目录
一、数据结构和算法: 4
1、解压序列赋值给多个变量 4
2、解压可迭代对象赋值给多个变量 5
3、保留最后N个元素collections.deque 5
4、查找最大或最小的N个元素heapq.nlargest|nsmallest 5
5、实现一个优先级队列heapq.heappush()|heapq.heappop() 6
6、字典中的键映射多个值(multidict)collections.defaultdict 8
7、字典排序(有序字典)collections.OrderedDict 8
8、字典运算 9
9、查找2字典的相同点 10
10、删除序列中相同元素并保持顺序 11
11、命名切片slice(start,stop,step) 12
12、序列中出现次数最多的元素collections.Counter 13
13、通过某个关键字排序一个字典列表operator.itemgetter 13
14、排序不支持原生比较的对象operator.attrgetter 14
15、通过某个字段将记录分组itertools.groupby 15
16、过滤序列元素 16
17、从字典中提取子集: 18
18、映射名称到序列元素collections.namedtuple 19
19、转换并同时计算数据,生成器表达式 20
20、合并多个字典或映射collections.ChainMap 21
二、字符串和文本 23
1、使用多个界定符分割字符串re.split() 23
2、字符串开头或结尾匹配str.startswith()|str.endswith() 24
3、用shell通配符匹配字符串fnmatch.fnmatch 24
4、字符串匹配和搜索re.match()|re.findall() 25
5、字符串搜索和替换re.sub() 26
6、字符串忽略大小写的搜索替换 27
7、最短匹配模式.*?|.+? 28
8、多行匹配模式 28
9、将Unicode文本标准化 28
10、正则表达式使用Unicode 29
11、删除字符串中不需要的字符str.strip()|re.sub('\s+','',s1) 29
12、审查清理文本字符串 29
13、字符串对齐format() 29
14、合并拼接字符串join() 30
15、字符串中插入变量format()|format_map() 31
16、以指定列宽格式化字符串textwrap.fill() 32
17、在字符串中处理html|xml 33
18、字符串令牌解析 34
19、实现一个简单的递归下降分析器 34
20、字节字符串上的字符串操作 34
三、数字|日期|时间 35
1、数字的四舍五入round(value, ndigits) 35
2、执行精确的浮点数运算 36
3、数字的格式化输出format() 37
4、二|八|十六进制整数 38
5、字节到大整数的打包与解包 38
6、复数的数学运算cmath|numpy 39
7、无穷大与NaN 40
8、分数运算fractions.Fraction 41
9、大型数组运算numpy 41
10、矩阵np.matrix()与线性代数运算 42
11、随机选择random 42
12、基本的日期与时间转换datetime|dateutil 43
13、计算最后一个周五的日期 45
14、计算当月份的日期范围 45
15、字符串转换为日期datetime.strptime() 45
16、结合时区的日期操作pytz 46
四、迭代器与生成器 46
1、手动遍历迭代器 47
2、代理迭代__iter__() 48
3、使用生成器创建新的迭代模式 49
4、实现迭代器协议 50
5、反向迭代reversed(lst)|__reversed__() 51
6、带有外部状态的生成器函数 52
7、迭代器切片itertools.islice() 53
8、跳过可迭代对象的开始部分itertools.dropwhile()|itertools.islice() 54
9、排列组合的迭代itertools.permutations()|itertools.combinations()|itertools.combinations_with_replacement() 55
10、序列上索引值迭代enumerate() 55
11、同时迭代多个序列zip()|itertools.zip_longest() 57
12、不同集合上元素的迭代itertools.chain() 58
***13、创建数据处理管道 59
14、展开嵌套的序列collections.Iterable 60
15、顺序迭代合并后的排序迭代对象heapq.merge() 61
16、迭代器替代while无限循环 62
七、函数 63
1、可接受任意数量参数的函数 64
2、只接受关键字参数的函数 64
3、给函数参数增加元信息 65
4、返回多个值的函数 66
5、定义有默认参数的函数 66
6、定义匿名函数或内联函数 68
7、匿名函数捕获变量值 68
8、减少可调用对象的参数个数functools.partial() 69
9、将单方法的类转换为函数(闭包) 70
10、带额外状态信息的回调函数 70
11、内联回调函数 72
12、访问闭包中定义的变量 72
十三、脚本编程与系统管理 73
1、通过重定向|管道|文件接受输入fileinput.input() 73
2、终止程序并给出错误信息raise 74
3、解析命令行选项argparse 74
4、运行时弹出密码输入提示getpass 76
5、获取终端的大小os.get_terminal_size() 76
6、执行外部命令并获取它的输出subprocess.check_output() 77
7、复制或移动文件或目录shutil 78
8、创建和解压归档文件shutil.make_archive()|shutil.unpack_archive() 79
9、通过文件名查找文件os.walk() 80
10、读取.ini配置文件configparser.ConfigParser 81
11、给简单脚本增加日志功能logging 83
12、给函数库增加日志功能logging 85
13、实现一个计时器time.perf_counter() 86
14、限制内存和cpu的使用量resource.getrlimit()|resource.setrlimit() 87
15、启动一个web浏览器webbrowser 87
八、类与对象 88
1、改变对象的字符串显示__str__()|__repr__() 88
2、自定义字符串的格式化__format__() 89
3、让对象支持上下文管理协议__enter__()|__exit__()|contextmanager 89
4、创建大量对象时节省内存的方法__slots__ 91
5、在类中封装属性名_ 92
6、创建可管理的属性@property 93
7、调用父类的方法super() 94
8、子类中扩展property 95
9、创建新的类或实例属性__get__()|__set__()|__delete__() 96
10、使用延迟计算特性_描述器类 97
11、简化数据结构的初始化 98
12、定义接口或抽象基类abc 98
13、实现数据模型的类型约束 99
五、文件与IO 99
1、读写文本数据open() 99
2、打印输出至文件中print('content', file=f) 100
3、使用其它分隔符或行终止符打印print('content', sep=',', end='!!\n') 100
4、读写字节数据open() 100
5、文件不存在才能写入open() 102
6、字符串的I/O操作io.StringIO()|io.BytesIO() 102
7、读写压缩文件gzip.open()|bz2.open() 103
8、固定大小记录的文件迭代functools.partial()|iter() 103
9、读取二进制数据到可变缓冲区中_f.readinto() 103
10、内存映射的二进制文件mmap 104
11、文件路径名的操作os.path中的函数 104
12、测试文件是否存在os.path.exists() 105
13、获取目录中的文件列表os.listdir() 105
14、忽略文件名编码 106
15、打印不合法的文件名 107
16、增加或改变已打开文件的编码io.TextIOWrapper() 107
17、将字节写入文本文件 107
18、将文件描述符包装成文件对象 107
19、创建临时文件和文件夹tempfile.TemporaryFile|tempfile.NamedTemporaryFile|tempfile.TemporaryDirectory 108
20、与串行端口的数据通信serial 109
21、序列化py对象pickle 109
六、数据编码和处理 110
1、读写csv数据csv.reader()|csv.DictReader()|csv.writer()|csv.DictWriter() 110
2、读写json数据json.dumps()|json.loads() 113
3、解析简单的xml数据xml.etree.ElementTree.parse() 115
4、增量式解析大型xml文件xml.etree.ElementTruee.iterparse() 115
5、将字典转为xmlxml.etree.ElementTruee.Element 115
6、解析和修改xmlxml.etree.ElementTree.parse()|xml.etree.ElementTree.Element 115
7、利用命名空间解析xml文档 115
8、与关系型数据库的交互 116
9、编码解码16进制数binascii.b2a_hex()|binascii.a2b_hex()|base64.b16encode()|base64.b16decode() 116
10、编码解码base64数据base64.b64encode()|base64.b64decode() 117
11、读写二进制数组数据struct 117
12、读取嵌套和可变长二进制数据struct 117
13、数据的累加与统计操作pandas 118
一、数据结构和算法:
1、解压序列赋值给多个变量
p = (4,5)
x, y = p
_, x = p # _或ign为废弃名称
record = ('ACME', 50, 123.45, (12,18,2012))
name, *_, (*_, year) = record
2、解压可迭代对象赋值给多个变量
record = ('Dave', 'dave@example.com', '4524510', '4527926')
name, email, *phone_numbers = record #phone_numbers为list
*trailing, current = [10,8.7,1,9,5.10,1] # current为1
3、保留最后N个元素collections.deque
from collections import deque
deque(maxlen=N) # 新建一个固定大小的队列,当新的元素加入且这个队列已满时,最老的元素会自动被移除掉;虽列表也能实现,但这个方案更优雅运行更快,在队列两端插入或删除时间复杂度都是O(1),而在列表的开头插入或删除时间复杂度是O(N)
In [8]: from collections import deque
In [9]: q = deque(maxlen=3)
In [10]: q.append(1)
In [11]: q.append(2)
In [12]: q.append(3)
In [13]: q
Out[13]: deque([1, 2, 3])
In [14]: q.append(4)
In [15]: q
Out[15]: deque([2, 3, 4])
In [16]: q.appendleft(5)
In [17]: q
Out[17]: deque([5, 2, 3])
4、查找最大或最小的N个元素heapq.nlargest|nsmallest
from heapq import nlargest, nsmallest # 底层使用堆排序,适合于要查找的元素相对较少时;若仅想查找唯一的最大或最小元素,使用min()和max()更快;如果要查找的元素和集合中的元素相当,用sorted(items)[:N]更快

In [18]: from heapq import nsmallest,nlargest
In [19]: lst = [1,2,3,4,5,6,7,8]
In [20]: nlargest(3,lst)
Out[20]: [8, 7, 6]
In [21]: nsmallest(3,lst)
Out[21]: [1, 2, 3]

5、实现一个优先级队列heapq.heappush()|heapq.heappop()
实现一个按优先级排序的队列,且在这个队列上每次pop()总是返回优先级最高的那个元素;
heapq.heappush(heap, item) -> None. Push item onto heap, maintaining the heap invariant.
heapq.heappop().
push和pop操作时间复杂度为O(logN),N是堆的大小,因此即使N很大运行速度仍然很快;
结合下例,这2函数分别在队列_queue上插入和删除第一个元素,且队列_queue保证第一个元素拥有最小优先级,因为heapq.heappop()返回的结果是最高优先级;
若要在多线程中使用同一个队列,需要增加适当的锁和信号量机制;
In [178]: import heapq
In [179]: class PriorityQueue:
...: def __init__(self):
...: self._queue = []
变量的作用是保证同等优先级元素的正确排序,通过保存一个不断增加的下标变量,可确保元素按照它们插入的顺序排序,且_index变量也在相同优先级元素比较时起到重要作用
...: def push(self, item, priority):
元组中,优先级为负数的目的是使得元素按照优先级从高到低排序,这跟普通的按优先级从低到高排序的堆排序恰巧相反;
...: self._index += 1
...: def pop(self):
...: return heapq.heappop(self._queue)[-1]
...:
In [180]: class Item: #该实例不可排序,若Item('foo') < Item('bar')会出错;但(1, Item('foo'))< (5, Item('bar'))则可以,如果(1, Item('foo')) < (1, Item('bar'))会报错,通过再引入index则避免这个报错,(1, 0, Item('foo')) < (1,1,Item('bar'))
...: def __init__(self, name):
...: self.name = name
...: def __repr__(self):
...: return 'Item({!r})'.format(self.name)
...:
In [181]: q = PriorityQueue()
In [182]: q.push(Item('foo'), 1)
In [183]: q.push(Item('bar'), 5)
In [184]: q.push(Item('span'), 4)
In [185]: q.push(Item('grok'), 1)
In [186]: q.pop()
Out[186]: Item('bar')
In [187]: q.pop()
Out[187]: Item('span')
In [188]: q.pop()
Out[188]: Item('foo')
In [189]: q.pop()
Out[189]: Item('grok')
6、字典中的键映射多个值(multidict)collections.defaultdict
用途:数据处理中的记录归类;
from collections import defaultdict
In [26]: from collections import defaultdict
In [27]: d = defaultdict(list)
In [28]: d['a'].append(1)
In [29]: d['a'].append(2)
In [30]: d['b'].append(4)
In [31]: d
Out[31]: defaultdict(list, {'a': [1, 2], 'b': [4]})
In [32]: d2 = defaultdict(set)
In [33]: d2['a'].add(1)
In [34]: d2['a'].add(2)
In [35]: d2['b'].add(4)
In [36]: d2
Out[36]: defaultdict(set, {'a': {1, 2}, 'b': {4}})
In [40]: d
Out[40]: {}
In [41]: d.setdefault('a',[]).append(1)
In [42]: d.setdefault('a',[]).append(2)
In [43]: d.setdefault('b',[]).append(4)
In [44]: d
Out[44]: {'a': [1, 2], 'b': [4]}
7、字典排序(有序字典)collections.OrderedDict
用途:精确控制以josn编码后字段的顺序
from collections import OrderedDict # 内部维护着一个双向链表,且该大小是普通字典的2倍,要考虑消耗内存情况
In [46]: d = OrderedDict()
In [47]: d['foo']=1
In [48]: d['bar']=2
In [49]: d['span']=3
In [50]: d['grok']=4
In [51]: d
Out[51]: OrderedDict([('foo', 1), ('bar', 2), ('span', 3), ('grok', 4)])
8、字典运算
在字典中执行计算(最小值|最大值|排序等)
在一个字典上执行普通的数学运算,仅能作用于键,而不能作用于值,对于如下场景使用zip()将值和键反转;
当通过zip()将字典的key和value反转后,在使用min()或max()计算时,若有多个value相同,再去比较key;
In [53]: prices = {
...: 'ACME': 45.23,
...: 'AAPL': 612.78,
...: 'IBM': 205.55,
...: 'HPQ': 37.20,
...: 'FB': 10.75
...: }
In [54]: min_price = min(zip(prices.values(), prices.keys()))
InIn [55]: min_price
Out[55]: (10.75, 'FB')
In [56]: max_price = max(zip(prices.values(), prices.keys()))
In [57]: max_price
Out[57]: (612.78, 'AAPL')
In [59]: zip(prices.values(), prices.keys())
Out[59]: <zip at 0x256bc2eda88>
In [60]: iter(zip(prices.values(), prices.keys()))
Out[60]: <zip at 0x256bc3741c8>
In [61]: for i in zip(prices.values(), prices.keys()): # zip()创建的是一个只能访问一次的迭代器
...: print(i)
...:
(45.23, 'ACME')
(612.78, 'AAPL')
(205.55, 'IBM')
(37.2, 'HPQ')
(10.75, 'FB')
In [64]: min(prices.values())
Out[64]: 10.75
In [65]: max(prices.values())
Out[65]: 612.78
In [66]: min(prices)
Out[66]: 'AAPL'
In [67]: max(prices)
Out[67]: 'IBM'
In [68]: min(prices, key=lambda k: prices[k]) # 通过key参数可对字典的值进行计算,而返回字典的key信息
Out[68]: 'FB'
In [69]: max(prices, key=lambda k: prices[k])
Out[69]: 'AAPL'
In [70]: prices = { # 当value相同时,才比较key
...: 'AAA': 45.23,
...: 'ZZZ': 45.23
...: }
In [71]: min(zip(prices.values(), prices.keys()))
Out[71]: (45.23, 'AAA')
In [72]: max(zip(prices.values(), prices.keys()))
Out[72]: (45.23, 'ZZZ')
9、查找2字典的相同点
在2字典的keys()和items()结果上执行集合操作;
字典的key,有一特性是也支持集合操作,不用先转换成一个set,用.keys()直接进行操作;
字典的.items()方法返回(k,v),这个对象也支持集合操作;
字典的.values()不支持集合操作,原因不能保证所有值是不相同的,要先转为set再进行集合操作;
In [74]: a = {
...: 'x': 1,
...: 'y': 2,
...: 'z': 3
...: }
In [75]: b = {
...: 'w': 10,
...: 'x': 11,
...: 'y': 2
...: }
In [76]: a.keys()
Out[76]: dict_keys(['x', 'y', 'z'])
In [77]: b.keys()
Out[77]: dict_keys(['w', 'x', 'y'])
In [78]: a.keys() & b.keys()
Out[78]: {'x', 'y'}
In [79]: a.keys() - b.keys()
Out[79]: {'z'}
In [80]: a.items() & b.items()
Out[80]: {('y', 2)}
In [82]: {k:a[k] for k in a.keys() - {'z', 'w'}} #字典生成式
Out[82]: {'x': 1, 'y': 2}
10、删除序列中相同元素并保持顺序
对于可hash的值:
def dedupe(items):
seen = set()
for item in items:
if item not in seen:
yield item #使用生成器函数,使得更加通用,不仅仅局限于列表处理,也可用于读取文件消除重复行
seen.add(item)
In [88]: def dedupe(items):
...: seen = set()
...: for item in items:
...: if item not in seen:
...: yield item
...: seen.add(item)
...:
In [89]: a = [1,5,2,1,9,1,2,5,10]
In [90]: list(dedupe(a))
Out[90]: [1, 5, 2, 9, 10]
对于不可hash的值:
In [91]: def dedupe(items, key=None):
...: seen = set()
...: for item in items:
...: val = item if key is None else key(item)
...: if val not in seen:
...: yield item
...: seen.add(val)
...:
In [92]: a = [{'x':1, 'y':2},{'x':1,'y':3},{'x':1,'y':2},{'x':2,'y':4}]
In [93]: list(dedupe(a,key=lambda d: (d['x'],d['y'])))
Out[93]: [{'x': 1, 'y': 2}, {'x': 1, 'y': 3}, {'x': 2, 'y': 4}]
In [94]: list(dedupe(a, key=lambda d: d['x'])) # 适合场景:基于某个字段|属性,或更大的数据结构来消除重复元素
Out[94]: [{'x': 1, 'y': 2}, {'x': 2, 'y': 4}]
In [96]: a = [1,5,2,1,9,1,2,5,10]
In [97]: set(a) # 若仅是消除重复元素,用集合,这种不能维护元素的顺序
Out[97]: {1, 2, 5, 9, 10}
11、命名切片slice(start,stop,step)
避免大量无法理解的硬编码下标,使代码更加清晰可读;
slice(start, stop[, step])内置函数,创建一个切片对象,可被用作任何切片允许使用的地方,通过.start|.stop|.step访问其属性;
In [101]: record='....................100 .......513.25 ..........'
