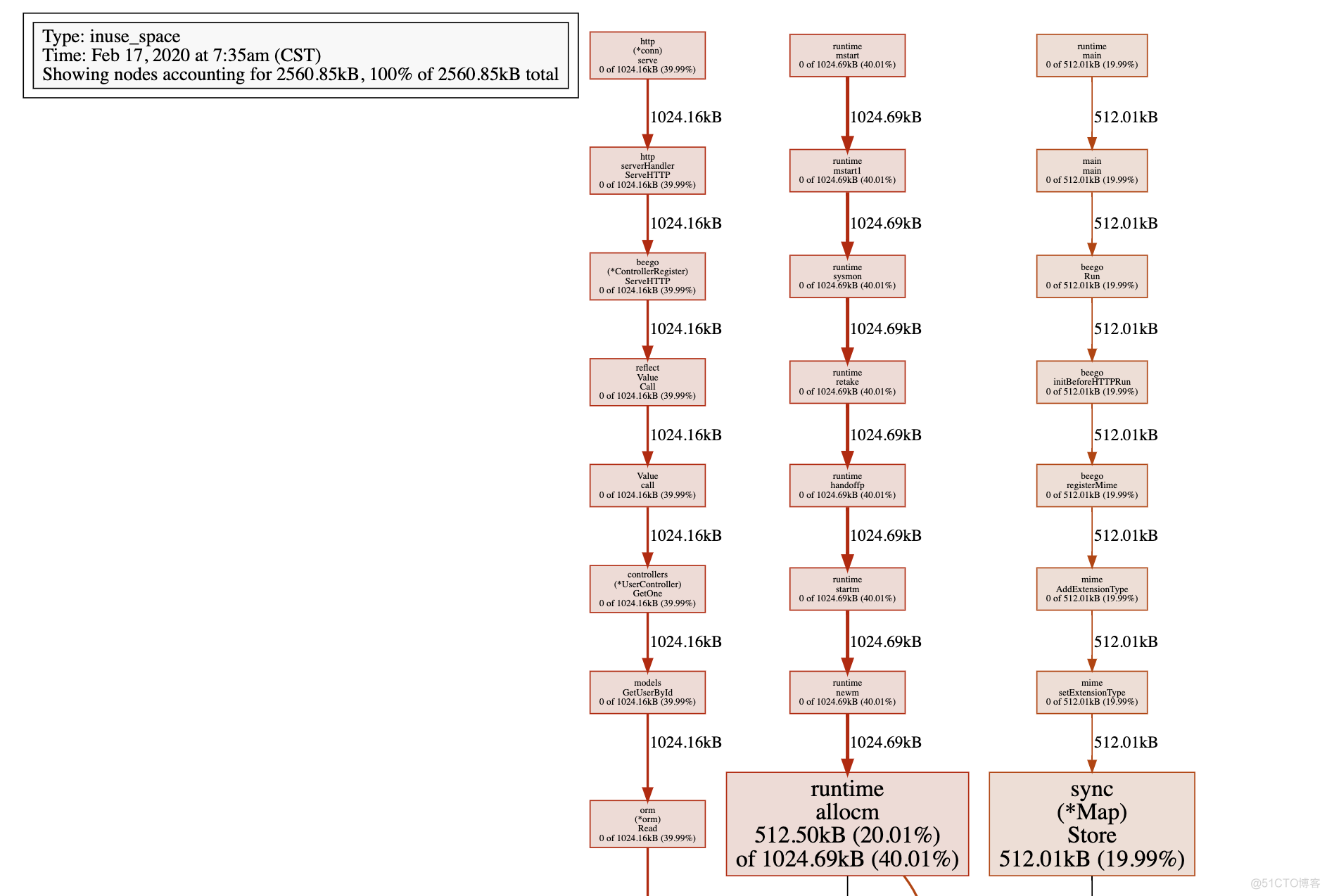
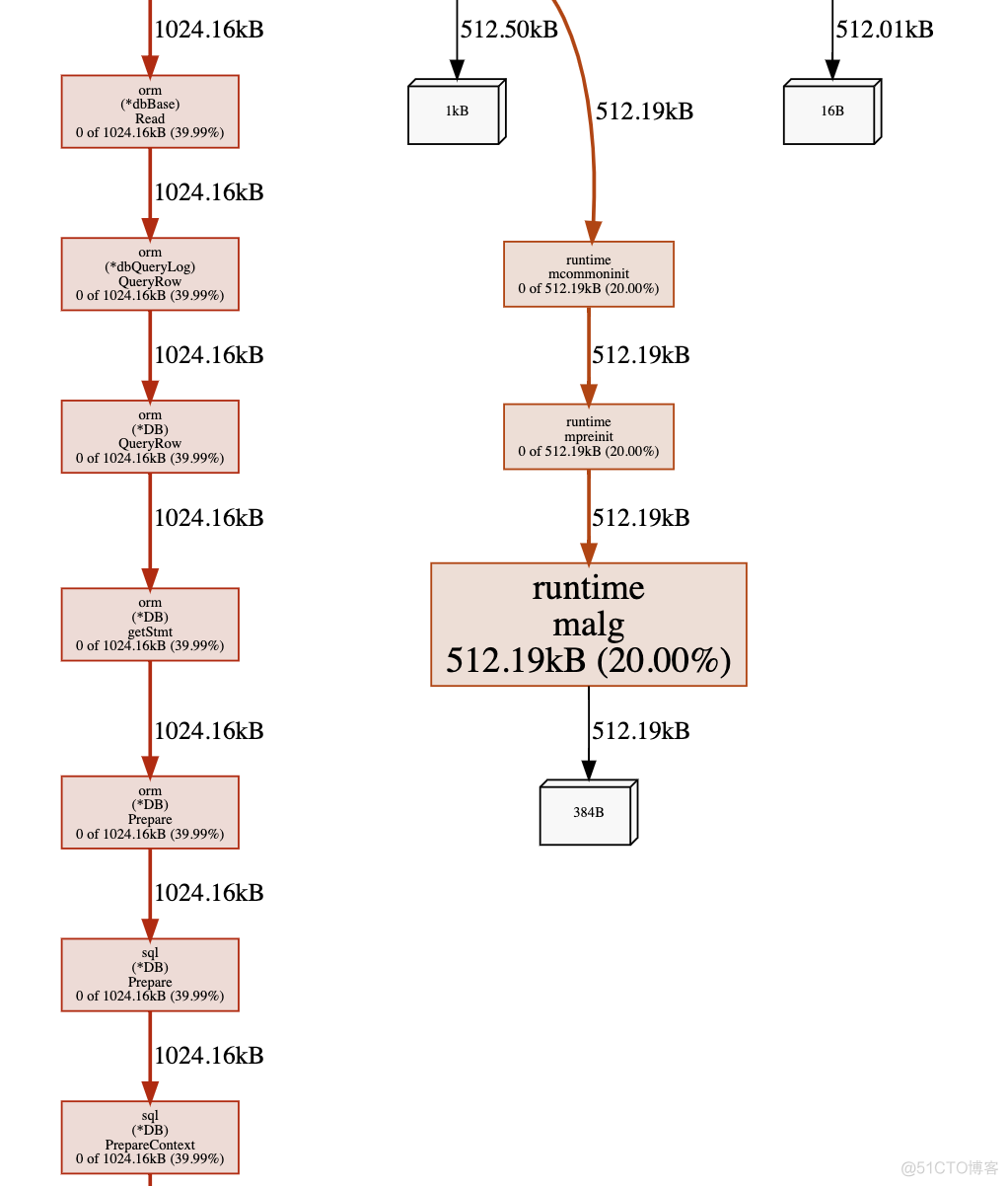
