1、初始化k8s软件包 k8s01、k8s02、k8s03操作: docker load -i k8simage-1-20-6.tar.gz yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6 systemctl enable kubelet systemctl start kubelet systemctl status kubelet #上面可以
1、初始化k8s软件包
k8s01、k8s02、k8s03操作:docker load -i k8simage-1-20-6.tar.gz
yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6
systemctl enable kubelet && systemctl start kubelet
systemctl status kubelet
#上面可以看到kubelet状态不是running状态,这个是正常的,不用管,等k8s组件起来这个kubelet就正常了。
#注:每个软件包的作用
#Kubeadm: kubeadm是一个工具,用来初始化k8s集群的
#kubelet: 安装在集群所有节点上,用于启动Pod的
#kubectl: 通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
2、通过keepalive+nginx实现k8s apiserver节点高可用
1、安装nginx主备:在k8s01和k8s02上做nginx主备安装
yum install nginx keepalived nginx-mod-stream -y
##必须要安装stream模块
2、修改nginx配置文件。主备一样
cat nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.10.131:6443;
server 192.168.10.132:6443;
server 192.168.10.133:6443;
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
3、keepalive配置
cat >keepalived.conf <<EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.10.188/24
}
track_script {
check_nginx
}
}
EOF
#vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
#virtual_ipaddress:虚拟IP(VIP)
4、脚本配置
echo '
#!/bin/bash
count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
'>check_nginx.sh
5、分发脚本
for ip in k8s01 k8s02;do
scp nginx.conf root@${ip}:/etc/nginx/nginx.conf
scp keepalived.conf root@${ip}:/etc/keepalived/keepalived.conf
scp check_nginx.sh root@${ip}:/etc/keepalived/check_nginx.sh
ssh root@${ip} "chmod +x /etc/keepalived/check_nginx.sh"
done
6、启动
k8s01操作
systemctl daemon-reload
systemctl restart nginx
systemctl restart keepalived
systemctl enable nginx keepalived
k8s02操作
sed -i 's/MASTER/BACKUP/g' /etc/keepalived/keepalived.conf
sed -i 's/priority 100/priority 90/g' /etc/keepalived/keepalived.conf
systemctl daemon-reload
systemctl restart nginx
systemctl restart keepalived
systemctl enable nginx keepalived
7、检测
ip addr ##k8s01多了一个192.168.10.188
当停掉k8s01的nginx,ip会漂移到k8s02
3、kubeadm初始化k8s集群
在k8s01上创建kubeadm-config.yaml文件:vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.20.6
controlPlaneEndpoint: 192.168.40.199:16443
imageRepository: registry.aliyuncs.com/google_containers
apiServer:
certSANs:
- 192.168.40.180
- 192.168.40.181
- 192.168.40.182
- 192.168.40.199
networking:
podSubnet: 10.244.0.0/16
serviceSubnet: 10.10.0.0/16
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
kubeadm init --config kubeadm-config.yaml
注:--image-repository registry.aliyuncs.com/google_containers:手动指定仓库地址为registry.aliyuncs.com/google_containers。kubeadm默认从k8s.grc.io拉取镜像,但是k8s.gcr.io访问不到,所以需要指定从registry.aliyuncs.com/google_containers仓库拉取镜像。
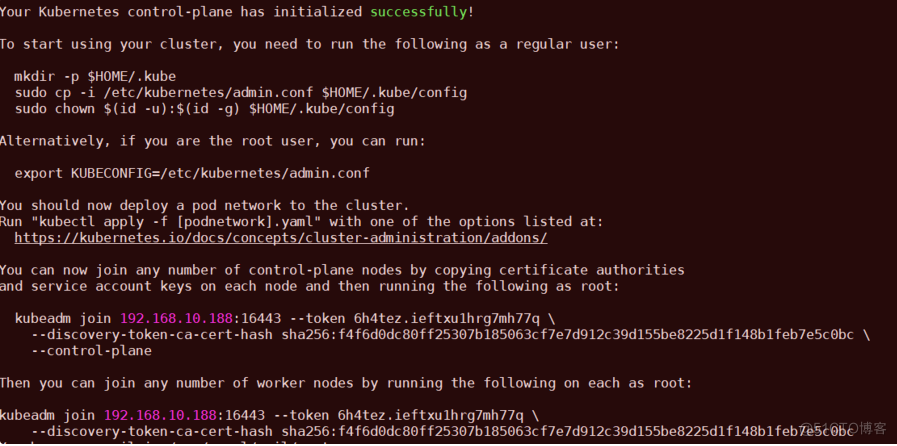
#配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl命令可以使用这个证书对k8s集群进行管理
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s01 NotReady control-plane,master 11m v1.20.6
#此时集群状态还是NotReady状态,因为没有安装网络插件。
4、扩容k8s集群-添加master节点