In [102]: SHARES = slice(20,23)
In [103]: PRICE = slice(31,37)
In [104]: cost = int(record[SHARES]) * float(record[PRICE])
In [105]: cost
Out[105]: 51325.0
In [106]: SHARES
Out[106]: slice(20, 23, None)
In [107]: PRICE
Out[107]: slice(31, 37, None)
In [108]: record[SHARES]
Out[108]: '100'
In [110]: a = slice(5,50,2)
In [111]: a.start
Out[111]: 5
In [112]: a.stop
Out[112]: 50
In [113]: a.step
Out[113]: 2
12、序列中出现次数最多的元素collections.Counter
from collections import Counter # Counter对象可接受任意的hashable序列对象,底层实现上一个Counter对象就是一个字典,将元素映射到它出现的次数上;
用途:Counter对象几乎所有需要制表或计数数据的场合都可用,且优先选择使用Counter,而不是手动的利用字典实现;
In [116]: words = [
...: 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
...: 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
...: 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
...: 'my', 'eyes', "you're", 'under'
...: ]
In [117]: from collections import Counter
In [118]: word_counts = Counter(words)
In [119]: word_counts #若要手动增加计数,用word_counts['no']+=1或update()方法
Out[119]:
Counter({'look': 4,
'into': 3,
'my': 3,
'eyes': 8,
'the': 5,
'not': 1,
'around': 2,
"don't": 1,
"you're": 1,
'under': 1})
In [120]: top_three = word_counts.most_common(3)
In [121]: top_three
Out[121]: [('eyes', 8), ('the', 5), ('look', 4)]
13、通过某个关键字排序一个字典列表operator.itemgetter
from operator import itemgetter
In [126]: rows = [
...: {'fname': 'Brian', 'lname': 'Jones', 'uid': 1003},
...: {'fname': 'David', 'lname': 'Beazley', 'uid': 1002},
...: {'fname': 'John', 'lname': 'Cleese', 'uid': 1001},
...: {'fname': 'Big', 'lname': 'Jones', 'uid': 1004}
...: ]
In [127]: rows_by_fname = sorted(rows, key=itemgetter('fname')) #同lambda表达式rows_by_fname = sorted(rows, key=lambda r: r['fname']),itemgetter()效率更高且支持多个key比较;sorted()或min()或max()
In [128]: rows_by_fname
Out[128]:
[{'fname': 'Big', 'lname': 'Jones', 'uid': 1004},
{'fname': 'Brian', 'lname': 'Jones', 'uid': 1003},
{'fname': 'David', 'lname': 'Beazley', 'uid': 1002},
{'fname': 'John', 'lname': 'Cleese', 'uid': 1001}]
In [129]: rows_by_uid = sorted(rows, key=itemgetter('uid'))
In [130]: rows_by_uid
Out[130]:
[{'fname': 'John', 'lname': 'Cleese', 'uid': 1001},
{'fname': 'David', 'lname': 'Beazley', 'uid': 1002},
{'fname': 'Brian', 'lname': 'Jones', 'uid': 1003},
{'fname': 'Big', 'lname': 'Jones', 'uid': 1004}]
In [131]: rows_by_lfname = sorted(rows, key=itemgetter('lname','fname')) # itemgetter()支持多个key
In [132]: rows_by_lfname
Out[132]:
[{'fname': 'David', 'lname': 'Beazley', 'uid': 1002},
{'fname': 'John', 'lname': 'Cleese', 'uid': 1001},
{'fname': 'Big', 'lname': 'Jones', 'uid': 1004},
{'fname': 'Brian', 'lname': 'Jones', 'uid': 1003}]
14、排序不支持原生比较的对象operator.attrgetter
from operator import attrgetter
In [135]: class User:
...: def __init__(self, user_id):
...: self.user_id = user_id
...: def __repr__(self):
...: return 'User({})'.format(self.user_id)
...:
In [136]: users = [User(23),User(3),User(99)]
In [137]: sorted(users, key=lambda u: u.user_id)
Out[137]: [User(3), User(23), User(99)]
In [138]: from operator import attrgetter
In [139]: sorted(users, key=attrgetter('user_id'))
Out[139]: [User(3), User(23), User(99)]
15、通过某个字段将记录分组itertools.groupby
from operator import itemgetter
from itertools import groupby
groupby()扫描整个序列并且查找连续相同值的元素序列,在每次迭代时,它会返回一个值和一个迭代器对象;
一个重要准备是先要根据指定的字段将数据排序,因为groupby()仅检查连续的元素;
In [140]: rows = [
...: {'address': '5412 N CLARK', 'date': '07/01/2012'},
...: {'address': '5148 N CLARK', 'date': '07/04/2012'},
...: {'address': '5800 E 58TH', 'date': '07/02/2012'},
...: {'address': '2122 N CLARK', 'date': '07/03/2012'},
...: {'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},
...: {'address': '1060 W ADDISON', 'date': '07/02/2012'},
...: {'address': '4801 N BROADWAY', 'date': '07/01/2012'},
...: {'address': '1039 W GRANVILLE', 'date': '07/04/2012'},
...: ]
In [142]: rows.sort(key=itemgetter('date')) # 先按指定的字段排序,再调用groupby()
In [145]: for date, items in groupby(rows, key=itemgetter('date')):
...: print(date)
...: for i in items:
...: print(' ', i)
...:
07/01/2012
{'address': '5412 N CLARK', 'date': '07/01/2012'}
{'address': '4801 N BROADWAY', 'date': '07/01/2012'}
07/02/2012
{'address': '5800 E 58TH', 'date': '07/02/2012'}
{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'}
{'address': '1060 W ADDISON', 'date': '07/02/2012'}
07/03/2012
{'address': '2122 N CLARK', 'date': '07/03/2012'}
07/04/2012
{'address': '5148 N CLARK', 'date': '07/04/2012'}
{'address': '1039 W GRANVILLE', 'date': '07/04/2012'}
In [146]: from collections import defaultdict #若仅仅是想根据date字段将数据分组到一个大的数据结构中去,且允许随机访问,用defaultdict()来构建一个多值字典,有用先对rows进行排序
In [147]: rows_by_date = defaultdict(list)
In [148]: rows_by_date
Out[148]: defaultdict(list, {})
In [149]: rows
Out[149]:
[{'address': '5412 N CLARK', 'date': '07/01/2012'},
{'address': '4801 N BROADWAY', 'date': '07/01/2012'},
{'address': '5800 E 58TH', 'date': '07/02/2012'},
{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},
{'address': '1060 W ADDISON', 'date': '07/02/2012'},
{'address': '2122 N CLARK', 'date': '07/03/2012'},
{'address': '5148 N CLARK', 'date': '07/04/2012'},
{'address': '1039 W GRANVILLE', 'date': '07/04/2012'}]
In [150]: for row in rows:
...: rows_by_date[row['date']].append(row)
...:
In [151]: rows_by_date
Out[151]:
defaultdict(list,
{'07/01/2012': [{'address': '5412 N CLARK', 'date': '07/01/2012'},
{'address': '4801 N BROADWAY', 'date': '07/01/2012'}],
'07/02/2012': [{'address': '5800 E 58TH', 'date': '07/02/2012'},
{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},
{'address': '1060 W ADDISON', 'date': '07/02/2012'}],
'07/03/2012': [{'address': '2122 N CLARK', 'date': '07/03/2012'}],
'07/04/2012': [{'address': '5148 N CLARK', 'date': '07/04/2012'},
{'address': '1039 W GRANVILLE', 'date': '07/04/2012'}]})
In [152]: for r in rows_by_date['07/02/2012']:
...: print(r)
...:
{'address': '5800 E 58TH', 'date': '07/02/2012'}
{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'}
{'address': '1060 W ADDISON', 'date': '07/02/2012'}
16、过滤序列元素
列表推导(列表生成式),缺陷长度很长时占内存;
生成器表达式;
列表推导和生成器表达式是过滤数据最简单的方式,还可在过滤时转换数据;过滤操作的一个变种就是将不符合条件的值用新的值代替而不是丢弃它们,如在一列数据中不仅想要正数,且还想将不是正数的数替换成指定的数;
过滤规则复杂时(如过滤时需要处理一些异常或其它复杂情况),将过滤代码放到一个函数中,使用内建filter()函数;
In [153]: lst = [1,4,-5,10,-7,2,3,-1]
In [154]: [n for n in lst if n>0]
Out[154]: [1, 4, 10, 2, 3]
In [155]: [n for n in lst if n<0]
Out[155]: [-5, -7, -1]
In [156]: pos = (n for n in lst if n>0)
In [157]: pos
Out[157]: <generator object <genexpr> at 0x00000256BC2A8888>
In [158]: for x in pos:
...: print(x)
...:
1
4
10
2
3
In [159]: values = ['1','2','-3','-','4','N/A','5']
In [160]: def is_int(val):
...: try:
...: x = int(val)
...: return True
...: except ValueError:
...: return False
...:
In [161]: ivals = list(filter(is_int, values)) #filter()创建一个迭代器
In [162]: ivals
Out[162]: ['1', '2', '-3', '4', '5']
In [166]: lst = [1,4,-5,10,-7,2,3,-1]
In [167]: import math
In [168]: [math.sqrt(n) for n in lst if n>0]
Out[168]: [1.0, 2.0, 3.1622776601683795, 1.4142135623730951, 1.7320508075688772]
In [169]: clip_neg = [n if n>0 else 0 for n in lst]
In [170]: clip_neg
Out[170]: [1, 4, 0, 10, 0, 2, 3, 0]
In [171]: addresses = [
...: '5412 N CLARK',
...: '5148 N CLARK',
...: '5800 E 58TH',
...: '2122 N CLARK'
...: '5645 N RAVENSWOOD',
...: '1060 W ADDISON',
...: '4801 N BROADWAY',
...: '1039 W GRANVILLE',
...: ]
In [172]: counts = [ 0, 3, 10, 4, 1, 7, 6, 1]
In [173]: from itertools import compress
In [174]: more5 = [n>5 for n in counts]
In [175]: more5
Out[175]: [False, False, True, False, False, True, True, False]
In [176]: list(compress(addresses, more5)) # compress()也是返回一个迭代器
Out[176]: ['5800 E 58TH', '4801 N BROADWAY', '1039 W GRANVILLE']
17、从字典中提取子集:
字典推导,或通过创建一个元组序列然后把它传给dict(),字典推导要比dict()运行快一倍;
In [179]: prices = {
...: 'ACME': 45.23,
...: 'AAPL': 612.78,
...: 'IBM': 205.55,
...: 'HPQ': 37.20,
...: 'FB': 10.75
...: }
In [180]: p1 = {k:v for k,v in prices.items() if v>200}
In [181]: p1
Out[181]: {'AAPL': 612.78, 'IBM': 205.55}
In [182]: tech_names = {'AAPL', 'IBM', 'HPQ', 'MSFT'}
In [183]: p2 = {k:v for k,v in prices.items() if k in tech_names}
In [184]: p2
Out[184]: {'AAPL': 612.78, 'IBM': 205.55, 'HPQ': 37.2}
In [185]: p2 = {k:prices[k] for k in prices.keys() & tech_names}
In [186]: p2
Out[186]: {'AAPL': 612.78, 'HPQ': 37.2, 'IBM': 205.55}
18、映射名称到序列元素collections.namedtuple
from collections import namedtuple
用途:
将代码从下标操作中解脱出来;
作为字典的替代,字典存储需要更多的内存空间,如果需要构建一个非常大的包含字典的数据结构,使用命名元组更加高效;
如果是要定义一个需要更新很多实例属性的高效数据结构,命名元组并不是最佳选择,可考虑定义一个包含__slots__方法的类;
注意:
命名元组不可更改,如要更改要用实例的_replace(),它会创建一个全新的命名元组并将对应的字段用新的值取代;
_replace()有用的特性,当你的命名元组拥有可选或缺失字段时,它是一个非常方便的填充数据的方法,可先创建一个包含缺少值的原型元组,然后使用_replace()创建新的值被更新过的实例;
In [187]: def compute_cost(records):
...: total = 0.0
...: for rec in records:
...: total += rec[1] * rec[2]
...: return total
In [195]: compute_cost(((8,9,10),)) #普通元组代码
Out[195]: 90.0
Stock = namedtuple('Stock', ['name', 'shares', 'price'])
In [198]: def compute_cost(records):
...: total = 0.0
...: for rec in records:
...: s = Stock(*rec)
...: total += s.shares * s.price
...: return total
In [200]: compute_cost((('jowin',88,10),)) # 使用命名元组版本
Out[200]: 880.0
In [201]: s = Stock('jowin',100,123.45)
In [202]: s
Out[202]: Stock(name='jowin', shares=100, price=123.45)
In [203]: s.shares # 不可更改,如果更改要用实例的_replace()方法
Out[203]: 100
In [204]: s = s._replace(shares=75)
In [205]: s
Out[205]: Stock(name='jowin', shares=75, price=123.45)
In [206]: Stock = namedtuple('Stock',['name','shares','price','date','time'])
In [207]: stock_prototype = Stock('', 0, 0.0, None, None)
In [208]: def dict_to_stock(s):
...: return stock_prototype._replace(**s)
...:
In [209]: a = {'name': 'ACME', 'shares': 100, 'price': 123.45}
In [210]: dict_to_stock(a)
Out[210]: Stock(name='ACME', shares=100, price=123.45, date=None, time=None)
19、转换并同时计算数据,生成器表达式
用优雅的方式,即生成器表达式,比先创建一个临时列表更加高效和优雅;
s = sum(x*x for x in nums) #这种方式更优雅;而不必sum((x*x for x in nums))多加一对括号,显式地传递一个生成器表达式对象
s = sum([x*x for x in nums]) #这种会多一步骤,即先创建一个额外的列表,当列表非常大时仅被使用一次就被丢弃,而生成器方案会以迭代的方式转换数据,因此更省内存
In [212]: nums = [1,2,3,4,5]
In [213]: s = sum(x*x for x in nums) #这种方式更优雅;而不必sum((x*x for x in nums))多加一对括号,显式地传递一个生成器表达式对象
In [214]: s
Out[214]: 55
In [217]: files = os.listdir(r'E:/')
In [221]: if any(name.endswith('.py') for name in files):
...: print('there be python')
...: else:
...: print('no python')
...:
no python
In [222]: if any(name.endswith('end') for name in files):
...: print('there be python')
...: else:
...: print('no python')
...:
there be python
In [223]: s = ('ACME',50,123,45)
In [224]: print(','.join(str(x) for x in s)) # csv
ACME,50,123,45
In [226]: portfolio = [
...: {'name':'GOOG', 'shares': 50},
...: {'name':'YHOO', 'shares': 75},
...: {'name':'AOL', 'shares': 20},
...: {'name':'SCOX', 'shares': 65}
...: ]
In [227]: min_shares = min(s['shares'] for s in portfolio)
In [228]: min_shares
Out[228]: 20
In [229]: min_shares = min(portfolio, key=lambda s: s['shares']) #min()|max()|sorted(),使用key参数更佳
In [230]: min_shares
Out[230]: {'name': 'AOL', 'shares': 20}
20、合并多个字典或映射collections.ChainMap
from collection import ChainMap # 一个ChainMap接受多个字典并将它们在逻辑上变为一个字典,然后这些字典并不是真的合并在一起了,ChainMap类只是在内部创建了一个容纳这些字典的列表并重新定义了一些常见的字典操作来遍历这个列表,大部分字典操作可用;如果有重复key,返回第一次出现的映射值;对于字典的更新或删除,始终影响的是列表中第一个字典;
若使用update()将2字典合并,要创建一个完全不同的字典对象,如果源字典做了更新,这种改变不会反应到新的合并字典中去,merged = dict(b);
ChainMap使用原来的字典,它自己不创建新的字典,源字典a中的数据更新会影响merged结果,merged = ChainMap(a, b),
用途:
对于编程中的作用域,globals|locals是非常有用的,values = ChainMap(),values['x']=1,values = values.new_child(),values= values.parents;
In [1]: from collections import ChainMap
In [2]: a = {'x':1, 'z':3}
In [3]: b = {'y':2, 'z':4}
In [4]: c = ChainMap(a,b)
In [5]: c['x']
Out[5]: 1
In [6]: c['y']
Out[6]: 2
In [7]: c['z']
Out[7]: 3
In [9]: len(c)
Out[9]: 3
In [10]: list(c.keys())
Out[10]: ['x', 'z', 'y']
In [11]: list(c.values())
Out[11]: [1, 3, 2]
In [12]: c['z'] = 10
In [13]: c['w'] = 40
In [14]: c
Out[14]: ChainMap({'x': 1, 'z': 10, 'w': 40}, {'y': 2, 'z': 4})
In [15]: del c['x']
In [16]: a
Out[16]: {'z': 10, 'w': 40}
In [17]: b
Out[17]: {'y': 2, 'z': 4}
In [18]: del c['y']
……
KeyError: "Key not found in the first mapping: 'y'"
In [19]: a
Out[19]: {'z': 10, 'w': 40}
In [20]: b
Out[20]: {'y': 2, 'z': 4}
In [22]: merged = dict(b) #创建一个新的字典对象
In [23]: merged.update(a)
In [24]: merged['z']
Out[24]: 10
In [25]: merged['y']
Out[25]: 2
In [26]: merged['w']
Out[26]: 40
In [27]: a['z'] = 8
In [28]: merged['z']
Out[28]: 10
In [29]: a
Out[29]: {'z': 8, 'w': 40}
In [30]: b
Out[30]: {'y': 2, 'z': 4}
In [31]: merged = ChainMap(a, b) #ChainMap引用原来的字典对象
In [32]: merged['z']
Out[32]: 8
In [33]: a['z'] = 88
In [34]: merged['z']
Out[34]: 88
二、字符串和文本
1、使用多个界定符分割字符串re.split()
re.split() #返回字段列表同str.split()
如果想保留分割字符,使用捕获分组;
In [35]: line = 'test test1; test2, test3,test4, test5'
In [36]: import re
In [37]: re.split(r'[;,\s]\s*', line)
Out[37]: ['test', 'test1', 'test2', 'test3', 'test4', 'test5']
In [38]: fields = re.split(r'(;|,|\s)\s*', line) #捕获分组,保留分割字符串
In [39]: fields
Out[39]: ['test', ' ', 'test1', ';', 'test2', ',', 'test3', ',', 'test4', ',', 'test5']
In [40]: values = fields[::2]
In [41]: values
Out[41]: ['test', 'test1', 'test2', 'test3', 'test4', 'test5']
In [42]: delimiters = fields[1::2] + ['']
In [43]: ''.join(v+d for v,d in zip(values, delimiters))
Out[43]: 'test test1;test2,test3,test4,test5'
In [44]: re.split(r'(?:,|;|\s)\s*', line) #获取非捕获分组,(?:)
Out[44]: ['test', 'test1', 'test2', 'test3', 'test4', 'test5']
2、字符串开头或结尾匹配str.startswith()|str.endswith()
str.startswith()
str.endswith()
可用切片实现,没上面优雅;
可用re.match('http:|https:|ftp:', url),但小材大用;
In [45]: filename = 'span.txt'
In [46]: filename.endswith('.txt')
Out[46]: True
In [47]: filename.startswith('file:')
Out[47]: False
In [48]: url = 'http://www.python.org'
In [49]: url.startswith('http:')
Out[49]: True
In [45]: filename = 'span.txt'
In [46]: filename.endswith('.txt')
Out[46]: True
In [47]: filename.startswith('file:')
Out[47]: False
In [48]: url = 'http://www.python.org'
In [49]: url.startswith('http:')
Out[49]: True
In [50]: lst = [ 'Makefile', 'foo.c', 'bar.py', 'spam.c', 'spam.h' ]
In [51]: [name for name in lst if name.endswith(('.c', '.h'))] #必须要是tuple,如果是列表,也要用tuple()转,如choices=['http:','ftp:'],name.endswith(tuple(choices))
Out[51]: ['foo.c', 'spam.c', 'spam.h']
In [53]: any(name.endswith(('.py', '.c', '.h')) for name in os.listdir(dirname)) #检查文件夹中是否存在指定的文件类型
Out[53]: True
3、用shell通配符匹配字符串fnmatch.fnmatch
from fnmatch import fnmatch, fnmatchcase #fnmatch()介于简单的字符串方法和强大的正则表达式之间;fnmatch()使用底层OS的大小写敏感规则来匹配模式,若不使用这个功能可用fnmatchcase代替
适合场景:
数据处理操作中只需要简单的通配符就能完成时;
如果代码要做文件名匹配,用glob模块;
In [56]: from fnmatch import fnmatch, fnmatchcase
In [57]: fnmatch('foo.txt','*.txt')
Out[57]: True
In [58]: fnmatch('foo.txt','?oo.txt')
Out[58]: True
In [59]: fnmatch('Dat45.csv', 'Dat[0-9]*')
Out[59]: True
In [60]: names = ['Dat1.csv','Dat2.csv','config.ini','foo.py']
In [61]: [name for name in names if fnmatch(name, 'Dat*.csv')]
Out[61]: ['Dat1.csv', 'Dat2.csv']
4、字符串匹配和搜索re.match()|re.findall()
str.find() #如果匹配的是字面字符串,调用基本字符串方法就行,另str.startswith()|str.endswith()
对于复杂的匹配使用正则表达式和re模块;
若用同一个模式做多次匹配,或要做大量的匹配和搜索时,要先将模式字符串预编译为模式对象;
re.match() #总是从字符串开始匹配
re.findall() #查找字符串任意部分的模式出现位置,以列表形式返回所有的匹配
re.finditer() #以迭代方式返回匹配
In [62]: text1 = '11/27/2019'
In [63]: re.match(r'\d+/\d+/\d+', text1)
Out[63]: <_sre.SRE_Match object; span=(0, 10), match='11/27/2019'>
In [64]: text2 = 'Nov 27, 2019'
In [66]: re.match(r'\d+/\d+/\d+', text2)
In [67]: datepat = re.compile(r'\d+/\d+/\d+')
In [68]: if datepat.match(text1):
...: print('yes')
...: else:
...: print('no')
...:
yes
In [69]: text = 'Today is 11/27/2019. PyCon starts 3/13/2019.'