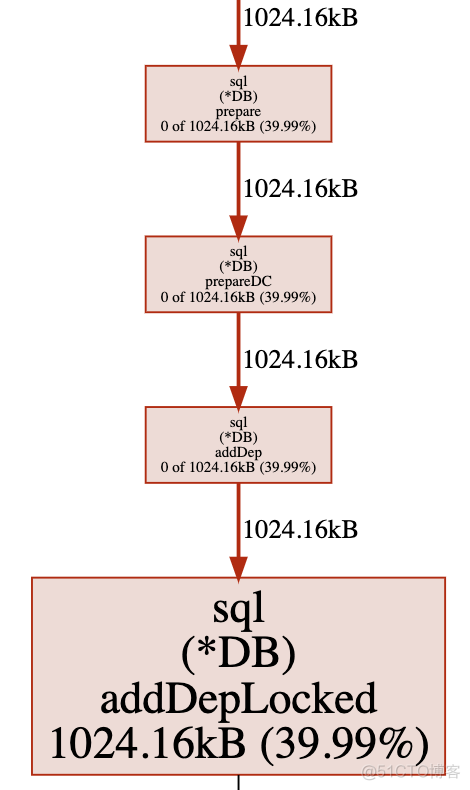
方框越大, 表示内存消耗越多.
参考文献:
1. https://www.jianshu.com/p/aa9b148e90e5