#把k8s01节点的证书拷贝到k8s02和k8s03上for ip in k8s02 k8s03;do
ssh root@${ip} "cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/"
scp /etc/kubernetes/pki/ca.crt root@${ip}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key root@${ip}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key root@${ip}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub root@${ip}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt root@${ip}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key root@${ip}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt root@${ip}:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key root@${ip}:/etc/kubernetes/pki/etcd/
done
在k8s01上查看加入节点的命令:
kubeadm token create --print-join-command
[root@k8s01 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.10.188:16443 --token uflinp.41ki3m870tmu6cd3 --discovery-token-ca-cert-hash sha256:f4f6d0dc80ff25307b185063cf7e7d912c39d155be8225d1f148b1feb7e5c0bc
#k8s02操作:
kubeadm join 192.168.10.188:16443 --token uflinp.41ki3m870tmu6cd3 --discovery-token-ca-cert-hash sha256:f4f6d0dc80ff25307b185063cf7e7d912c39d155be8225d1f148b1feb7e5c0bc --control-plane
##--control-plane 加入master节点,不加这个就是加入node节点
#配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl命令可以使用这个证书对k8s集群进行管理
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#k8s03操作:
kubeadm join 192.168.10.188:16443 --token uflinp.41ki3m870tmu6cd3 --discovery-token-ca-cert-hash sha256:f4f6d0dc80ff25307b185063cf7e7d912c39d155be8225d1f148b1feb7e5c0bc --control-plane
#配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl命令可以使用这个证书对k8s集群进行管理
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
5、完善node ROLE
[root@k8s01 ~]# kubectl get nodesNAME STATUS ROLES AGE VERSION
k8s01 NotReady control-plane,master 22m v1.20.6
k8s02 NotReady control-plane,master 6m43s v1.20.6
k8s03 NotReady control-plane,master 4m21s v1.20.6
[root@k8s01 ~]# kubectl describe nodes k8s01 |grep -A 1 Taints
Taints: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
[root@k8s01 ~]# kubectl describe nodes k8s02 |grep -A 1 Taints
Taints: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
[root@k8s01 ~]# kubectl describe nodes k8s03 |grep -A 1 Taints
Taints: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
#NoSchedule: 一定不能被调度
#PreferNoSchedule: 尽量不要调度
#NoExecute: 不仅不会调度, 还会驱逐Node上已有的Pod
#给k8s03添加work ROLE
kubectl label node k8s03 node-role.kubernetes.io/worker=worker
#去掉k8s03的污点
kubectl taint nodes k8s03 node-role.kubernetes.io/master-
##kubectl taint nodes --all node-role.kubernetes.io/master- ##会去掉所有节点污点
[root@k8s01 ~]# kubectl describe nodes k8s03 |grep -A 2 Taints
Taints: node.kubernetes.io/not-ready:NoSchedule
##还有一个NoSchedule是因为not-ready,calico网络设置好了就可以正常使用
[root@k8s01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s01 NotReady control-plane,master 30m v1.20.6
k8s02 NotReady control-plane,master 14m v1.20.6
k8s03 NotReady control-plane,master,worker 12m v1.20.6