In [70]: datepat.findall(text)
Out[70]: ['11/27/2019', '3/13/2019']
In [71]: datepat = re.compile(r'(\d+)/(\d+)/(\d+)') #捕获分组
In [72]: m = datepat.match('11/27/2910')
In [73]: m
Out[73]: <_sre.SRE_Match object; span=(0, 10), match='11/27/2910'>
In [74]: m.group(0)
Out[74]: '11/27/2910'
In [75]: m.group(1)
Out[75]: '11'
In [76]: m.group(2)
Out[76]: '27'
In [77]: m.group(3)
Out[77]: '2910'
In [78]: m.groups()
Out[78]: ('11', '27', '2910')
In [79]: month, day, year = m.groups()
In [80]: text
Out[80]: 'Today is 11/27/2019. PyCon starts 3/13/2019.'
In [81]: datepat.findall(text)
Out[81]: [('11', '27', '2019'), ('3', '13', '2019')]
In [82]: for m in datepat.finditer(text):
...: print(m.groups())
...:
('11', '27', '2019')
('3', '13', '2019')
5、字符串搜索和替换re.sub()
str.replace() #简单的字面模式使用
re.sub() #对于复杂模式使用,第一个参数是被匹配的模式,第二个参数是替换模式,\3指向模式中捕获组号
re.subn() #返回替换的次数
对于更加复杂的替换,可传递一个替换回调函数,回调函数的参数是一个match对象,即match()|find()返回的对象,使用group()来提取特定的匹配部分,回调函数最后返回替换字符串
In [83]: text
Out[83]: 'Today is 11/27/2019. PyCon starts 3/13/2019.'
In [84]: re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text)
Out[84]: 'Today is 2019-11-27. PyCon starts 2019-3-13.'
In [85]: datepat
Out[85]: re.compile(r'(\d+)/(\d+)/(\d+)', re.UNICODE)
In [86]: datepat.sub(r'\3-\1-\2', text)
Out[86]: 'Today is 2019-11-27. PyCon starts 2019-3-13.'
In [88]: def change_date(m):
...: mon_name = month_abbr[int(m.group(1))]
...: return '{} {} {}'.format(m.group(2), mon_name, m.group(3))
...:
In [89]: datepat.sub(change_date, text) #更复杂的使用回调函数
Out[89]: 'Today is 27 Nov 2019. PyCon starts 13 Mar 2019.'
6、字符串忽略大小写的搜索替换
In [90]: text = 'UPPER PYTHON, lower python, Mixed Python'
In [91]: re.findall('python', text, flags=re.IGNORECASE)
Out[91]: ['PYTHON', 'python', 'Python']
In [92]: re.sub('python', 'snake', text, flags=re.IGNORECASE) #不会保留原先文本中的大小写位置
Out[92]: 'UPPER snake, lower snake, Mixed snake'
In [93]: def matchcase(word):
...: def replace(m):
...: text = m.group()
...: if text.isupper():
...: return word.upper()
...: elif text.islower():
...: return word.lower()
...: elif text[0].isupper():
...: return word.capitalize()
...: else:
...: return word
...: return replace
...:
In [94]: re.sub('python', matchcase('snake'), text, flags=re.IGNORECASE) #解决原字符串中大小写位置
Out[94]: 'UPPER SNAKE, lower snake, Mixed Snake'
7、最短匹配模式.*?|.+?
* #贪婪模式,另.|+也是
*? #非贪婪模式
In [95]: str_pat = re.compile(r'\"(.*)\"')
In [96]: text = 'Computer says "no." Phone says "yes."'
In [97]: str_pat.findall(text) # 贪婪模式,结果不是我们要的
Out[97]: ['no." Phone says "yes.']
In [98]: str_pat = re.compile(r'\"(.*?)\"')
In [99]: str_pat.findall(text) # 非贪婪模式
Out[99]: ['no.', 'yes.']
8、多行匹配模式
In [100]: comment_pat = re.compile(r'/\*(.*?)\*/') #默认单行
In [101]: text = '/* this is a comment */'
In [104]: text2 = '''/* this is a
...: multiline comment */
...: '''
In [105]: comment_pat.findall(text)
Out[105]: [' this is a comment ']
In [106]: comment_pat.findall(text2)
Out[106]: []
In [107]: comment_pat = re.compile(r'/\*(.*?)\*/', re.DOTALL) #多行模式,也可用re.compile(r'/\*((?:.|\n)*?)\*/')
In [108]: comment_pat.findall(text2)
Out[108]: [' this is a \nmultiline comment ']
9、将Unicode文本标准化
import unicodedata
unicodedata.nomalize()
P53
10、正则表达式使用Unicode
P54
11、删除字符串中不需要的字符str.strip()|re.sub('\s+','',s1)
str.strip() #用于删除开始或结尾的字符,默认去除空白字符,可指定其它字符
str.lstrip()
str.rstrip()
str.replace(' ', '') #处理中间的空格
re.sub('\s+', '', s1)
with open(filename) as f:
lines = (line.strip() for line in f)
for line in lines:
print(line)
12、审查清理文本字符串
P57
13、字符串对齐format()
str.ljust() #基本的字符串对齐操作,可指定填充字符,默认空白
str.rjust()
str.center()
format() #使用<>^后跟指定的宽度;format()函数的好处是它不仅适用于字符串,还可用来格式化任何值,非常通用
In [109]: text = 'Hello world'
In [110]: text.ljust(20)
Out[110]: 'Hello world '
In [111]: text.rjust(20)
Out[111]: ' Hello world'
In [112]: text.center(20)
Out[112]: ' Hello world '
In [113]: text.center(20, '*')
Out[113]: '****Hello world*****'
In [114]: format(text, '^20')
Out[114]: ' Hello world '
In [115]: format(text, '*^20')
Out[115]: '****Hello world*****'
In [116]: '{:>10s}-{:>10s}'.format('Hello', 'World')
Out[116]: ' Hello- World'
In [117]: x = 3.1415926
In [118]: format(x, '>10')
Out[118]: ' 3.1415926'
In [119]: format(x, '^10.2f')
Out[119]: ' 3.14 '
14、合并拼接字符串join()
' '.join()
如果仅仅只是合并少数几个字符串,使用+足够;
在使用+操作符去连接大量的字符串时,是非常低效率的,因为会引起内存复制及垃圾回收操作,注意不要这样写代码:
s = ''
for p in parts:
s += p
这种写法比join()运行慢,因为每一次执行+=时会创建一个新的字符串对象,最好是先收集所有的字符串片段然后再将它们连接起来,技巧是用生成器表达式转换数据为字符串的同时合并字符串,如:
','.join(str(d) for d in data)
在没必要做连接操作时,不要用+或join(),如打印时:
print(a + ':' + b + ':' + c) #ugly
print(':'.join([a,b,c)) #ugly
print(a,b,c,sep=':') #better
在混合使用i/o操作和字符串连接操作时,根据应用程序特点来决定如何使用:
f.write(chunk1 + chunk2) #适合2个字符串很小
f.write(chunk1) #适合2个字符串很大,分开执行更高效,因为它避免了创建一个很大的临时结果且要复制大量的内存块数据
f.write(chunk2)
def sample(): #原始的生成器函数并不需要知道使用细节,它只负责生成字符串片段就行
yield 'Is'
yield 'Chicago'
yield 'Not'
yield 'Chicage?'
如果要编写构建大量小字符串的输出代码,考虑使用生成器函数,用yield语句产生输出片段,这种方法有趣的是它并没有对输出片段到底要怎样组织做出假设,可使用join()合并起来,可将字符串片段重定向到i/o,还可写一些结合i/o的混合方案;
In [120]: a = 'Hello' 'World' #将2个字面字符串合并,简单放在一起即可,可不用+
In [121]: a
Out[121]: 'HelloWorld'
15、字符串中插入变量format()|format_map()
format() #py没有对在字符串中简单替换变量值提供直接的支持,使用字符串的format()方法解决
format_map(vars()) #vars(a)可用于对象实例
'[<>ˆ]?width[,]?(.digits)?' #同时指定宽度和精度,width和digits用整数,?为可选部分
format()和format_map()缺陷是它们不能很好地处理变量缺失的情况,如s.format(name='Guido')没给n变量,解决用__missing__()方法的dict对象;
In [122]: s = '{name} has {n} messages.'
In [123]: s.format(name='Guido', n=37)
Out[123]: 'Guido has 37 messages.'
In [124]: name = 'Jowin'
In [125]: n = 18
In [126]: s.format_map(vars())如果被替换的变量能在变量域中找到,可结合format_map()和vars(),vars()也适用于对象实例
Out[126]: 'Jowin has 18 messages.'
In [127]: class Info:
...: def __init__(self, name, n):
...: self.name = name
...: self.n = n
...:
In [129]: a = Info('Guido', 37)
In [130]: s.format_map(vars(a)) #vars()用于对象实例
Out[130]: 'Guido has 37 messages.'
In [132]: class safesub(dict):
...: def __missing__(self, key):
...: return '{' + key + '}'
...:
In [133]: n
Out[133]: 18
In [134]: del n
In [137]: s.format_map(safesub(vars())) #处理变量缺失
Out[137]: 'Jowin has {n} messages.'
In [138]: import sys
In [139]: def sub(text): #若代码中频繁执行,用工具函数封装,其中sys._getframe(1)返回调用者的栈帧,f_locals获得局部变量(复制调用函数的本地变量的字典),大部分情况下直接操作栈帧不推荐,但对待字符串替换工具函数而言很有用,尽管可改变f_locals内容,但这个修改对于后面的变量访问没任何影响,所以虽访问一个栈帧看上去很邪恶但对它的任何操作不会覆盖和改变调用者本地变量的值
...: return text.format_map(safesub(sys._getframe(1).f_locals))
...:
In [140]: name = 'Guido'
In [141]: n = 3
In [142]: sub('Hello {name}')
Out[142]: 'Hello Guido'
In [143]: sub('You have {n} messages.')
Out[143]: 'You have 3 messages.'
In [144]: sub('Your favorite color is {color}')
Out[144]: 'Your favorite color is {color}'
16、以指定列宽格式化字符串textwrap.fill()
import textwrap #对字符串打印非常有用,尤其是你希望输出自动匹配终端大小时;fill()接受参数来控制tab|语句结尾等
In [145]: import os
In [146]: os.get_terminal_size().columns #获取终端大小尺寸
Out[146]: 91
In [148]: s = "Look into my eyes, look into my eyes, the eyes, the eyes, \
...: the eyes, not around the eyes, don't look around the eyes, \
...: look into my eyes, you're under."
In [149]: import textwrap
In [150]: textwrap.fill(s, 70)
Out[150]: "Look into my eyes, look into my eyes, the eyes, the eyes, the eyes,\nnot around the eyes, don't look around the eyes, look into my eyes,\nyou're under."
In [151]: textwrap.fill(s, 40)
Out[151]: "Look into my eyes, look into my eyes,\nthe eyes, the eyes, the eyes, not around\nthe eyes, don't look around the eyes,\nlook into my eyes, you're under."
In [152]: print(textwrap.fill(s, 40, initial_indent=' '))
Look into my eyes, look into my
eyes, the eyes, the eyes, the eyes, not
around the eyes, don't look around the
eyes, look into my eyes, you're under.
In [153]: print(textwrap.fill(s, 40, subsequent_indent=' '))
Look into my eyes, look into my eyes,
the eyes, the eyes, the eyes, not
around the eyes, don't look around
the eyes, look into my eyes, you're
under.
17、在字符串中处理html|xml
import html
html.escape(s1) #将字符串中的标签转为文本
from html.parser import HTMLParser
from xml.sax.saxutils import unescape
P67
In [154]: s = 'Elements are written as "<tag>text</tag>".'
In [155]: import html
In [156]: html.escape(s)
Out[156]: 'Elements are written as "<tag>text</tag>".'
In [157]: html.escape(s, quote=False)
Out[157]: 'Elements are written as "<tag>text</tag>".'
