只是简单两个case,后面还需要不断丰富~ 1、取子集 类似于基础函数的subset~ ## 基础函数,感觉subset反而更方便 ## 参数:指定数据框、筛选行、筛选列 subset(x=iris,Sepal.Length5,select=Sepal.Lengt
只是简单两个case,后面还需要不断丰富~
1、取子集
类似于基础函数的subset~
## 基础函数,感觉subset反而更方便## 参数:指定数据框、筛选行、筛选列
subset(x=iris,Sepal.Length<5,select=Sepal.Length)
## dplyr
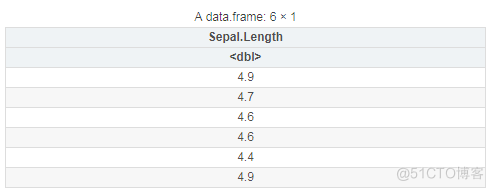
## filter筛选行、select筛选列library(dplyr)
head(iris %>% filter(Sepal.Length<5) %>% select(Sepal.Length))
2、变量变换/重构mutate
类似于基础函数的subset~
head(late_refund_data)## 数据格式
Var1 Freq
1 0 27005
2 1 5549
3 2 2757
4 3 2081
5 4 2392
6 5 1156
## 求累计百分比
late_refund_data <-
mutate(late_refund_data,
Cum_Freq = cumsum(Freq),
Cum_Prop = Cum_Freq / sum(Freq))
## 最终结果
Var1 Freq Cum_Freq Cum_Prop
1 0 27005 27005 0.6064042
2 1 5549 32554 0.7310085
3 2 2757 35311 0.7929176
4 3 2081 37392 0.8396470
5 4 2392 39784 0.8933600
6 5 1156 40940 0.9193183
2020-05-18 于南京市江宁区九龙湖