前言
聊完MySQL和Redis,我们接下来在聊一聊Zookeeper。相信大家都已经发现了,这些都是我们在开发过程非常常用的技术。搞定他们,一切难题都不在话下。
Zookeeper,盘它
官网是我们学习某一种技术框架的第一手资料,通过官网我们能挖掘到该框架的最新动态
What Is Zookeeper
Zookeeper是一款主要解决分布式协调的服务框架,可以用来维护配置信息、命名、提供分布式同步和服务提供等功能。Zookeeper基于ZAB【ZooKeeper 原子广播】协议,支持高可用。
图片来源自官方介绍
Zookeeper的设计
设计目标
Zookeeper的设计很简单,其目的就是为了:
- 减轻分布式应用程序实现协调服务的压力,允许分布式进程通过共享的分层命名空间相互协调
而在Zookeeper中的文件存储可以称为:znodes,类似于Linux下的目录和文件;而不同的一点是:ZooKeeper 数据保存在内存中。这样也就意味着Zookeeper自身可以实现实现高吞吐量和低延迟
命名空间设计
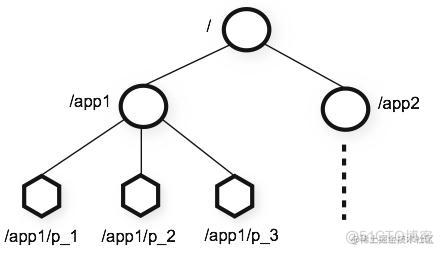
图片来源自官方介绍
Zookeeper中名称全部由斜杠【/】 分隔的一系列路径元素,命名空间中的每个节点都由路径标识。而每个节点都可以拥有与其关联的数据以及子节点。这就像拥有一个允许文件也成为目录的文件系统
专业点来说Zookeeper中的每一个节点都可以称为znode, 主要分为两类:
- 持久节点:【节点只要创建就存在,除非手动删除】
- 临时节点:【只要创建znode的会话处于活动状态,那么当前节点就会存在;当会话结束,临时节点自动删除】
有序节点是在临时节点和持久节点的基础上创建的时候后面跟上顺序,本质上没有发生很大的变化
Zookeeper提供了监听/回调的机制,当客户端对znode进行操作之后,会触发watch机制,客户端受到znode已经改变的数据包。
从开发角度来看,这种属于Reactor编程模型,纯异步编程
Netty就是这种编程模型的典型案例
稳定大局
对Zookeeper有一点了解之后,我们就要开始使用它了,我们使用它的目的是为了实现分布式锁。那么我们先来搞定基础环境
我们这里先按照单机环境来做,后面会给出集群环境的配置方式
需要注意的是:2N + 1原则
Zookeeper集群最少需要三台服务器,并且强烈建议使用奇数台服务器。如果您只有两台服务器,那么您会遇到这样的情况:如果其中一台出现故障,则没有足够的机器来形成多数法定人数。两台服务器本质上不如一台服务器稳定,因为有两个单点故障
环境规划
我们这里使用的Zookeeper版本:3.6.2
Zookeeper强依赖于JDK,并且需要安装JDk1.8之上的版本
node ip port zookeeper 192.168.10.200 2181单机环境
环境规划完成之后,接下来就看我操作吧。
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.6.2/apache-zookeeper-3.6.2-bin.tar.gz # 解压 tar xf apache-zookeeper-3.6.2-bin.tar.gz -C /usr/local/ # 进入到/usr/local下,改个名字 mv apache-zookeeper-3.6.2-bin/ zookeeper-3.6.2其实到这里环境就已经安装完成了,下面就是针对Zookeeper的配置
# 配置文件全部存放在conf下,并且我们需要将模板配置换成`zoo.cfg`,不然无法生效 cd /usr/local/zookeeper-3.6.2/conf && cp ./zoo_sample.cfg ./zoo.cfg vim zoo.cfg # 默认在tmp下,但是tmp属于系统临时文件目录,我们最好进行修改 dataDir=/var/data/bigdata/zookeeper按照zoo.cfg中的配置,我们也只需要改动dataDir的目录就可以了,其他的暂时默认就好
关于Zookeeper更多的配置,在官网《配置参数》中找到
环境变量配置
# 编辑配置 vim /etc/profile export ZOOKEEPER_HOME=/usr/local/zookeeper-3.6.2 export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 export PATH=$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH # 使其生效 source /etc/profile下面就开始启动阶段了
# 以下为启动的全部命令 zkServer.sh [--config <conf-dir>] {start|start-foreground|stop|version|restart|status|print-cmd} # 启动:这里已经将Zookeeper加入到了环境变量中 zkServer.sh start # 展示启动状态 zkServer.sh status集群配置
集群配置环境下,需要改变两个地方:
第一步:在zoo.cfg配置文件中添加集群节点的配置
server.1=192.168.10.200:2181:2888:3888 server.2=192.168.10.201:2181:2888:3888 server.3=192.168.10.202:2181:2888:3888第二步:在各自节点的$dataDir目录下添加myid文件,内容对应上面配置的序号
echo 1 > myid echo 2 > myid echo 3 > myid记得要和zoo.cfg中配置的唯一序号一一对应
集群对比单机版只是多了一些配置,其他的没有任何变化。相对比还是非常简单的
客户端操作