18、字符串令牌解析
re.scanner() #
P69
19、实现一个简单的递归下降分析器
P70
20、字节字符串上的字符串操作
大多数情况下,在文本字符串上的操作均可用于字节字符串;
字节字符串的索引操作返回整数而不是单独字符,这种语义上的区别对于处理面向字节的字符数据有影响;
字节字符串不会提供一个美观的字符串表示,也不能很好地打印出来,除非它们先被解码为一个文本字符串;
不存在任何适用于字节字符串的格式化操作,如果想格式化字节字符串,得先使用标准的文本字符串再将其编码为字节字符串;
尽管操作字节字符串比文本更加高效,这样做会导致非常杂乱的代码,且字节字符串并不能和py其它部分工作好,且还得处理所有编码|解码操作,所以处理文本就直接在程序中使用普通的文本字符串而不是字节字符串;
In [158]: data = b'Hello World'
In [159]: data[0:5]
Out[159]: b'Hello'
In [160]: data.startswith(b'Hello')
Out[160]: True
In [161]: data.split()
Out[161]: [b'Hello', b'World']
In [162]: data.replace(b'Hello', b'Hello Cruel')
Out[162]: b'Hello Cruel World'
In [163]: data = bytearray(b'Hello World')
In [164]: data[0:5]
Out[164]: bytearray(b'Hello')
In [166]: data.startswith(b'Hello') #常规操作也适用于字节数组
Out[166]: True
In [167]: data.split()
Out[167]: [bytearray(b'Hello'), bytearray(b'World')]
In [168]: data.replace(b'Hello', b'Hello Cruel')
Out[168]: bytearray(b'Hello Cruel World')
In [169]: data = b'FOO:BAR,SPAN'
In [170]: re.split(b'[:,]', data) #正则表达式本身也要是字符串
Out[170]: [b'FOO', b'BAR', b'SPAN']
In [171]: data = 'Hello World'
In [172]: data[0]
Out[172]: 'H'
In [173]: data1 = b'Hello World'
In [174]: data1[0]
Out[174]: 72
In [175]: data1[1]
Out[175]: 101
In [176]: data1
Out[176]: b'Hello World'
In [177]: data1.decode()
Out[177]: 'Hello World'
三、数字|日期|时间
1、数字的四舍五入round(value, ndigits)
round(value, ndigits) #对于简单的舍入运算,四舍六入五取偶
不要将舍入和格式化输出搞混淆,如果只是简单的输出一定宽度的数,不需要使用round(),仅需要在格式化时指定精度,如format(x, '0.2f')
对于可容忍的小误差不要用round(),若涉及到金融领域要用decimal模块;
In [192]: round(1.23, 1)
Out[192]: 1.2
In [193]: round(1.27, 1)
Out[193]: 1.3
In [194]: round(-1.27, 1)
Out[194]: -1.3
In [195]: round(1.23456, 3)
Out[195]: 1.235
In [198]: round(1.5) #四舍六入五取偶
Out[198]: 2
In [199]: round(2.5) #四舍六入五取偶
Out[199]: 2
In [200]: round(12345, -1) #ndigits为负数,则会作用在十位|百位|千位上
Out[200]: 12340
In [201]: round(12345, -2)
Out[201]: 12300
In [202]: x = 1.2345
In [203]: format(x, '0.2f')
Out[203]: '1.23'
2、执行精确的浮点数运算
浮点数的一个普遍问题是不能精确表示十进制数,且即使是最简单的数学运算也会产生小误差,如4.2 + 2.1 == 6.3为False,这些错误是由底层cpu和IEEE754标准通过自己的浮点单位去执行算术时的特征;
from decimal import Decimal #若想更精确,并能容忍一定的性能损耗使用该模块;decimal模块的一个主要特征是允许控制计算的每一方面,包括数字位数和四舍五入运算,前提是要创建一个本地上下文并更改它的配置用from decimal import localcontext
from decimal import localcontext
使用注意:
看应用程序的目的;
如果是科学计算或工程领域的计算|电脑绘图,使用普通的浮点类型是普遍的做法,原因1在真实世界中很少会要求精确到普通浮点数能提供的17位精度(小误差是被允许的),原因2原生的浮点数运算速度要快得多;
金融领域,计算过程中的小误差不允许,decimal为解决这类问题提供了方法,另py和数据库打交道时也会用Decimal对象也是在处理金融数据时;
In [204]: 4.2 + 2.1 == 6.3
Out[204]: False
In [206]: a = Decimal('4.2') #用字符串来表示数字,Decimal对象会像普通浮点数一样工作,跟普通数字没什么两样
In [207]: b = Decimal('2.1')
In [208]: a + b
Out[208]: Decimal('6.3')
In [209]: (a + b) == Decimal('6.3')
Out[209]: True
In [218]: a = Decimal('1.3')
In [219]: b = Decimal('1.7')
In [220]: a / b
Out[220]: Decimal('0.7647058823529411764705882353')
In [221]: with localcontext() as ctx:
...: ctx.prec = 3
...: print(a / b)
...:
0.765
3、数字的格式化输出format()
format()
'[<>ˆ]?width[,]?(.digits)?' #同时指定宽度和精度,width和digits用整数,?为可选部分
In [222]: x = 1234.56789
In [223]: format(x, '0.2f')
Out[223]: '1234.57'
In [224]: format(x, '>10.1f')
Out[224]: ' 1234.6'
In [225]: format(x, '<10.1f')
Out[225]: '1234.6 '
In [226]: format(x, '^10.1f')
Out[226]: ' 1234.6 '
In [227]: format(x, ',') #Inclusion of thousands separator
Out[227]: '1,234.56789'
In [228]: format(x, '0,.1f')
Out[228]: '1,234.6'
In [229]: format(x, 'e')
Out[229]: '1.234568e+03'
In [230]: format(x, '0.2E')
Out[230]: '1.23E+03'
4、二|八|十六进制整数
bin(x) #整数转为二进制,另format(x, 'b')格式输出没有Ob|Oo|Ox
oct(x) #整数转为十进制,另format(x, 'o')
hex(x) #整数转为十六进制,另format(x, 'x')
int(x, 2) #各进制转为整数
int(x, 8)
int(x, 16)
注,py代码中使用八进制用Oo755,如:
os.chmod('script.py', Oo755)
In [231]: x = 1234
In [232]: bin(x)
Out[232]: '0b10011010010'
In [233]: oct(x)
Out[233]: '0o2322'
In [234]: hex(x)
Out[234]: '0x4d2'
In [235]: format(x, 'b')
Out[235]: '10011010010'
In [236]: format(x, 'o')
Out[236]: '2322'
In [237]: format(x, 'x')
Out[237]: '4d2'
5、字节到大整数的打包与解包
int.from_bytes() #将bytes解析为整数
int.to_bytes() #将大整数转为字节字符串
用途:
密码学;
网络;
P88
6、复数的数学运算cmath|numpy
复数用complex(real, imag),或是带有后缀j的浮点数来指定;
import cmath #cmath.sin(a)正弦|cmath.cos(a)余弦|cmath.exp(a)平方根,py的标准数学函数math不能产生复数值,要用cmath
import numpy #py中大部分与数学相关的模块都能处理复数
In [239]: a = complex(2,4)
In [240]: a
Out[240]: (2+4j)
In [241]: b = 3 - 5j
In [242]: b
Out[242]: (3-5j)
In [243]: a.real #实部
Out[243]: 2.0
In [245]: a.imag #虚部
Out[245]: 4.0
In [246]: a.conjugate() #共轭复数
Out[246]: (2-4j)
In [247]: a + b #常见的数学运算
Out[247]: (5-1j)
In [248]: a * b
Out[248]: (26+2j)
In [249]: a / b
Out[249]: (-0.4117647058823529+0.6470588235294118j)
In [250]: abs(a)
Out[250]: 4.47213595499958
In [252]: cmath.sin(a)
Out[252]: (24.83130584894638-11.356612711218174j)
In [253]: cmath.cos(a)
Out[253]: (-11.36423470640106-24.814651485634187j)
In [254]: cmath.exp(a)
Out[254]: (-4.829809383269385-5.5920560936409816j)
In [9]: cmath.sqrt(-1) #不能用math.sqrt(-1)
Out[9]: 1j
In [1]: import numpy as np
In [2]: a = np.array([2+3j, 4+5j, 6-7j, 8+9j])
In [3]: a
Out[3]: array([2.+3.j, 4.+5.j, 6.-7.j, 8.+9.j])
In [4]: a + 2
Out[4]: array([ 4.+3.j, 6.+5.j, 8.-7.j, 10.+9.j])
In [5]: np.sin(a)
Out[5]:
array([ 9.15449915 -4.16890696j, -56.16227422 -48.50245524j,
-153.20827755-526.47684926j, 4008.42651446-589.49948373j])
7、无穷大与NaN
py没有特殊的语法来表示正无穷|负无穷|NaN非数字,这些特殊的浮点值,可用float()来创建它们;
为测试这些值的存在,用math.isinf()|math.isnan()
无穷大数在执行数学计算时会传播;
有些操作未定义时会返回NaN结果;
NaN值会在所有操作中传播,而不会产生异常;
NaN值的一个特别地方是,它们之间的比较操作总是返回False,如a = float('nan'),b=float('nan'),a == b结果为False,测试一个NaN值唯一案例的方法就是用math.isnan();
In [10]: a = float('inf')
In [11]: b = float('-inf')
In [12]: c = float('nan')
In [13]: a
Out[13]: inf
In [14]: b
Out[14]: -inf
In [15]: c
Out[15]: nan
In [16]: math.isinf(a)
Out[16]: True
In [17]: math.isinf(b)
Out[17]: True
In [18]: math.isnan(c)
Out[18]: True
8、分数运算fractions.Fraction
from fractions import Fraction
In [19]: from fractions import Fraction
In [20]: a = Fraction(5,4)
In [21]: b = Fraction(7,16)
In [22]: a + b
Out[22]: Fraction(27, 16)
In [23]: print(a * b)
35/64
In [24]: c = a * b
In [25]: c.numerator #分子
Out[25]: 35
In [26]: c.denominator #分母
Out[26]: 64
In [27]: float(c)
Out[27]: 0.546875
In [28]: c.limit_denominator(8)
Out[28]: Fraction(4, 7)
9、大型数组运算numpy
import numpy as np #涉及到数组的重量级运算操作使用
数组的基本数学运算和np.array()不相同,np中的标量运算ax * 2或ax + 10会作用在每一个元素上,另当两个操作数都是数组时执行元素对等位置计算,并最终生成一个新数组;
底层实现中,np使用了C或Fortran语言的机制分配内存,即它们是一个非常大的连续的并由同类型数据组成的内存区域,所以可以构造一个比普通py列表大得多的数组,如10000*10000的浮点数二维网络,很轻松grid = np.zeros(shape=(10000,10000), dtype=float),所有普通操作会作用在所有元素上;
np还为数组提供了大量的通用函数,可作为math模块中类似函数的替代,如np.sqrt(ax)|np.cos(ax),使用这些通用函数比循环数组并使用math中的函数要快得多;
np扩展了py列表的索引功能,特别对于多维数组;
P96
np是py领域中很多科学与工程库的基础,同时也是被使用的最大最复杂的模块;
In [29]: x = [1,2,3,4]
In [30]: y = [5,6,7,8]
In [31]: x * 2
Out[31]: [1, 2, 3, 4, 1, 2, 3, 4]
In [32]: x + 10
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-32-dacbb30d0a09> in <module>
----> 1 x + 10
TypeError: can only concatenate list (not "int") to list
In [33]: x + y
Out[33]: [1, 2, 3, 4, 5, 6, 7, 8]
In [34]: ax = np.array([1,2,3,4])
In [35]: ay = np.array([5,6,7,8])
In [36]: ax * 2
Out[36]: array([2, 4, 6, 8])
In [37]: ax + 10
Out[37]: array([11, 12, 13, 14])
In [38]: ax + ay
Out[38]: array([ 6, 8, 10, 12])
In [39]: def compute(x):
...: return 3*x**2 - 2*x +7
...:
In [40]: compute(ax) #对整个数组中所有元素同时执行数学运算,可使作用在整个数组上的函数运算简单而又快速
Out[40]: array([ 8, 15, 28, 47])
10、矩阵np.matrix()与线性代数运算
P98
11、随机选择random
random.choice(values) #从序列中随机抽取一个元素
random.sample(values, N) #取出N个不同元素的样本
random.shuffle(values) #打乱序列中元素的顺序
random.randint(0, 10) #生成随机整数
random.random() #生成0-1间均匀分布的浮点数
random.getrandbits(N) #获取N位随机位(二进制)的整数
random模块使用Mersenne Twister算法来计算生成随机数,这是一个确定性算法,但可通过random.seed()函数修改初始化种子,另random.uniform()计算均匀分布随机数,random.gauss()计算正态分布随机数;
random模块中的函数不应该运用在和密码学相关的程序中,如果需要类似功能用ssl模块中相应的函数,如ssl.RAND_bytes()可用来生成一个安全的随机字节序列;
In [41]: values = [1,2,3,4,5,7,8,9,0]
In [42]: import random
In [43]: random.sample(values,3)
Out[43]: [4, 9, 0]
In [44]: random.shuffle(values)
In [45]: values
Out[45]: [3, 5, 8, 1, 4, 9, 7, 2, 0]
In [47]: random.randint(0, 10)
Out[47]: 6
In [48]: random.random()
Out[48]: 0.2628917920338606
In [50]: random.getrandbits(200)
Out[50]: 76134847683099961136659355408455319108262615944016521037256
12、基本的日期与时间转换datetime|dateutil
from datetime import timedelta #时间段,参数中没有月份,用relativedelta()
timedelta(days=0, secnotallow=0, microsecnotallow=0, millisecnotallow=0, minutes=0, hours=0, weeks=0)
from datetime import datetime #会自动处理闰年,对大多数基本的日期和时间处理datetime足够,处理更复杂的日期用dateutil
pip install python-dateutil
from dateutil.relativedelta import relativedelta #处理更复杂的日期操作,如时区|模糊时间范围|节假日计算,relativedelta()处理月份时填充间隙
In [52]: from datetime import timedelta
In [53]: a = timedelta(days=2, hours=6)
In [54]: b = timedelta(hours=4.5)
In [55]: c = a + b
In [56]: c.days
Out[56]: 2
In [57]: c.seconds
Out[57]: 37800
In [58]: c.seconds / 3600
Out[58]: 10.5
In [59]: c.total_seconds() / 3600
Out[59]: 58.5
In [60]: from datetime import datetime
In [61]: a = datetime(2019, 11, 11) #要表示指定的日期时间,先创建一个datetime实例然后使用标准的数学运算操作它们
In [63]: a + timedelta(days=10)
Out[63]: datetime.datetime(2019, 11, 21, 0, 0)
In [64]: b = datetime(2019, 12, 21)
In [65]: d = b - a
In [66]: d.days
Out[66]: 40
In [67]: now = datetime.today()
In [68]: now
Out[68]: datetime.datetime(2019, 11, 11, 15, 7, 14, 561337)
In [69]: now + timedelta(minutes=10)
Out[69]: datetime.datetime(2019, 11, 11, 15, 17, 14, 561337)
In [9]: from datetime import datetime, timedelta
In [10]: a = datetime(2019, 11, 11)
In [11]: a + relativedelta(mnotallow=+1)
Out[11]: datetime.datetime(2019, 12, 11, 0, 0)
In [12]: a + relativedelta(mnotallow=+4)
Out[12]: datetime.datetime(2020, 3, 11, 0, 0)
In [17]: a
Out[17]: datetime.datetime(2019, 11, 11, 0, 0)
In [18]: b = datetime(2019, 12, 11)
In [19]: d = b - a
In [20]: d
Out[20]: datetime.timedelta(30)
In [21]: d = relativedelta(b, a)
In [22]: d
Out[22]: relativedelta(mnotallow=+1)
In [23]: d.months
Out[23]: 1
In [24]: d.days
Out[24]: 0
13、计算最后一个周五的日期
P103
14、计算当月份的日期范围
P105
15、字符串转换为日期datetime.strptime()
from datetime import datetime
datetime.strptime(s1, '%Y-%m-%d') #strptime()性能差,因为是用纯py实现,且必须处理所有的系统本地设置,如果代码中有大量的解析日期并知道确切格式,自己实现一套解析方案这样有更好的性能,如下例的parse_yml()函数实测比strptime()快7倍
datetime.strftime(d_obj, '%A %B %d, %Y')
In [25]: text = '2019-11-11'
In [27]: y = datetime.strptime(text, '%Y-%m-%d')
In [28]: z = datetime.now()
In [29]: diff = z - y
In [30]: diff
Out[30]: datetime.timedelta(0, 56820, 623104)
In [33]: z = datetime.now()
In [34]: nice_z = datetime.strftime(z, '%A %B %d, %Y')
In [35]: nice_z
Out[35]: 'Monday November 11, 2019'
In [36]: def parse_ymd(s):
...: year_s, mon_s, day_s = s.split('-')
...: return datetime(int(year_s), int(mon_s), int(day_s))
...:
16、结合时区的日期操作pytz
from datetime import datetime
from pytz import timezone
P107
In [1]: from datetime import datetime
In [2]: from pytz import timezone
In [4]: d = datetime(2019, 11, 11, 16, 30, 0)
In [5]: d
Out[5]: datetime.datetime(2019, 11, 11, 16, 30)
In [6]: central = timezone('Asia/Shanghai')
In [7]: loc_d = central.localize(d) #先将datetime创建的日期对象本地化
In [8]: loc_d
Out[8]: datetime.datetime(2019, 11, 11, 16, 30, tzinfo=<DstTzInfo 'Asia/Shanghai' CST+8:00:00 STD>)
In [9]: bang_d = loc_d.astimezone(timezone('US/Central')) #本地化后再转为其它时区的时间
In [10]: bang_d
Out[10]: datetime.datetime(2019, 11, 11, 2, 30, tzinfo=<DstTzInfo 'US/Central' CST-1 day, 18:00:00 STD>)
In [11]: import pytz
In [12]: pytz.country_timezones
Out[12]: <pytz._CountryTimezoneDict at 0x1478b72e978>
In [13]: pytz.country_timezones['IN']
Out[13]: ['Asia/Kolkata']
In [14]: pytz.country_timezones['CN'] #查找国家对应的时区
Out[14]: ['Asia/Shanghai', 'Asia/Urumqi']
In [15]: pytz.country_timezones['US']
四、迭代器与生成器
迭代是py最强大的功能之一;
迭代不仅仅是处理序列中元素的一种方法,还可以创建自己的迭代器对象|构造生成器函数|在itertools模块中使用有用的迭代模式等;
1、手动遍历迭代器
大多数情况下会用for语句来遍历一个可迭代对象,但偶尔也需要对迭代做更加精确的控制,这时就要了解底层迭代机制;
next(...)
next(iterator[, default])
Return the next item from the iterator. If default is given and the iterator
is exhausted, it is returned instead of raising StopIteration.
In [20]: items = [1,2,3]
In [21]: it = iter(items)
In [22]: next(it)
Out[22]: 1
In [23]: next(it)
Out[23]: 2
In [24]: next(it)
Out[24]: 3
In [25]: next(it)
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-25-bc1ab118995a> in <module>
----> 1 next(it)
StopIteration:
In [16]: def manual_iter():
...: with open(r'C:/consumer.csv') as f:
...: try:
...: while True:
...: line = next(f)
...: print(line, end='')
用来指示迭代的结尾
...: pass
...:
In [18]: def manual_iter():
...: with open(r'C:/consumer.csv') as f:
...: while True:
,通过返回一个指定值来标记结尾
...: if line is None:
...: break
...: print(line, end='')
...:
2、代理迭代__iter__()
自定义一个容器对象,里面包含列表|元组或其它可迭代对象,需要定义一个__iter__()方法, 才能在这个新容器对象上执行迭代操作;
py的迭代器协议要求__iter__()方法返回一个特殊的迭代器对象,该对象实现了__next__()方法,并通过StopIteration异常标识迭代的完成;
如果只是迭代遍历其它容器内容,无须关心底层是怎样实现的,要做的只是传递迭代请求即可;
iter(s) #s.__iter__()
len(s) #s.__len__()
In [26]: class Node:
...: def __init__(self, value):
...: self._value = value
...: self._children = []
...: def __repr__(self):
...: return 'Node({!r})'.format(self._value)
...: def add_child(self, node):
...: self._children.append(node)
该方法只是简单的将迭代请求传递给内部的_children属性
...: return iter(self._children)
...:
In [27]: root = Node(0)
In [28]: child1 = Node(1)
In [29]: child2 = Node(2)
In [30]: root.add_child(child1)
In [31]: root.add_child(child2)
In [32]: for ch in root:
...: print(ch)
...:
Node(1)
Node(2)
3、使用生成器创建新的迭代模式
函数中有yield即为生成器函数,跟普通函数不同的是生成器只能用于迭代操作;
生成器函数的主要特征是它只会回应在迭代中使用到的next操作,一旦生成器函数返回退出,迭代终止,在迭代中用for语句会自动处理这些细节;
In [33]: def frange(start, stop, increment):
...: x = start
...: while x < stop:
...: yield x
...: x += increment
...:
In [34]: for n in frange(0, 3, 0.5):
...: print(n)
...:
0
0.5
1.0
1.5
2.0
2.5
In [35]: list(frange(0, 1, 0.125))
Out[35]: [0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875]
In [36]: def countdown(n): #生成器函数底层工作机制
...: print('Starting to count from', n)
...: while n > 0:
...: yield n
...: n -= 1
...: print('Done!')