[root@k8s01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7f89b7bc75-t47bp 0/1 Pending 0 30m
coredns-7f89b7bc75-w4s9z 0/1 Pending 0 30m
etcd-k8s01 1/1 Running 0 31m
etcd-k8s02 1/1 Running 0 15m
etcd-k8s03 1/1 Running 0 13m
kube-apiserver-k8s01 1/1 Running 1 31m
kube-apiserver-k8s02 1/1 Running 1 15m
kube-apiserver-k8s03 1/1 Running 0 13m
kube-controller-manager-k8s01 1/1 Running 1 31m
kube-controller-manager-k8s02 1/1 Running 0 15m
kube-controller-manager-k8s03 1/1 Running 0 13m
kube-proxy-5bzbp 1/1 Running 0 13m
kube-proxy-9jwqf 1/1 Running 0 15m
kube-proxy-pqzvq 1/1 Running 0 30m
kube-scheduler-k8s01 1/1 Running 1 31m
kube-scheduler-k8s02 1/1 Running 0 15m
kube-scheduler-k8s03 1/1 Running 0 13m
6、安装网络组件-Calico
上传calico.yaml到k8s01上,使用yaml文件安装calico 网络插件 。kubectl apply -f calico.yaml
kubectl get pod -n kube-system
#注:在线下载配置文件地址是: https://docs.projectcalico.org/manifests/calico.yaml
[root@k8s01 ~]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-6949477b58-m2gqv 1/1 Running 0 42s 10.244.236.129 k8s02 <none> <none>
calico-node-ljjcq 1/1 Running 0 42s 192.168.10.131 k8s01 <none> <none>
calico-node-tfnss 1/1 Running 0 42s 192.168.10.133 k8s03 <none> <none>
calico-node-z5n8b 1/1 Running 0 42s 192.168.10.132 k8s02 <none> <none>
coredns-7f89b7bc75-t47bp 1/1 Running 0 33m 10.244.73.65 k8s01 <none> <none>
coredns-7f89b7bc75-w4s9z 1/1 Running 0 33m 10.244.235.129 k8s03 <none> <none>
etcd-k8s01 1/1 Running 0 33m 192.168.10.131 k8s01 <none> <none>
etcd-k8s02 1/1 Running 0 18m 192.168.10.132 k8s02 <none> <none>
etcd-k8s03 1/1 Running 0 16m 192.168.10.133 k8s03 <none> <none>
kube-apiserver-k8s01 1/1 Running 1 33m 192.168.10.131 k8s01 <none> <none>
kube-apiserver-k8s02 1/1 Running 1 18m 192.168.10.132 k8s02 <none> <none>
kube-apiserver-k8s03 1/1 Running 0 16m 192.168.10.133 k8s03 <none> <none>
kube-controller-manager-k8s01 1/1 Running 1 33m 192.168.10.131 k8s01 <none> <none>
kube-controller-manager-k8s02 1/1 Running 0 18m 192.168.10.132 k8s02 <none> <none>
kube-controller-manager-k8s03 1/1 Running 0 16m 192.168.10.133 k8s03 <none> <none>
kube-proxy-5bzbp 1/1 Running 0 16m 192.168.10.133 k8s03 <none> <none>
kube-proxy-9jwqf 1/1 Running 0 18m 192.168.10.132 k8s02 <none> <none>
kube-proxy-pqzvq 1/1 Running 0 33m 192.168.10.131 k8s01 <none> <none>
kube-scheduler-k8s01 1/1 Running 1 33m 192.168.10.131 k8s01 <none> <none>
kube-scheduler-k8s02 1/1 Running 0 18m 192.168.10.132 k8s02 <none> <none>
kube-scheduler-k8s03 1/1 Running 0 16m 192.168.10.133 k8s03 <none> <none>
[root@k8s01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s01 Ready control-plane,master 37m v1.20.6
k8s02 Ready control-plane,master 21m v1.20.6
k8s03 Ready control-plane,master,worker 19m v1.20.6
7、部署tomcat服务
#把tomcat.tar.gz上传到k8s03,手动解压docker load -i tomcat.tar.gz
kubectl apply -f tomcat.yaml
[root@k8s01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-pod 1/1 Running 0 8s
kubectl apply -f tomcat-service.yaml