Zookeeper提供了命令行的操作方式,通过zkCli.sh来启动,并且操作方式和Linux命令基本相同,下面我们简单演示一下
# 本地环境可以不配置 zkCli.sh [-server 127.0.0.1:2181]下面通过一张图来简单介绍一些Zookeeper的增删改查吧

这其实非常简单的,而且我们并不用搞懂它,毕竟我们在操作的时候并不能直接连到服务器上,下面我们来看看如何通过提供的API来对Zookeeper进行操作吧
锁住它
知其然
在《分布式锁原理》一文中我们曾经介绍过基于Zookeeper实现分布式锁的思路,主要通过Zookeeper的临时节点来实现:
- 在主节点下每个客户端过来都会注册临时有序节点
- 每个节点只监听自己前一个节点,如果发现自己是第一个节点,说明已经获取到了锁
而只要客户端断开session连接,临时有序节点自动删除,客户端锁就被释放
知其所以然
下面我们就通过Zookeeper的API来实现一个分布式锁吧。还是老样子,一版自己写,一版看看人家的实现方式。对比一下。
原生代码
private static final CountDownLatch LATCH = new CountDownLatch(1); // 获取ZooKeeper的操作 public static ZooKeeper getZk() { ZooKeeper zooKeeper = null; try { zooKeeper = new ZooKeeper("192.168.10.200:2181/locks", 1000, event -> { switch (event.getState()) { case SyncConnected: // 等到回到 链接成功的事件,就能释放阻塞 LATCH.countDown(); break; } }); //Reactor编程模型,返回很快,但是内存中并没有构建完成,所以需要等待 LATCH.await(); } catch (Exception e) { e.printStackTrace(); } return zooKeeper; }主要代码
public class LockWatchCallback implements Watcher, AsyncCallback.StringCallback, AsyncCallback.ChildrenCallback, AsyncCallback.StatCallback { private ZooKeeper zk; private String name; private String nodePathName; private CountDownLatch latch = new CountDownLatch(1); public LockWatchCallback(ZooKeeper zk, String name) { this.zk = zk; this.name = name; } public void lock() { /** * 创建节点: * path: 如果在192.168.10.200:2181/locks指定了目录,那么这里的 根目录 代表的是 /locks,然后在创建对应的临时节点 * ZooDefs.Ids.OPEN_ACL_UNSAFE: 权限:全部开放 * CreateMode.EPHEMERAL_SEQUENTIAL: 临时有序节点 * StringCallback: 节点创建完成之后的回调 */ zk.create("/lock", name.getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL, this, name); try { latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } } public void unLock() { try { zk.delete(nodePathName, -1); } catch (Exception e) { e.printStackTrace(); } } @Override public void process(WatchedEvent event) { switch (event.getType()) { // 当节点删除之后,重新拉取一次全部子节点,然后进行监听处理 case NodeDeleted: zk.getChildren("/", false, this, "abc"); break; } } // zk.create("/lock", name.getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL, this, name); 回调 @Override public void processResult(int rc, String path, Object ctx, String name) { if (null != name) { nodePathName = name; // 得到根节点下创建的节点,我们不需要watch根目录 zk.getChildren("/", false, this, "abc"); } } // zk.getChildren("/", false, this, "abc"); 回调 @Override public void processResult(int rc, String path, Object ctx, List<String> children) { // 得到的children是无序的,所以要先做一个排序 Collections.sort(children); // /lock0000000000, 而children中是没有斜线的,所以要截取一下 int i = 1; if ((i = children.indexOf(nodePathName.substring(1))) < 1) { // 自己已经是第一个节点了,获取到了锁,开始执行 try { zk.setData("/", this.name.getBytes(StandardCharsets.UTF_8), 1); } catch (Exception e) { e.printStackTrace(); } // 释放掉阻塞,让执行 latch.countDown(); } else { // 监控自己的前一个节点是否还存在 try { zk.exists("/" + children.get(i - 1), this, this, "abc"); } catch (Exception e) { e.printStackTrace(); } } } @Override public void processResult(int rc, String path, Object ctx, Stat stat) { } }全程采用Zookeeper提供的异步API方式进行回调处理,在每一步回调的地方都添加了注释,看起来是比较方便的。
毕竟是个不成熟的小案例,缺少了分布式锁的很多特性,比如:锁重入等等
『不用太刻意对上面的代码做研究,在生产环境下是不会使用这样的代码的』
下面我看一下如何测试:为了能和之前的程序进行统一,做了一个小小的封装,也可以直接使用LockWatchCallback对象来处理锁操作
public class ZookeeperLock extends AbstractLock { ZooKeeper zk; LockWatchCallback watchCallback; public ZookeeperLock(ZooKeeper zk) { this.zk = zk; } @Override public void start() { // 每个线程都需要创建一个临时有序节点,所以每个线程都会new一个watchCallback对象 watchCallback = new LockWatchCallback(zk, Thread.currentThread().getName()); } @Override public void lock() { // 加锁,创建节点 this.watchCallback.lock(); } @Override public void unlock() { // 解锁,删除节点 this.watchCallback.unLock(); } @Override public void destory() { try { zk.close(); } catch (InterruptedException e) { e.printStackTrace(); } } private static ExecutorService executorService = Executors.newCachedThreadPool(); public static void main(String[] args) throws InterruptedException { int[] count = {0}; final ZookeeperLock zkLock = new ZookeeperLock(getZk()); for (int i = 0; i < 100; i++) { executorService.submit(() -> { zkLock.start(); zkLock.lock(); count[0]++; zkLock.unlock(); }); } executorService.shutdown(); executorService.awaitTermination(1, TimeUnit.HOURS); System.out.println(count[0]); zkLock.destory(); } }成熟框架
那接下来我们就聊一聊成熟的框架是怎么实现分布式锁的:Curator
- 实现方式是不变的,不过在我们上一版的基础丰富了更多的锁特性,并且实现更加稳定,调用更加方便
看看这个代码量是不是简洁了很多,虽然简洁,但是功能俱全。我们来验证一下:
private static ExecutorService executorService = Executors.newCachedThreadPool(); public static void main(String[] args) throws InterruptedException { ZkLock zkLock = new ZkLock("192.168.10.200:2181","/locks"); zkLock.start(); int[] num = {0}; long start = System.currentTimeMillis(); for(int i=0;i<200;i++){ executorService.submit(()->{ try { zkLock.lock(); num[0]++; } catch (Exception e){ throw new RuntimeException(e); } finally { zkLock.unlock(); } }); } executorService.shutdown(); executorService.awaitTermination(1, TimeUnit.HOURS); System.out.println(num[0]); }完全OK!!!
最后
关于Zookeeper分布式锁的实现我们就介绍到这里。Zookeeper在实际使用中的场景还是非常丰富的,包括分布式协调等功能都在等着大家一一探索。
而关于分布式锁还有最后一个章节就结束了,接下来我们就来了解一下关于后起之秀Etcd的相关操作和Etcd是如何实现分布式锁的。