...:
In [37]: c = countdown(2) #该对象为<generator object countdown at ...>
In [38]: next(c) #run to first yield and emit a value
Starting to count from 2
Out[38]: 2
In [39]: next(c)
Out[39]: 1
In [40]: next(c) #run to next yield(iteration stops)
Done!
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-40-e846efec376d> in <module>
----> 1 next(c)
StopIteration:
4、实现迭代器协议
例,实现一个以深度优先方式遍历树形节点的生成器:
In [41]: class Node:
...: def __init__(self, value):
...: self._value = value
...: self._children = []
...: def __repr__(self):
...: return 'Node({!r})'.format(self._value)
...: def add_child(self, node):
...: self._children.append(node)
...: def __iter__(self):
...: return iter(self._children)
...: def depth_first(self): #首先返回自己本身,并迭代每一个子节点并通过调用子节点的depth_first()方法返回对应元素
...: yield self
...: for c in self:
...: yield from c.depth_first()
...:
In [42]: root = Node(0)
In [43]: child1 = Node(1)
In [44]: child2 = Node(2)
In [45]: root.add_child(child1)
In [46]: root.add_child(child2)
In [47]: child1.add_child(Node(3))
In [48]: child1.add_child(Node(4))
In [49]: child2.add_child(Node(5))
In [50]: for ch in root.depth_first():
...: print(ch)
...:
Node(0)
Node(1)
Node(3)
Node(4)
Node(2)
Node(5)
5、反向迭代reversed(lst)|__reversed__()
reversed(lst) #注意可迭代对象元素很多,预先转换为一个列表要消耗大量内存
反向迭代仅当对象的大小可预先确定或对象实现了__reversed__()这一特殊方法才能生效,如果两者都不符合,那必须先将对象转换为一个列表才行;
可在自定义类上实现__reversed__()魔术方法实现反向迭代;
In [51]: lst = [1,2,3,4,5]
In [52]: for x in reversed(lst):
...: print(x)
...:
5
4
3
2
1
In [54]: class Countdown:
...: def __init__(self, start):
...: self.start = start
...: def __iter__(self):
...: n = self.start
...: while n > 0:
...: yield n
...: n -= 1
定义一个反向迭代器可使代码更加高效,因为它不再需要将数据填充到一个列表中然后再去反向迭代这个列表
...: n = 1
...: while n <= self.start:
...: yield n
...: n += 1
...:
In [55]: for rr in Countdown(5):
...: print(rr)
...:
5
4
3
2
1
In [56]: for rr in reversed(Countdown(5)):
...: print(rr)
...:
1
2
3
4
5
6、带有外部状态的生成器函数
如果想让生成器暴露外部状态给用户,可定义一个类把生成器函数放到__iter__()中,使用时可将这个类当作是一个普通的生成器函数,另还可访问内部属性history|clear();
关于生成器,很容易掉进函数无所不能的陷阱,如果生成器函数需要跟程序其它部分交互,如暴露属性值|允许通过方法调用来控制,这样会导致代码复杂,这样情况就要考虑使用类的方式,在__iter__()中定义生成器,这不会改变任何的算法逻辑;
在使用时注意,如果没用for语句,那得先调用iter()函数;
In [74]: from collections import deque
In [75]: class linehistory:
...: def __init__(self, lines, histlen=3):
...: self.lines = lines
...: self.history = deque(maxlen=histlen)
...: def __iter__(self):
...: for lineno, line in enumerate(self.lines, 1):
...: self.history.append((lineno, line))
...: yield line
...: def clear(self):
...: self.history.clear()
...:
In [81]: with open(r'C:/test.txt') as f:
...: lines = linehistory(f)
...: for line in lines:
...: print(line)
...: print('!!!', lines.history)
...:
test
test1
test2
test3
!!! deque([(2, 'test1\n'), (3, 'test2\n'), (4, 'test3')], maxlen=3)
In [79]: with open(r'C:/test.txt', 'r') as f:
...: lines = linehistory(f)
...: for line in lines:
...: if 'test' in line:
...: for lineno, hline in lines.history:
...: print('{}:{}'.format(lineno, hline), end='')
...:
1:test
1:test
2:test1
1:test
2:test1
3:test2
2:test1
3:test2
4:test3
In [82]: f = open(r'c:/test.txt')
In [83]: lines = linehistory(f)
In [84]: next(lines)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-84-2e01bf9a9ff6> in <module>
----> 1 next(lines)
TypeError: 'linehistory' object is not an iterator
In [85]: it = iter(lines)
In [86]: next(it)
Out[86]: 'test\n'
In [87]: next(it)
Out[87]: 'test1\n'
In [88]: next(it)
Out[88]: 'test2\n'
In [89]: next(it)
Out[89]: 'test3'
In [91]: f.close()
7、迭代器切片itertools.islice()
itertools.islice()
class islice(builtins.object)
| islice(iterable, stop) --> islice object
| islice(iterable, start, stop[, step]) --> islice object
由迭代器生成的切片对象,用标准切片操作做不到;
迭代器和生成器不能使用标准的切片操作,因为它们的长度事先不知道,也没实现索引,函数itertools.islice()返回一个可生成指定元素的迭代器,它通过遍历并丢弃直到切片索引位置的所有元素,再开始一个个的返回元素,直到切片结束索引位置;
注意,islice()会消耗掉传入的迭代器中的数据,要考虑到迭代器是不可逆的这个事实,所以如果需要之后再次访问这个迭代器的话,就得事先将它里面的数据放入一个列表中;
In [92]: def count(n):
...: while True:
...: yield n
...: n += 1
...:
In [94]: import itertools
In [97]: c = count(0)
In [98]: for x in itertools.islice(c, 10, 15):
...: print(x)
...:
10
11
12
13
14
8、跳过可迭代对象的开始部分itertools.dropwhile()|itertools.islice()
对开始的某些元素不感兴趣要跳过;
dropwhile()|islice()是2个帮助函数,避免写两个循环的冗余代码;
itertools.dropwhile()
class dropwhile(builtins.object)
| dropwhile(predicate, iterable) --> dropwhile object
如果明确知道要跳过元素个数的话,可用itertools.islice();
In [101]: from itertools import dropwhile
In [103]: with open(r'c:/test.txt') as f:
...: for line in dropwhile(lambda line: line.startswith('#'), f):
...: print(line, end='')
...:
test1
test2
#test
test3
In [104]: from itertools import islice
In [105]: items = ['a', 'b', 'c', 'd', 1, 4, 10, 15]
In [106]: for x in islice(items, 3, None): #None即到最后,同普通切片[3:]
...: print(x)
...:
d
1
4
10
15
In [107]: with open(r'c:/test.txt') as f: #跳过一个可迭代对象的开始部分跟通常的过滤是不同的,这样写,不但跳过了开始的注释行,也路过文件中其它的地方的注释
...: lines = (line for line in f if not line.startswith('#'))
...: for line in lines:
...: print(line, end='')
...:
test1
test2
test3
9、排列组合的迭代itertools.permutations()|itertools.combinations()|itertools.combinations_with_replacement()
P123
10、序列上索引值迭代enumerate()
enumerate() #在跟踪某些值在列表中出现的位置是很有用的;
class enumerate(object)
| enumerate(iterable[, start]) -> iterator for index, value of iterable
enumerate()返回的是一个enumerate对象实例,是一迭代器,返回连续的包含一个计数和一个值的元组,元组中的值通过在传入序列上调用next()返回;
注意,在迭代data=[(1,2),(3,4),(5,6)]这样的序列要for n,(x,y) in enumerate(data);
In [108]: lst = [1,2,3]
In [110]: for idx, val in enumerate(lst, 1):
...: print(idx, val)
...:
1 1
2 2
3 3
In [111]: def parse_data(filename):
...: with open(filename, 'rt') as f:
在遍历文件时在错误消息中使用行号定位时非常有用
...: fields = line.split()
...: try:
...: count = int(fields[1])
...: except ValueError as e:
...: print('Line {}: Parse error: {}'.format(lineno, e))
...:
In [115]: with open(r'c:/test.txt') as f: #将一个文件中的单词映射到它出现的行号上
...: lines = f.readlines()
...: for idx, line in enumerate(lines):
...: words = [w.strip() for w in line.split()]
...: for word in words:
...: word_summary[word].append(idx)
...:
In [116]: word_summary
Out[116]:
defaultdict(list,
{'#test': [0, 1, 2, 6],
'test': [0],
'test1': [4],
'test2': [5],
'test3': [7]})
In [118]: data = [(1,2),(3,4),(5,6)]
In [119]: for n,(x,y) in enumerate(data): #Correct
...: print(n ,(x,y))
...:
0 (1, 2)
1 (3, 4)
2 (5, 6)
In [120]: for n,x,y in enumerate(data): #Error
...: print(n,x,y)
...:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-120-fb4540eda220> in <module>
----> 1 for n,x,y in enumerate(data):
2 print(n,x,y)
3
ValueError: not enough values to unpack (expected 3, got 2)
11、同时迭代多个序列zip()|itertools.zip_longest()
迭代多个序列,每次从一个序列中取一个元素;
zip(a,b) #生成一个可返回元组(x,y)的迭代器,其中x来自a,y来自b,一旦其中某个序列到结尾,迭代宣告结束,因此迭代长度跟参数中最短序列长度一致;zip(a,b,c)可接受多于2个序列的参数
from itertools import zip_longest
zip_longest(a,b) #按a|b最长元素迭代,缺的补None
In [121]: xpts = [1,2,3,4,5]
In [122]: ypts = [11,22,33,44,55]
In [124]: for x,y in zip(xpts,ypts):
...: print(x,y)
...:
1 11
2 22
3 33
4 44
5 55
In [125]: for i in zip(xpts,ypts):
...: print(i)
...:
(1, 11)
(2, 22)
(3, 33)
(4, 44)
(5, 55)
In [126]: a = [1,2,3]
In [127]: b = ['x','y','z','w']
In [128]: from itertools import zip_longest
In [129]: for i in zip_longest(a,b):
...: print(i)
...:
(1, 'x')
(2, 'y')
(3, 'z')
(None, 'w')
In [130]: headers = ['name','shares','price']
In [131]: values = ['ACME',100,490.1]
In [132]: s = dict(zip(headers,values))
In [133]: s
Out[133]: {'name': 'ACME', 'shares': 100, 'price': 490.1}
In [134]: a = [1,2,3]
In [135]: b = [11,22,33]
In [136]: c = [111,222,333]
In [137]: for i in zip(a,b,c):
...: print(i)
...:
(1, 11, 111)
(2, 22, 222)
(3, 33, 333)
12、不同集合上元素的迭代itertools.chain()
itertools.chain(a,b) #接受1个或多个可迭代对象作为输入参数,然后创建一个迭代器,依次连续地返回每个可迭代对象中的元素;对不同集合中所有元素执行某些操作,这种方式比用2个单独循环更加优雅,也比先将序列合并再迭代效率高
In [138]: from itertools import chain
In [139]: a = [1,2,3]
In [140]: b = ['x','y','z']
In [141]: for x in chain(a,b):
...: print(x)
...:
1
2
3
x
y
z
***13、创建数据处理管道
以类似unix管道的方式迭代处理数据,如有大量的数据要处理,但不能将它们一次性放入内存中;
生成器是一个实现管道机制的好办法,以管道方式处理数据可以用来解决各类其它问题,如解析|读取实时数据|定时轮询;
为理解下例,重点要明白yield语句作为数据的生产者而for语句作为数据的消费者,当这些生成器被连在一起后,每个yield会将一个单独的数据元素传递迭代处理管道的下一阶段,在此例最后sum()是最终的程序驱动者,每次从生成器管道中提取出一个元素;
这种方式的好处:
1、每个生成器函数很小且都是独立的,容易编写和维护,多数时这些函数比较通用的话可在其它场景重复使用;
2、内存效率高,下例代码即使在一个超大型文件目录中也能工作得很好,由于使用了迭代方式处理,代码运行过程中只需要很小的内存;
3、也适用于立即处理所有数据,使用生成器管道可将这类问题从逻辑上变为工作流的处理方式;
例,查找包含指定单词的所有日志行:
import os,fnmatch,gzip,bz2,re
def gen_find(filepat, top):
for path, dirlist, filelist in os.walk(top):
for name in fnmatch.filter(filelist, filepat):
yield os.path.join(path, name)
def gen_opener(filenames):
for filename in filenames:
if filename.endswith('.gz'):
f = gzip.open(filename, 'rt')
elif filename.endswith('.bz2'):
f = bz2.open(filename, 'rt')
else:
f = open(filename, 'rt')
yield f
f.close()
def gen_concatenate(iterators): #此函数目的将输入序列拼接成一个很长的行序列,此处不能用lines = itertools.chain(*files)否则会将gen_opener()生成器全部消费掉,而gen_opener()生成器每次打开一个文件,等到下一个迭代时文件就关闭了,因此不能在此处用chain()
for it in iterators:
yield from it #它将yield操作代理到父生成器上,即简单的返回it所产生的所有值,等价于for i in it: yield i
def gen_grep(pattern, lines):
pat = re.compile(pattern)
for line in lines:
if pat.search(line):
yield line
lognames = gen_find('access-log*', '/var/log/www/')
files = gen_opener(lognames)
lines = gen_concatenate(files)
pylines = gen_grep('(?i)python', lines)
for line in pylines:
print(line)
bytecolumn = (line.rsplit(None,1)[1] for line in pylines)
bytes = (int(x) for x in bytecolumn if x!= '-')
print('Total', sum(bytes))
14、展开嵌套的序列collections.Iterable
yield
yield from #在涉及到基于协程和生成器的并发编程中扮演着更加重要的角色
将一个多层嵌套的序列展开成一个单层列表;
In [147]: from collections import Iterable
In [148]: def flatten(items, ignore_types=(str, bytes)): #有对字符串|字节的额外检查,防止将它们再展开成单个字符
...: for x in items:
...: if isinstance(x, Iterable) and not isinstance(x, ignore_types):
...: yield from flatten(x)
...: else:
...: yield x
...:
In [149]: items = [1,2,[3,4,[5,6],7],8]
In [150]: for x in flatten(items):
...: print(x)
...:
1
2
3
4
5
6
7
8
In [151]: items = ['Dave', 'Paula', ['Thomas', 'Lewis']]
In [152]: for x in flatten(items):
...: print(x)
...:
Dave
Paula
Thomas
Lewis
15、顺序迭代合并后的排序迭代对象heapq.merge()
heapq.merge(a,b) #要求所有输入序列先排序,它不会预先读取所有数据到堆栈中或预先排序,也不会对输入做任何排序检测,它仅仅是检查所有序列的开始部分并返回最小的那个这个过程会一直持续直到所有输入序列中的元素都遍历完;heapq.merge()迭代特性意味着它不会立马读取所有序列,即可在非常长的序列中使用它而不会有太大的开销
In [155]: a = [1,4,7,10]
In [156]: b = [2,5,6,11]
In [159]: for c in heapq.merge(a,b):
...: print(c)
...:
1
2
4
5
6
7
10
11
with open('file1', 'rt') as f1, open('file2', 'rt') as f2, open('merge-file', 'wt') as outf:
for line in heapq.merge(file1, file2):
outf.write(line)
16、迭代器替代while无限循环
iter(...) #一个鲜为人知的特性是它接受一个可选的callable对象和一个标记(结尾)值作为输入参数,以这种方式使用时会创建一个迭代器,这个迭代器会不断调用callable对象直到返回值和标记值相等为止,这种特殊的方法对于一些特定的会被重复调用的函数很有效果,如涉及到i/o调用的函数
iter(iterable) -> iterator
iter(callable, sentinel) -> iterator

七、函数
1、可接受任意数量参数的函数
使用一个*参数 #接受任意数量的位置参数,tuple
使用一个**开头的参数 #接受任意数量的关键字参数,dict,**参数只能出现在最后
In [161]: def avg(first, *rest): #rest是由其它位置参数组成的tuple,代码中把其当作序列
...: return (first + sum(rest)) / (1+len(rest))
...:
In [162]: avg(1,2)
Out[162]: 1.5
In [163]: avg(1,2,3,4)
Out[163]: 2.5
In [167]: def make_element(name, value, **attrs): #attrs是一个包含所有被传入进来的关键字参数的字典
...: keyvals = [' %s="%s"' % item for item in attrs.items()]
...: attr_str = ''.join(keyvals)
...: element = '<{name}{attrs}>{value}</{name}>'.format(name=name, attrs=attr_
...: str, value=html.escape(value))
...: return element
...:
In [168]: make_element('item', 'Albatross', size='large', quantity=6)
Out[168]: '<item size="large" quantity="6">Albatross</item>'
In [169]: make_element('p', '<span>')
Out[169]: '<p><span></p>'
In [170]: def anyargs(*args, **kwargs):
...: print(args, kwargs)
...:
In [171]: def a(x, *args, y): #*参数后仍可定义其它参数,称为强制关键字参数
...: pass
...:
In [172]: def b(x, *args, y, **kwargs): #**参数只能是最后一个参数
...: pass
...:
2、只接受关键字参数的函数
将强制关键字参数放到某个*或单个*后面,就能达到效果;
希望函数的某些参数强制使用关键字参数传递;
很多情况下,使用强制关键字参数会比使用位置参数表单更加清晰,程序也更有可读性,如msg=recv(1024,False)不明白False是干什么的,如果是msg=recv(1024,block=True)就清晰了;
另,使用强制关键字参数比使用**kwargs参数更好,因为在使用help时输出更易理解;
In [173]: def recv(maxsize, *, block):
...: pass
...:
In [174]: recv(1024, True) #错误
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-174-7e28410a28bd> in <module>
----> 1 recv(1024, True)
TypeError: recv() takes 1 positional argument but 2 were given
In [175]: recv(1024, block=True) #正确
In [176]: def mininum(*values, clip=None): #可在接受任意多个位置参数的函数中指定关键字参数
...: m = min(values)
...: if clip is not None:
...: m = clip if clip > m else m
...: return m
...:
In [177]: mininum(1,5,2,-5,10)
Out[177]: -5
In [178]: mininum(1,5,2,-5,10, clip=0)