[root@k8s01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 44m
tomcat NodePort 10.10.129.159 <none> 8080:30080/TCP 3m27s
在浏览器访问ip:30080即可请求到浏览器
http://192.168.10.131:30080/
http://192.168.10.132:30080/
http://192.168.10.133:30080/
8、测试coredns是否正常
#把busybox-1-28.tar.gz上传到k8s03,手动解压docker load -i busybox-1-28.tar.gz
[root@k8s01 ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes.default.svc.cluster.local
Server: 10.10.0.10
Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default.svc.cluster.local
Address 1: 10.10.0.1 kubernetes.default.svc.cluster.local
/ # nslookup tomcat.default.svc.cluster.local
Server: 10.10.0.10
Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local
Name: tomcat.default.svc.cluster.local
Address 1: 10.10.129.159 tomcat.default.svc.cluster.local
/ # exit
10.10.0.10 就是我们coreDNS的clusterIP,说明coreDNS配置好了。
解析内部Service的名称,是通过coreDNS去解析的。
#注意:
busybox要用指定的1.28版本,不能用最新版本,最新版本,nslookup会解析不到dns和ip
9、控制节点删除重新加入
tar zxvf etcd-v3.3.4-linux-amd64.tar.gzcd etcd-v3.3.4-linux-amd64
ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key member list
1203cdd3ad75e761, started, k8s01, https://192.168.10.131:2380, https://192.168.10.131:2379
b71a3456ad801f24, started, k8s02, https://192.168.10.132:2380, https://192.168.10.132:2379
2、找到k8s02对应的hash值是:b71a3456ad801f24
3、我们下一步就是根据hash删除etcd信息,执行如下命令
ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key member remove b71a3456ad801f24
4、查看加入集群命令:
[root@k8s01 ~]kubeadm token create --print-join-command
kubeadm join 192.168.10.188:16443 --token fvby4y.o2m8zhb7j9unpdxt --discovery-token-ca-cert-hash sha256:1ba1b274090feecfef58eddc2a6f45590299c1d0624618f1f429b18a064cb728
5、把k8s02从k8s集群删除,重新加入到k8s步骤
[root@k8s01 ~]# kubectl delete nodes k8s02
[root@k8s02 ~]# kubeadm reset
6、把k8s01上的证书还是按照文档全都拷贝到k8s02机器上
[root@k8s01 ~]# scp /etc/kubernetes/pki/ca.crt k8s02:/etc/kubernetes/pki/
[root@k8s01 ~]# scp /etc/kubernetes/pki/ca.key k8s02:/etc/kubernetes/pki/
[root@k8s01 ~]# scp /etc/kubernetes/pki/sa.key k8s02:/etc/kubernetes/pki/
[root@k8s01 ~]# scp /etc/kubernetes/pki/sa.pub k8s02:/etc/kubernetes/pki/
[root@k8s01 ~]# scp /etc/kubernetes/pki/front-proxy-ca.crt k8s02:/etc/kubernetes/pki/
[root@k8s01 ~]# scp /etc/kubernetes/pki/front-proxy-ca.key k8s02:/etc/kubernetes/pki/
[root@k8s02 ~]# mkdir /etc/kubernetes/pki/etcd/
[root@k8s01 ~]# scp /etc/kubernetes/pki/etcd/ca.crt k8s02:/etc/kubernetes/pki/etcd/
[root@k8s01 ~]# scp /etc/kubernetes/pki/etcd/ca.key k8s02:/etc/kubernetes/pki/etcd/
7、在k8s02执行如下命令,把节点加入k8s集群,充当控制节点:
[root@k8s02 ~]# kubeadm join 192.168.10.188:16443 --token fvby4y.o2m8zhb7j9unpdxt --discovery-token-ca-cert-hash sha256:1ba1b274090feecfef58eddc2a6f45590299c1d0624618f1f429b18a064cb728 --control-plane
8、查看集群是否加入成功:
[root@k8s01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s01 Ready control-plane,master 102m v1.20.6
k8s02 Ready control-plane,master 50s v1.20.6
k8s03 Ready <none> 13m v1.20.6