Out[178]: 0
3、给函数参数增加元信息
使用函数参数注解,主要用途是文档,因为py没有类型声明,仅通过阅读源码很难知道该传递什么参数给这个函数;对阅读代码的人来讲有帮助,第三方工具和框架可能会对这些注解添加语义,同时也会出现在文档中;
py解释器不会对这些注解添加任何语义,它们不会被类型检查,运行时跟没有加注解之前的效果也没任何差别;
函数注解只存储在函数的__annotations__属性中;
In [179]: def add(x:int, y:int) -> int:
...: return x + y
...:
In [180]: help(add)
Help on function add in module __main__:
add(x:int, y:int) -> int
In [181]: add.__annotations__
Out[181]: {'x': int, 'y': int, 'return': int}
4、返回多个值的函数
函数直接return一个元组就行;
In [182]: def myfun():
实际是先创建了一个元组才返回的,是用逗号来生成一个元组的,如a=1,2结果为(1,2)
...:
In [183]: a,b,c = myfun()
In [184]: a
Out[184]: 1
In [185]: b
Out[185]: 2
In [186]: c
Out[186]: 3
In [187]: a = (1,2)
In [188]: a
Out[188]: (1, 2)
In [189]: b = 1,2
In [190]: b
Out[190]: (1, 2)
5、定义有默认参数的函数
直接在函数定义中给参数指定一个默认值,并放到参数列表最后就行;
如果默认参数是一个可修改的容器,如一个list|set|dict,可使用None作为默认值;
默认参数的值应该是不可变对象,如None|True|False|数字|字符串,千万不能这样写def span(a,b=[]);
在测试None值时使用is是很重要的,也是这种方案的关键点,不能用if not b,尽管None值等效于False,但还有长度为0的字符串|列表|元组|字典等都等效False;
如果并不想提供一个默认值,而是想仅测试下某个默认参数是不是有传递进来,使用_no_value=object(),仔细观察可知,传递一个None值和不传值这两种情况是有差别的;
_no_value为一个独一无二的私有对象实例,可通过检查被传递参数值跟这个实例是否一样来判断,object是py中所有类的基类,创建object类的实例,该实例没有实际用处,因为它并没有任何有用的属性和方法,唯一能做的就是测试同一性;
默认参数的值仅在函数定义时赋值1次,当之后再改变x值时对默认参数值没有影响,因为在函数定义时就已经确定了;
In [191]: def span(a, b=42):
...: print(a, b)
...:
In [192]: span(1)
1 42
In [193]: span(1,2)
1 2
In [194]: def span(a, b=None):
...: if b is None: #在测试None值时使用is是很重要的,也是这种方案的关键点,不能用if not b,尽管None值等效于False,但还有长度为0的字符串|列表|元组|字典等都等效False
...: b = []
...:
In [195]: _no_value = object()
In [197]: def span(a, b=_no_value):
...: if b is _no_value:
...: print('No b value supplied')
...:
In [198]: span(1)
No b value supplied
In [199]: span(1,2)
In [200]: span(1, None)
In [201]: x = 21
In [202]: def span(a, b=x): #默认参数的值仅在函数定义时赋值1次,当之后再改变x值时对默认参数值没有影响,因为在函数定义时就已经确定了
...: print(a, b)
...:
In [203]: span(1)
1 21
In [204]: x = 22
In [205]: span(1)
1 21
6、定义匿名函数或内联函数
用lambda表达式;
典型使用场景是排序或数据reduce等,当要编写大量计算表达式值的矮小函数或需要用户提供回调函数程序时用到lambda表达式;
In [206]: add = lambda x, y: x + y
In [207]: add(2,3)
Out[207]: 5
In [208]: add('hello', 'world')
Out[208]: 'helloworld'
In [209]: names = ['David Beazley','Brian Jones','Raymond Hettingser']
In [210]: sorted(names, key=lambda name: name.split()[-1].lower())
Out[210]: ['David Beazley', 'Raymond Hettingser', 'Brian Jones']
7、匿名函数捕获变量值
In [211]: x = 10
In [212]: a = lambda y: x+y #x是自由变量,lambda表达式在运行时才绑定值,而函数是在定义时有默认值参数时才绑定值的
In [213]: x = 20
In [214]: b = lambda y: x+y
In [215]: a(10)
Out[215]: 30
In [216]: b(10)
Out[216]: 30
In [217]: x = 10
In [218]: a = lambda y, x=x: x+y #如果让匿名函数在定义时就捕获到值,可将参数值定义成默认参数
In [219]: x = 20
In [220]: b = lambda y, x=x: x+y
In [221]: a(10)
Out[221]: 20
In [222]: b(10)
Out[222]: 30
In [223]: funcs = [lambda x: x+n for n in range(5)] #错误
In [224]: for f in funcs:
...: print(f(0))
...:
4
4
4
4
4
In [225]: funcs = [lambda x, n=n: x+n for n in range(5)] #正确,在列表推导中创建一lambda表达式列表,并希望函数在定义时就记住每次的迭代值
In [226]:
In [226]: for f in funcs:
...: print(f(0))
...:
0
1
2
3
4
8、减少可调用对象的参数个数functools.partial()
functools.partial() #partial()固定某些参数并返回一个新的callable对象,这个新的callable接受未赋值的参数,然后跟之前已经赋值过的参数合并起来,最后将所有参数传递给原始函数
P219
In [227]: from functools import partial
In [228]: def span(a,b,c,d):
...: print(a,b,c,d)
...:
In [229]: s1 = partial(span, 1)
In [230]: s1(2,3,4)
1 2 3 4
In [231]: s1(4,5,6)
1 4 5 6
In [232]: s2 = partial(span, d=42)
In [233]: s2(1,2,3)
1 2 3 42
In [234]: s3 = partial(span, 1, 2, d=42)
In [235]: s3(3)
1 2 3 42
In [236]: s3(4)
1 2 4 42
9、将单方法的类转换为函数(闭包)
大多数情况,拥有一个单方法的类的原因是需要存储某些额外的状态来给方法使用;
使用一个内部函数或闭包的方案通常会更简洁和优雅,简单来讲,一个闭包就是一个函数,只不过在函数内部带上了一个额外的变量环境,闭包关键特点就是它会记住自己被定义时的环境,如下例中opener()记住了template参数的值,并在接下来的调用中使用它,任何时候只要碰到需要给某个函数增加额外的状态信息时,都可考虑使用闭包;
In [237]: from urllib.request import urlopen
In [238]: class UrlTemplate:
...: def __init__(self, template):
...: self.template = template
...: def open(self, **kwargs):
...: return urlopen(self.template.format_map(kwargs))
...:
In [239]: def urltemplate(template):
...: def opener(**kwargs):
...: return urlopen(template.format_map(kwargs))
...: return opener
...:
10、带额外状态信息的回调函数
通常在很多函数库和框架中使用回调函数,特别是跟异步处理有关;
nonlocal声明可让我们编写函数来修改内部的变量的值;
函数属性允许我们用一种很简单的方式将访问方法绑定到闭包函数上,跟实例方法很像(尽管并没有定义任何类);
In [240]: def apply_async(func, args, *, callback): #想让回调函数访问其它变量或特定环境的变量值时就有麻烦
...: result = func(*args)
...: callback(result)
...:
In [241]: def print_result(result):
...: print('Got:', result)
...:
In [242]: def add(x, y):
...: return x + y
...:
In [243]: apply_async(add, (2,3), callback=print_result)
Got: 5
In [244]: class ResultHandler: #方1
...: def __init__(self):
...: self.sequence = 0
...: def handler(self, result):
...: self.sequence += 1
...: print('[{}] Got: {}'.format(self.sequence, result))
...:
In [245]: r = ResultHandler()
In [246]: apply_async(add, (1,2), callback=r.handler)
[1] Got: 3
In [247]: apply_async(add, (1,2), callback=r.handler)
[2] Got: 3
In [250]: def make_handler(): #方2,闭包更加轻量级和自然,因为可以很简单地通过函数来构造,还能自动捕获所有被使用到的变量
...: sequence = 0
...: def handler(result):
...: nonlocal sequence 声明可让我们编写函数来修改内部的变量的值
...: sequence += 1
...: print('[{}] Got: {}'.format(sequence, result))
...: return handler
...:
In [252]: handler = make_handler()
In [253]: apply_async(add, (4,5), callback=handler)
[1] Got: 9
In [260]: def make_handler(): #方3
...: sequence = 0
...: while True:
...: result = yield
...: sequence += 1
...: print('[{}] Got: {}'.format(sequence, result))
...:
In [261]: handler = make_handler()
In [262]: next(handler) #advance to the yield
In [263]: apply_async(add, (2,3), callback=handler.send) #要用send()作为回调函数
[1] Got: 5
11、内联回调函数
使用生成器和协程可以使得回调函数内联在某个函数中;
P226
12、访问闭包中定义的变量
通常,闭包的内部变量对外界来讲是完全隐藏的,但可通过编写访问函数并将其作为函数属性绑定到闭包上来实现;
函数属性允许我们用一种很简单的方式将访问方法绑定到闭包函数上,跟实例方法很像(尽管并没有定义任何类);
In [264]: def sample():
...: n = 0
...: def func():
...: print('n=', n)
...: def get_n():
...: return n
...: def set_n(value):
...: nonlocal n
...: n = value
...: func.get_n = get_n函数属性允许我们用一种很简单的方式将访问方法绑定到闭包函数上,跟实例方法很像(尽管并没有定义任何类)
...: func.set_n = set_n
...: return func
...:
In [265]: f = sample()
In [266]: f()
n= 0
In [267]: f.set_n(10)
In [268]: f()
n= 10
In [269]: f.get_n()
Out[269]: 10
例,用闭包模拟类的实例:
P228
十三、脚本编程与系统管理
1、通过重定向|管道|文件接受输入fileinput.input()
import fileinput
fileinput.input() #创建并返回一个FileInput类的实例,该实例除拥有一些有用的帮助方法外,还可被当作一个上下文管理器使用;脚本可接受用户认为最简单的输入方式,如通过管道传递给脚本,重定向文件到该脚本,在命令行中传入一个文件名列表给该脚本
例:
test.py
#!/usr/bin/env python
#
import fileinput
with fileinput.input() as f_input:
for line in f_input:
print(line, end='')
#chmod +x test.py
#ls | ./test.py
#./test.py /etc/passwd
#./test.py < /etc/passwd
例:
import fileinput
with fileinput.input() as f:
for line in f:
print(f.filename(), f.lineno(), line, end='')
]# ./test.py /etc/passwd
/etc/passwd 1 root:x:0:0:root:/root:/bin/bash
/etc/passwd 2 bin:x:1:1:bin:/bin:/sbin/nologin
/etc/passwd 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
……
2、终止程序并给出错误信息raise
raise SystemExit('It failed!\n') #抛出一个SystemExit异常,使用错误消息作为参数,消息将在sys.stderr中打印,然后程序以状态码1退出;同sys.stderr.write('It failed!\n')
3、解析命令行选项argparse
argparse模块是标准库中最大的模块之一,拥有大量的配置选项;
先创建一个ArgumentParser实例;
使用add_argument()声明要支持的选项:
dest参数指定解析结果被指派给属性的名字;
metavar参数被用来生成帮助信息;
required表示该参数至少要有1个;
action参数指定跟属性对应的处理逻辑(通常为store),被用来存储某个值或将多个参数收集到一个列表中;actinotallow='store_true'根据参数是否存在设置一个Boolean标志;actinotallow='store',接受一个单独值并将其存储为一个字符串;actinotallow='append'允许某个参数重复出现多次,并将它们追加到一个列表中;actinotallow='store' choices={'slow','fast'} default='slow'接受一个值,但会将其和可能的选择值作比较,以检测其合法性;
一旦参数选项被指定,就可执行parser.parse_args(),它会处理sys.argv的值并返回一个结果实例,每个参数值被设置成该实例中add_argument()的dest参数指定的属性值;
另,可手动用sys.argv或getopt模块,但若用argparse模块将会减少很多冗余代码;
optparse和argparse,argparse更先进;
search.py
#!/usr/bin/env python
#
import argparse
parser = argparse.ArgumentParser(descriptinotallow='Search some files')
parser.add_argument(dest='filenames', metavar='filename', nargs='*')
parser.add_argument('-p', '--pat', metavar='pattern', required=True, dest='patterns', actinotallow='append', help='text pattern to search for')
parser.add_argument('-v', dest='verbose', actinotallow='store_true', help='verbose mode')
parser.add_argument('-o', dest='outfile', actinotallow='store', help='output file')
parser.add_argument('--speed', dest='speed', actinotallow='store', choices={'slow', 'fast'}, default='slow', help='search spped')
args = parser.parse_args()
print(args.filenames)
print(args.patterns)
print(args.verbose)
print(args.outfile)
print(args.speed)
]# ./search.py -p '.*?'
[]
['.*?']
False
None
slow
]# ./search.py -v -p span --pat=eggs foo.txt bar.txt -o results --speed=fast
['foo.txt', 'bar.txt']
['span', 'eggs']
True
results
fast
]# ./search.py -h
usage: search.py [-h] -p pattern [-v] [-o OUTFILE] [--speed {slow,fast}]
[filename [filename ...]]
Search some files
positional arguments:
filename
optional arguments:
-h, --help show this help message and exit
-p pattern, --pat pattern
text pattern to search for
-v verbose mode
-o OUTFILE output file
--speed {slow,fast} search spped
4、运行时弹出密码输入提示getpass
getpass #可很轻松的弹出密码输入提示,且不会在用户终端回显密码,getpass.getuser()不会弹出用户名的输入提示,它会根据用户的shell环境或依据本地系统的密码库(支持pwd模块的平台)来使用当前用户的登录名,若想显示用户名输入提示用user = input('Enter you username: ');另有些系统不支持getpass()方法隐藏输入密码,py会警告并以明文形式显示
input_pass.py
#!/usr/bin/env python
#
import getpass
user = getpass.getuser()
passwd = getpass.getpass()
def svc_login(user, passwd):
if passwd == 'test123':
print('Yay!')
else:
print('Boo!')
svc_login('root', 'test123')
]# ./input_pass.py
Password:
Yay!
5、获取终端的大小os.get_terminal_size()
还有其它方法,从读取环境变量,并执行底层的ioctl()函数;
In [272]: import os
In [273]: os.get_terminal_size()
Out[273]: os.terminal_size(columns=88, lines=28)
In [274]: sz = os.get_terminal_size()
In [275]: sz.columns
Out[275]: 88
In [276]: sz.lines
Out[276]: 28
6、执行外部命令并获取它的输出subprocess.check_output()
subprocess.check_output(['cmd', 'arg1', 'arg2'], stderr=subprocess.STDOUT, timeout=5) #执行指定命令并将执行结果以一个字节字符串形式返回,默认仅返回输入到标准输出的值,如果要同时收集标准输出和错误输出使用stderr参数,如果用超时机制来执行命令用timeout参数;如果被执行的命令以非零码返回会抛异常,要捕获异常并获取返回码
通常,命令的执行不需要使用到底层shell环境,一个字符串列表会被传递给一个低级系统命令,如os.execve(),如果想让命令被一个shell执行,设置shell=True,适用情况:想要py执行一个复杂的shell命令时,如管道流|I/O重定向等特性;
out_bytes = subprocess.check_output('grep python| wc > out', shell=True)
check_output()是执行外部命令并获取其返回值的最简单方式,但如果要对子进程做更复杂的交互,如发送输入,得用subprocess.Popen类;
subprocess模块对于依赖TTY的外部命令不合适用,如还能用它来自动化一个用户输入密码的任务,这要用到第三方模块如著名的expect家族的工具pexpect;
>>> import subprocess
>>> out_bytes = subprocess.check_output(['netstat', '-tnlp'])
>>> print(out_bytes.decode('utf-8'))
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:10060 0.0.0.0:* LISTEN 3011/zabbix_agentd
……
>>> try:
... out_bytes = subprocess.check_output(['netstat','-tnlp']) #如果被执行的命令以非零码返回会抛异常,要捕获异常并获取返回码
... except subprocess.CalledProcessError as e:
... out_bytes = e.output
... code = e.returncode
... except subprocess.TimeoutExpired as e:
... pass
>>> print(out_bytes.decode())

7、复制或移动文件或目录shutil
shutil.copy(src, dst) #这些函数的参数都是字符串形式的文件或目录名,底层语义模拟了类似unix命令;默认符号链接处理的是其指向的东西;如果只想复制符号链接文件本身,用关键字参数follow_symlinks=True;如果想保留被复制目录中的符号链接,symlinks=True
shutil.copy2(src, dst) #对于文件元数据信息,copy2()只能尽最大能力来保留,访问时间|创建时间|权限会保留,但对于所有者|ACLs|资源fork和其它更深层次的文件元信息就说不准了,这得依赖底层OS类型和用户所拥有的访问权限;通常不使用copytree()执行系统备份,当处理文件名时最好用os.path中的函数来确保最大的可移植性
shutil.copytree(src, dst) #copytree()复制文件夹的一个棘手问题是对于错误的处理,如在复制过程中,函数可能会碰到损坏的符号链接,因权限无法访问等,为解决这些问题,所有碰到的问题会被收集到一个列表中并打包为一个单独的异常到了最后再抛出,用ignore_dangling_symlinks=True时copytree()会忽略掉无效符号链接
shutil.move(src, dst)
def ignore_pyc_files(dirname, filenames):
return [name in filenames if name.endswith('.pyc')]
shutil.copytree(src, dst, ignore=ignore_pyc_files) #可在复制过程中选择性的忽略某些文件或目录,提供一个忽略函数,接受一个目录名和文件名列表作为输入,返回一个忽略的名称列表
In [277]: filename = '/Users/guido/programs/spam.py'
In [278]: import os
In [279]: os.path.basename(filename)
Out[279]: 'spam.py'
In [280]: os.path.dirname(filename)
Out[280]: '/Users/guido/programs'
In [281]: os.path.split(filename)
Out[281]: ('/Users/guido/programs', 'spam.py')
In [282]: os.path.join('/new/dir', os.path.basename(filename))
Out[282]: '/new/dir\\spam.py'
In [284]: os.path.expanduser('~/guido/programs/spam.py')
Out[284]: 'C:\\Users\\Administrator.SC-201908130831/guido/programs/spam.py'
try:
shutil.copytree(src, dst)
except shutil.Error as e:
for src, dst, msg in e.args[0]:
print(dst, src, msg)
8、创建和解压归档文件shutil.make_archive()|shutil.unpack_archive()
make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0, dry_run=0, owner=None, group=None, logger=None)
Create an archive file (eg. zip or tar).
unpack_archive(filename, extract_dir=None, format=None)
Unpack an archive.
In [291]: shutil.get_archive_formats()
Out[291]:
[('bztar', "bzip2'ed tar-file"),
('gztar', "gzip'ed tar-file"),
('tar', 'uncompressed tar file'),
('xztar', "xz'ed tar-file"),
('zip', 'ZIP file')]
In [294]: shutil.make_archive('http', 'zip', r'c:/EFI') #将目录中的文件打包,不包括目录本身
Out[294]: 'D:\\Program Files\\Python\\Python36\\Scripts\\http.zip'
In [297]: shutil.unpack_archive('http.zip', extract_dir=r'c:/test')
9、通过文件名查找文件os.walk()
os.walk() #遍历目录树,每次进入一个目录返回一个三元组,包含相对于查找目录的相对路径,一个该目录下的目录名列表,及那个目录下面的文件名列表
os.path.abspath() #接受一个路径(可能是相对路径)返回绝对路径
os.path.normpath() #返回正常路径,可解决双斜杠//和对目录的多重引用问题
findfile.py
#!/usr/bin/env python
#
import os, sys
def findfile(start, name):
for relpath, dirs, files in os.walk(start):
if name in files:
full_path = os.path.join(start, relpath, name)
print(os.path.normpath(os.path.abspath(full_path)))
if __name__ == '__main__':
findfile(sys.argv[1], sys.argv[2])
]# ./findfile.py /tmp input_pass.py
/tmp/input_pass.py

10、读取.ini配置文件configparser.ConfigParser
from configparser import ConfigParser #有一被忽视的特性是能一次读取多个配置文件,然后合并成一个配置
py代码源文件和可实现同样功能的配置文件有很大不同,配置文件的语法更自由,如:
prefix=/usr/lcoal等价于prefix: /usr/local;
配置文件的名字不区分大小写,cfg.get('installation', 'PREFIX')同cfg.get('installation', 'prefix');
解析值时,getboolean()方法查找任何可行的值,log_errors = true同log_errors = TRUE同log_errors = Yes同log_errors = 1;
配置文件和py代码最大的不同在于,它并不是从上而下顺序执行,文件是按一个整体被读取的,如果碰到了变量替换,它实际上已经被替换完成了,如下例的prefix=/usr/local在之前和之后定义都可以,如果有多处定义同一变量,按后发制人策略,以最后一个为准;
config.ini #配置数据会被分组,每个分组在其中指定对应的各个变量值
[installation]
library=%(prefix)s/lib
include=%(prefix)s/includ
bin=%(prefix)s/bin
prefix=/usr/local
# Setting related to debug configuration
[debug]
log_errors=true
show_warnings=False
[server]
port: 8080
nworkers: 32
pid-file=/tmp/spam.pid
root=/www/root
In [300]: from configparser import ConfigParser
In [301]: cfg = ConfigParser()
In [302]: cfg.read(r'c:/config.ini') #另cfg.read(os.path.expanduser('~/.config.ini'))
Out[302]: ['c:/config.ini']
In [303]: cfg.sections()
Out[303]: ['installation', 'debug', 'server']
In [304]: cfg.get('installation', 'library')
Out[304]: '/usr/local/lib'
In [305]: cfg.getboolean('debug', 'log_errors')
Out[305]: True
In [306]: cfg.getint('server', 'port')
Out[306]: 8080
In [307]: cfg.getint('server', 'nworkers')
Out[307]: 32
In [308]: cfg.set('server', 'port', '9000')
In [309]: cfg.set('debug', 'log_errors', 'False')
11、给简单脚本增加日志功能logging
import logging
logging.basicConfig(filename='app.log', level=logging.ERROR, format='%(levelname)s:%(asctime)s:%(message)s') #basicConfig()的level参数是个过滤器,低于此级别的日志消息会被忽略掉;如果只想让日志消息写到标准错误中,而不是日志文件,调用basicConfig()不传filename参数即可;basicConfig()在程序中只能被执行1次,之后要改变日志配置要先获取root logger再修改,logging.getLogger().level=logging.DEBUG
logging.config.fileConfig('logconfig.ini') #使用配置文件
logging.DEBUG #debug|info|warning|error|critical
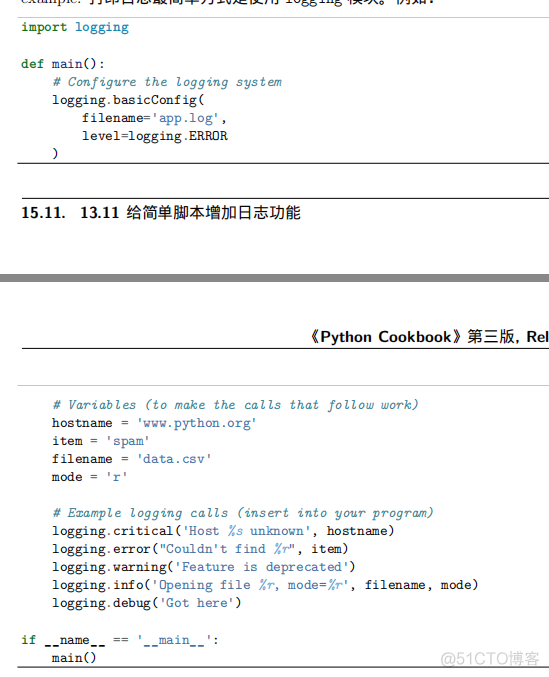
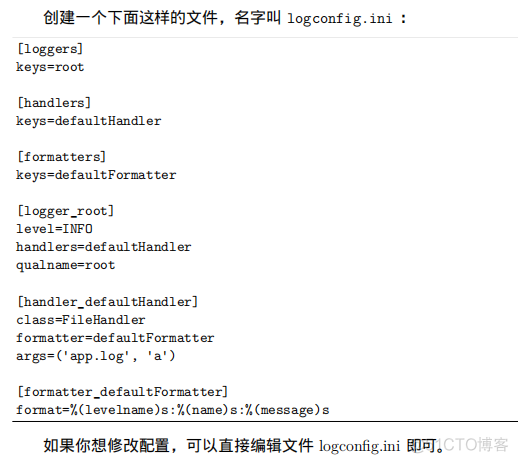
12、给函数库增加日志功能logging
给某个函数库增加日志功能,但又不影响到那些不使用日志功能的程序;
somelib.py
log = logging.getLogger(__name__) #创建一个和调用模块同名的logger模块,由于模块唯一logger也唯一
log.addHandler(logging.NullHandler()) #将空处理器绑定到创建的log对象上,空处理器默认会忽略调用所有的日志消息,如果使用该函数库时没有配置日志那么将不会有消息或警告出现
somelib.py
def func():
log.critical('A Critical Error!')
log.debug('A debug message')
import somelib
somelib.func() #默认,不会打印日志
import logging
logging.basicConfig()
somelib.func() #如果配置过日志系统,日志消息打印会生效
import logging #根日志配置为仅输出ERROR级别以上的消息,全局级别
logging.basicConfig(level=logging.ERROR)
import somelib
somelib.func()
import logging #somelib的日志级别配置成可输出DEBUG级别,这个优先级比全局配置高,这样更改单独模块的日志配置对于调试来讲很方便,因为无需去更改任何的全局日志配置,只需修改更多输出的模块的日志等级
logging.getLogger('somelib').level=logging.DEBUG
somelib.func()
13、实现一个计时器time.perf_counter()
记录程序执行多个任务所花费的时间;
time.perf_counter() #time.time()或time.clock()计算的时间精度因OS的不同会有所不同,而用time.perf_counter()可确保使用最精确的计时器,记录的是钟表时间
time.process_time() #计算进程花费的cpu时间
以上两函数,返回小数形式的秒数时间,实际的时间值没有意义,为得到有意义的结果,得执行两次然后计算差值;
In [317]: def countdown(n):
...: while n > 0:
...: n -= 1
...:
In [324]: class Timer:
...: def __init__(self, func=time.perf_counter):
...: self.elapsed = 0.0
...: self._func = func
...: self._start = None
...: def start(self):
...: if self._start is not None:
...: raise RuntimeError('Already started')
...: self._start = self._func()
...: def stop(self):
...: if self._start is None:
...: raise RuntimeError('Not started')
...: end = self._func()
...: self.elapsed += end - self._start
...: self._start = None
...: def reset(self):
...: self.elapsed = 0.0
...: @property
...: def running(self):
...: return self._start is not None
...: def __enter__(self):
...: self.start()
...: return self
...: def __exit__(self, *args):
...: self.stop()
...:
In [325]: with Timer() as t:
...: countdown(1000000)
...:
In [326]: print(t.elapsed)
0.05491612638309107
14、限制内存和cpu的使用量resource.getrlimit()|resource.setrlimit()
P513
15、启动一个web浏览器webbrowser
webbrowser.open('http://www.python.org') #启动一个浏览器,使用默认浏览器打开指定网页,与平台无关
webbrowser.open_new() #对网页打开方式做更多控制
webbrowser.open_new_tab()
c = webbrowser.get('firefox') #指定浏览器
c.open()
c.open_new_tab()
八、类与对象
1、改变对象的字符串显示__str__()|__repr__()
__repr__() #返回一个实例的代码表示形式,通常用来重新构造这个实例,内置的repr()返回这个字符串,跟用交互式解释器显示的值是一样的
__str__() #将实例转换为一个字符串,使用str()或print()会输出这个字符串,如果该方法未定义就会使用__repr__()来代替输出
自定义__repr__()和__str__()通常是好的习惯,因为它能简化调试和实例输出,会看到实例更加详细与有用的信息;
'{!r}'.format() #格式化时的!r表示指明输出使用__repr__()来代替默认的__str__()
In [327]: class Pair:
...: def __init__(self, x, y):
...: self.x = x
...: self.y = y
...: def __repr__(self):
指代self
...: def __str__(self):
...: return '({0.x!s}, {0.y!s})'.format(self)
...:
In [328]: p = Pair(3,4)
In [329]: p
Out[329]: Pair(3, 4)
In [330]: print(p)
(3, 4)
2、自定义字符串的格式化__format__()
__format__() #此方法给py的字符串格式化功能提供了一个钩子,着重强调的是格式化代码的解析工作完全由类自己决定,因此格式化代码可以是任何值,参照datetime.date
In [334]: _formats = {'ymd': '{d.year}-{d.month}-{d.day}','mdy': '{d.month}/{d.day}/{d.
...: year}','dmy': '{d.day}/{d.month}/{d.year}'}
In [341]: class Date:
...: def __init__(self, year, month, day):
...: self.year = year
...: self.month = month
...: self.day = day
...: def __format__(self, code):
...: if code == '':
...: code = 'ymd'
...: fmt = _formats[code]
...: return fmt.format(d=self)
...:
In [342]: d = Date(2019, 11, 16)
In [343]: format(d)
Out[343]: '2019-11-16'
In [344]: 'The date is {:mdy}'.format(d)
Out[344]: 'The date is 11/16/2019'
In [345]: 'The date is {:dmy}'.format(d)
Out[345]: 'The date is 16/11/2019'
In [346]: from datetime import date
In [347]: d = date(2019, 11, 16)
In [348]: format(d)
Out[348]: '2019-11-16'
In [349]: format(d, '%A, %B, %d, %Y')
Out[349]: 'Saturday, November, 16, 2019'
In [350]: 'The end is {:%d %b %Y}. Goodbye'.format(d)
Out[350]: 'The end is 16 Nov 2019. Goodbye'
3、让对象支持上下文管理协议__enter__()|__exit__()|contextmanager
为兼容with语句,需实现__enter__()和__exit__();
当出现with语句时,对象的__enter__()被触发,它返回的值被赋值给as声明的变量,然后with语句块里的代码开始执行,最后__exit__()被触发进行清理工作;
不管with代码块中发生什么,LazyConnection中的控制流都会执行完,就算代码块中发生异常也一样,__exit__()中第三个参数包含了异常类型|异常值|追溯信息,__exit__()方法能自己决定怎样利用这个异常信息,或忽略它返回None,如果__exit__()返回True那么异常会被清空,好像什么都没发生一样,with语句后的程序继续正常执行;
在需要管理一些资源,如文件|网络连接|锁的编程环境中,使用上下文管理器很普遍,这些资源的一个重要特征是它们必须被手动的关闭或释放来确保程序的正确运行,如请求了一个锁那就必须确保之后要释放它,否则可能会产生死锁;
在contextmanager模块中有一个标准的上下文管理方案模板可参考;
In [351]: from socket import socket, AF_INET, SOCK_STREAM
In [352]: class LazyConnection: #此类表示了一个网络连接,初始化时并没建立连接,连接的建立和关闭是用with语句自动完成的;此例只能允许一个socket连接,如果正在使用一个socket时又重复使用with语句就会产生异常
...: def __init__(self, address, family=AF_INET, type=SOCK_STREAM):
...: self.address = address
...: self.family = family
...: self.type = type
...: self.sock = None
...: def __enter__(self):
...: if self.sock is not None:
...: raise RuntimeError('Already connected')
...: self.sock = socket(self.family, self.type)
...: self.sock.connect(self.address)
...: return self.sock
...: def __exit__(self, exc_ty, exc_val, tb):
...: self.sock.close()
...: self.sock = None
...:
In [3]: class LazyConnection: #支持多个嵌套with语句,LazyConnection被看作是连接工厂,在内部列表被用来构造一个栈,每次__enter__()执行时它复制创建一个新的连接,并将其加入到栈里面,__exit__()简单的从栈中弹出最后一个连接并关闭它
...: def __init__(self, address, family=AF_INET, type=SOCK_STREAM):
...: self.address = address
...: self.family = family
...: self.type = type
...: self.connections = []
...: def __enter__(self):
...: sock = socket(self.family, self.type)
...: sock.connect(self.address)
...: self.connections.append(sock)
...: return sock
...: def __exit__(self, exc_ty, exc_val, tb):
...: self.connections.pop().close()
...:
In [4]: from functools import partial
In [5]: conn = LazyConnection(('www.python.org', 80))
In [6]: with conn as s1:
...: pass
...: with conn as s2:
...: pass
...:
4、创建大量对象时节省内存的方法__slots__
__slots__ #定义该属性后,py就会为实例使用一种更加紧凑的内部表示,实例通过一个很小的固定大小的数组来构建,而不是为每个实例定义一个字典,这跟tuple|list类似,在__slots__中列出的属性名在内部被映射到这个数组的指定小标上;使用__slots__不好处是,不能再给实例添加新的属性了,只能使用在__slots__中定义的那些属性名

In [7]: class Date:
...: __slots__ = ['year', 'month', 'day']
...: def __init__(self, year, month, day):
...: self.year = year
...: self.month = month
...: self.day = day
...:
5、在类中封装属性名_
_开头的命名 #任何以_开头的名字都应该是内部实现,同样也适用于模块名和模块级别函数(模块级别函数在使用时比sys._getframe()得加倍小心),py并不会真的阻止访问这些属性,但如果这么做不好可能会导致脆弱的代码
__开头的命名 #使用__开始会导致名称变成其它形式,如类B和类C中,_B__private|_B__private_method和_C__private|_C__private_method是不一样的,目的是继承用,这种属性通过继承是无法被覆盖的
使用注意:
大多数情况下,非公共名称以_开头方案;
如果代码涉及到子类,且有些内部属性应在子类中隐藏,才考虑使用__方案;
如果定义的一个变量和某个保留关键字冲突,使用_作为后缀,如lambda_ = 2.0,这里不使用_前缀的原因是避免误解它的使用初衷(使用_前缀的目的是为了防止命名冲突而不是指明这个属性是私有的)
In [8]: class A:
...: def __init__(self):
...: self._internal = 0
...: self.public = 1
...: def public_method(self):
...: pass
...: def _internal_method(self):
...: pass
...:
In [9]: class B:
...: def __init__(self):
...: self.__private = 0
...: def __private_method(self):
...: pass
...: def public_method(self):
...: pass
...: self.__private_method()
...:
In [11]: class C(B):
...: def __init__(self):
...: self.__private = 0
...: def __private_method(self):
...: pass
...: def public_method(self):
...: pass
...: self.__private_method()
...:
6、创建可管理的属性@property
@property #的一个关键特征是它看上去跟普通的attribute没区别,但访问它时会自动触发getter|setter|deleter方法;
一个property属性其实就是一系列相关方法的集合,查看拥有property的类,发现property本身的fget|fset|fdel属性就是类里面的普通方法,通常不会直接调用fget|fset,它会在访问property时自动被触发;
只有当需要对attribute执行其它额外操作时才应使用property,不要写没做任何其它额外操作的property,1代码臃肿易出错丑陋且会迷惑阅读者,2程序运行会变慢,3 P241;
property还是一种定义动态计算attribute的方法,这种类型的attribute并不会被实际的存储,而是在需要时计算出来,对半径|直径|周长|面积的访问都通过属性访问,跟访问简单的attribute一样,如:
@property
def area(self):
return math.pi * self.radius ** 2
In [12]: class Person:
...: def __init__(self, first_name):
...: self.first_name注意此处为self.first_name不是self._first_name,是想在初始化时也进行类型检查,初始化时会自动调用setter方法进行参数检查
...: @property
...: def first_name(self): #这3个方法的名字必须一样,依次为getter|setter|deleter函数,getter函数使得first_name成为一个属性,只有在getter被创建后setter和deleter才能被定义
...: return self._first_name
...: @first_name.setter
...: def first_name(self, value):
...: if not isinstance(value, str):
...: raise TypeError('Expected a string')
...: self._first_name = value
...: @first_name.deleter
...: def first_name(self):
...: raise AttributeError("Can't delete attribute")
...:
In [13]: a = Person('Guido')
In [14]: a.first_name
Out[14]: 'Guido'
In [15]: a.first_name = 42
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-6341bdece797> in <module>
----> 1 a.first_name = 42
<ipython-input-12-d496c776c69d> in first_name(self, value)
8 def first_name(self, value):
9 if not isinstance(value, str):
---> 10 raise TypeError('Expected a string')
11 self._first_name = value
12 @first_name.deleter
TypeError: Expected a string
In [16]: del a.first_name
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-16-50ce9077a584> in <module>
----> 1 del a.first_name
<ipython-input-12-d496c776c69d> in first_name(self)
12 @first_name.deleter
13 def first_name(self):
---> 14 raise AttributeError("Can't delete attribute")
15
AttributeError: Can't delete attribute
In [23]: Person.first_name.fget
Out[23]: <function __main__.Person.first_name(self)>
In [24]: Person.first_name.fset
Out[24]: <function __main__.Person.first_name(self, value)>
In [25]: Person.first_name.fdel
Out[25]: <function __main__.Person.first_name(self)>
7、调用父类的方法super()
要正确使用super(),super().__init__(),不要直接用Base.__init__(self),在复杂情况下如多继承代码中就可能导致问题发生,比如父类Base.__init__()会被调用多次;
原因是py实现多继承的原理:
对于定义的每一个类,py会计算出一个所谓的方法解析顺序MRO列表(C.__mro__是一个简单的所有基类的线性顺序表),为实现继承py会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止;
这个MRO列表的构造是通过一个C3线性算法来实现的,实际上是合并所有父类的MRO列表并遵循3条准则(子类会先于父类被检查|多个父类会根据它们在列表中的顺序被检查|如果对下一个类存在两个合法的选择会选择第一个父类);
需要知道的是MRO列表中的类顺序会让我们定义的任意类层次级关系变得有意义;
使用super()时,py会在MRO列表上继续搜索下一个类,只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用1次;
P246
用法1,在__init__()确保父类被正确的初始化了;
用法2,出现在覆盖py特殊方法的代码中;
8、子类中扩展property
P250
9、创建新的类或实例属性__get__()|__set__()|__delete__()
创建一个新的拥有一些额外功能的实例属性类型,如类型检查;
一个描述器就是一个实现了3个核心的属性访问操作(get|set|delete)的类,分别为__get__()|__set__()|__delete__()这三个特殊的方法,这些方法接受一个实例作为输入,之后相应的操作实例底层的__dict__;
描述器可实现大部分py类特性中的底层魔法,包括@classmethod|@staticmethod|@property甚至是__slots__;
通过定义一个描述器,可在底层捕获核心的实例操作(get|set|delete),且可完全自定义它们的行为,这是一个强大的工具,有了它就可实现很多高级功能,并且它也是很多高级库和框架中的重要工具之一;
描述器的一个比较困惑的地方是它只能在类级别被定义,而不能为每个实例单独定义;
描述器通常是那些使用到装饰器或元类的大型框架中的一个组件,同时它们的使用也被隐藏在后面;
如果一个描述器仅定义了一个__get__(),它比通常的具有更弱的绑定,只有当被访问属性不在实例底层的__dict__时__get__()方法才会被触发;
P252
10、使用延迟计算特性_描述器类
P254
如果一个描述器仅定义了一个__get__(),它比通常的具有更弱的绑定,只有当被访问属性不在实例底层的__dict__时__get__()方法才会被触发;

11、简化数据结构的初始化
P258
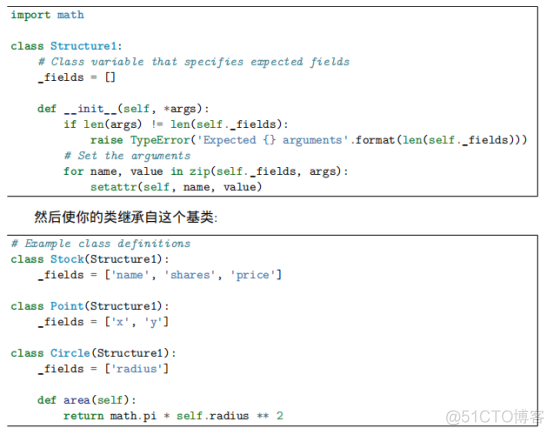
12、定义接口或抽象基类abc
定义一个接口或抽象类,通过执行类型检查来确保子类实现了某些特定的方法;
from abc import ABCMeta, abstractmethod
抽象类的1个特点是,它不能直接被实例化;
抽象类的目的是,让别的类继承它并实现特定的抽象方法;
抽象类的主要用途,在代码中检查某些类是否为特定类型,实现了特定接口;

13、实现数据模型的类型约束
五、文件与IO
1、读写文本数据open()
rt #读取文本文件
wt #写入一个文本文件
at #在已存在文件中添加内容
encoding='utf-8' #如果确定读写的文本是其它编码使用encoding指定,py支持的有ascii|latin-1|utf-8|utf-16,web应用程序中通常使用的都是utf-8
In [37]: sys.getdefaultencoding() #文件的读写操作使用的系统编码
Out[37]: 'utf-8'
注意:
1、在没用with语句时,要记得手动关闭文件,f = open('somefile.txt', 'rt'),data = f.read(),f.close();
2、换行符的识别,unix中是\n,win中是\r\n,默认py会以统一模式处理换行符,这种模式下,在读取文本时,py可识别所用的普通换行符并将其转换为单个\n字符,在输出时会将换行符\n转换为系统默认的换行符,如果不希望这种默认的处理方式,可给open()传入参数newline='';
3、文本文件中可能出现的编码错误,最好确认该文件的编码是正确的;
2、打印输出至文件中print('content', file=f)
In [39]: with open(r'c:/test.txt', 'wt') as f:
中指定file关键字参数
...:
3、使用其它分隔符或行终止符打印print('content', sep=',', end='!!\n')
在print()中使用sep和end关键字参数,end参数也可在输出中禁止换行;
In [40]: print('ACME', 50, 91.5)
ACME 50 91.5
In [41]: print('ACME', 50, 91.5, sep=',')
ACME,50,91.5
In [42]: print('ACME', 50, 91.5, sep=',', end='!!\n')
ACME,50,91.5!!
In [43]: for i in range(3):
...: print(i, end=' ')
...:
0 1 2
In [47]: row = ('ACME', 50, 91.5)
In [48]: print(*row, sep=',') #使用非空格分隔符输出数据,这种方式最简单;如果用str.join(lst),lst中的元素必须都为字符串,如果不是得转换,这样麻烦
ACME,50,91.5
In [49]: print(','.join(str(x) for x in row))
ACME,50,91.5
4、读写字节数据open()
rb #open()使用的模式,以二进制方式读取数据
wb
在读取二进制数据时:
字节字符串和文本字符串的语义差异可能会导致一个潜在的陷阱,需要注意,索引和迭代动作返回的是字节的值而不是字节字符串;
所有返回的数据都是字节字符串格式,而不是文本字符串,类似在写入时,必须保证参数是以字节形式对外暴露数据的对象,如字节字符串|字节数组对象等;
如果想从二进制模式的文件中读取或写入文本数据,必须确保要进行解码和编码操作;
二进制i/o还有一个鲜为人知的特性是数组和C结构体类型能直接被写入,而不需要中间转换为自己对象,这个适用于任何实现了“缓冲接口”的对象,这种对象会直接暴露其底层的内存缓冲区给能处理它的操作,二进制数据的写入就是这类操作之一;
很多对象还允许通过使用文件对象的readinto()方法直接读取二进制数据到其底层的内存中去,使用这种技术时需格外小心,因为它具有平台相关性,可能会依赖字长和字节顺序(高位优先|低位优先);
with open('somefile.bin', 'rb') as f:
data = f.read()
In [50]: b = b'Hello World'
In [52]: for c in b:
...: print(c, end='\t')
...:
...:
72 101 108 108 111 32 87 111 114 108 100
In [53]: import array
In [55]: nums = array.array('i', [1,2,3,4])
In [56]: with open(r'c:/data.bin', 'wb') as f:
...: f.write(nums)
...:
In [57]: a = array.array('i', [0,0,0,0,0,0,0,0])
In [59]: with open(r'c:/data.bin', 'rb') as f:
...: f.readinto(a)
...:
In [60]:
In [60]: a
Out[60]: array('i', [1, 2, 3, 4, 0, 0, 0, 0])
5、文件不存在才能写入open()
x #open()中使用x模式代替w模式,xt|xb,仅py3对open()特有的扩展
解决不小心覆盖一个已存在的文件;
In [64]: if not os.path.exists('somefile'): #这种方式没有open('somefile', 'xt')好
...: with open('somefile', 'wt') as f:
...: f.write('Hello\n')
...: else:
...: print('File alredy exists!')
...:
6、字符串的I/O操作io.StringIO()|io.BytesIO()
使用操作类文件对象的程序来操作文本或二进制字符串;
io.StringIO() #用于文本
io.BytesIO() #用于二进制数据
注意,StringIO|BytesIO实例并没有正确的整数类型的文件描述符,因此它们不能在那些需要使用真实的系统级文件如文件|管道|套接字的程序中使用;
用途:
在单元测试中,可用StringIO来创建一个包含测试数据的类文件对象,该对象可被传给某个参数为普通文件对象的函数;
In [66]: import io
In [67]: s = io.StringIO()
In [68]: s.write('Hello World\n')
Out[68]: 12
In [69]: print('This is a test', file=s)
In [70]: s.getvalue()
Out[70]: 'Hello World\nThis is a test\n'
In [71]: s = io.StringIO('Hello\nWorld\n')
In [72]: s.read(4)
Out[72]: 'Hell'
In [73]: s.read()
Out[73]: 'o\nWorld\n'
7、读写压缩文件gzip.open()|bz2.open()
gzip.open() #默认二进制模式,.open()接受的参数同内置open(),当写入数据时compresslevel=5来指定压缩级别,默认9最高压缩级别,0-9,等级越低性能越好数据压缩程度越低;rt|wt,所有的I/O操作都使用文本模式并执行Unicode编码/解码,如果操作二进制数据,用rb|wb
bz2.open()
gzip.open()|bz2.open()还有一特性是,可作用在一个已存在并以二进制模式打开的文件上,这样就允许gzip和bz2模块可工作在许多类文件对象上,如套接字|管道|内存中文件;
with gzip.open('somefile.gz', 'wt', compresslevel=5) as f:
f.write(text)
import gzip
f = open('somefile.gz', 'rb')
with gzip.open(f, 'rt') as g:
text = g.read()
8、固定大小记录的文件迭代functools.partial()|iter()
from functools import partial
RECORD_SIZE = 32
with open('somefile.data', 'rb') as f: #以二进制模式打开的文件,通常是读取固定大小的记录;对于文本文件,通常是一行一行地读取
对象是一个可迭代对象,它会不断的产生固定大小的数据块,直到文件末尾,注意如果总记录大小不是块大小的整数倍的话,最后一个返回的元素的字节数会比期望值少
for r in records:
......
P145
9、读取二进制数据到可变缓冲区中_f.readinto()
P147
def read_into_buffer(filename):
buf = bytearray(os.path.getsize(filename))
with open(filename, 'rb') as f:
f.readinto(buf)
return buf
>with open('sample.bin', 'wb') as f:
f.write(b'Hello World')
>buf = read_into(buffer('sample.bin')
>buf[0:5] = b'Hallo'
>with open('newsample.bin', 'wb') as f:
f.write(buf)
10、内存映射的二进制文件mmap
P149
11、文件路径名的操作os.path中的函数
os.path #对于任何的文件名的操作,都应使用os.path模块,而不是使用标准字符串操作来构造自己的代码(不应浪费时间重复造轮子),特别是为了可移植性考虑时更应如此
In [74]: path = '/Users/beazley/Data/data.csv'
In [75]: os.path.basename(path)
Out[75]: 'data.csv'
In [76]: os.path.dirname(path)
Out[76]: '/Users/beazley/Data'
In [77]: os.path.join('tmp', 'data', os.path.basename(path))
Out[77]: 'tmp\\data\\data.csv'
In [78]: path = '~/Data/data.csv'
In [79]: os.path.expanduser(path)
Out[79]: 'C:\\Users\\Administrator.SC-201908130831/Data/data.csv'
In [81]: os.path.splitext(path)
Out[81]: ('~/Data/data', '.csv')
12、测试文件是否存在os.path.exists()
操作时注意文件权限问题,尤其是获取元数据时;
In [82]: os.path.exists(r'c:/test.txt')
Out[82]: True
In [83]: os.path.isfile(r'c:/test.txt')
Out[83]: True
In [84]: os.path.isdir(r'c:/test.txt')
Out[84]: False
In [85]: os.path.islink(r'c:/test.txt')
Out[85]: False
In [86]: os.path.realpath('c:/test.txt')
Out[86]: 'c:\\test.txt'
In [87]: os.path.getsize('c:/test.txt')
Out[87]: 14
In [88]: os.path.getmtime('c:/test.txt')
Out[88]: 1574055034.3199937
In [89]: import time
In [90]: time.ctime(os.path.getmtime(r'c:/test.txt'))
Out[90]: 'Mon Nov 18 13:30:34 2019'
13、获取目录中的文件列表os.listdir()
os.listdir() #返回目录中所有文件列表,包括文件|子目录|符号链接等,如果还想获取其它元信息,要用到os.path|os.stat()来收集数据;另,可结合os.path|列表推导过滤数据;os.listdir()返回的实体列表会根据系统默认的文件名编码来解码,但有时也有不能正常解码的文件名
names = [name for name in os.listdir('somedir') if os.path.isfile(os.path.join('somedir', name))]
dirnames = [name for name in os.listdir('somedir') if os.path.isdir(os.path.join('somedir', name))]
pyfiles = [name for name in os.listdir('somedir') if name.endswith('.py')]
import glob
pyfiles = glob.glob('somedir/*.py')
from fnmatch import fnmatch
pyfiles = [name for name in os.listdir('somedir') if fnmatch(name, '*.py')]
pyfiles = glob.glob('*.py')
name_sz_date = [(name, os.path.getsize(name), os.path.getmtime(name)) for name in pyfiles]
for name, size, mtime in name_sz_date:
print(name, size, mtime)
file_metadata = [(name, os.stat(name)) for name in pyfiles]
for name, meta in file_metadata:
print(name, meta.st_size, meta.st_mtime)
14、忽略文件名编码
使用一个原始字节字符串来指定一个文件名即可,如with open('jalape\xf1o.txt', 'w') as f:
In [93]: sys.getfilesystemencoding() #默认所有文件名都会根据此编码和解码
Out[93]: 'utf-8'
In [94]: with open('jalape\xf1o.txt', 'w') as f:
...: f.write('Spicy!')
...:
In [95]: os.listdir('.')
Out[95]:
['chardetect.exe',
'jalapeño.txt',
'somefile']
In [96]: os.listdir(b'.')
Out[96]:
[b'chardetect.exe',
b'jalape\xc3\xb1o.txt',
b'somefile']

15、打印不合法的文件名
当打印文件名时出现UnicodeEncodeError|surrogates not allowed,解决办法:
def bad_filename(filename):
return repr(filename)[1:-1]
try:
print(filename)
except UnicodeEncodeError:
print(bad_filename(filename))
16、增加或改变已打开文件的编码io.TextIOWrapper()
import io
from urllib.request import urlopen
u = urlopen('http://www.python.org')
f = io.TextIOWrapper(u, encoding='utf-8')
text = f.read()
17、将字节写入文本文件
在文本模式打开的文件中写入原始的字节数据(将字节数据直接写入文件的缓冲区即可);
import sys
sys.stdout.buffer.write(b'Hello\n') #sys.stdout.write('Hello\n')
In [107]: sys.stdout.buffer.write(b'Hello\n')
Hello
Out[107]: 6
18、将文件描述符包装成文件对象
将对应于OS上一个已打开的I/O通道的整型文件描述符(如文件|管道|套接字),包装成一个更高层的py文件对象;
一个文件描述符和一个打开的普通文件是不一样的,文件描述符仅仅是一个由操作系统指定的整数,用来指代某个系统的I/O通道,可用open()将其包装成一个py的文件对象;
在Unix中,这种包装文件描述符的技术可方便地将一个类文件接口作用于一个以不同方式打开的I/O通道上,如管道|套接字;
In [109]: fd = os.open(r'c:/test.txt', os.O_WRONLY|os.O_CREAT)
In [110]: f = open(fd, 'wt') #f = open(fd, 'wt', closefd=False),当高层的文件对象被关闭或破坏时,底层的文件描述符也会被关闭,如果这不是我们想要的可用closefd=False
In [111]: f.write('hhhhhhhhhhhhh\n')
Out[111]: 14
In [112]: f.close()
19、创建临时文件和文件夹tempfile.TemporaryFile|tempfile.NamedTemporaryFile|tempfile.TemporaryDirectory
程序执行时创建一个临时文件或目录,使用完后自动销毁;
from tempfile import TemporaryFile, NamedTemporaryFile, TemporaryDirectory
在unix上,TemporaryFile()创建的文件都是匿名的,甚至连目录都没有,如果想打破这个限制可用NamedTemporaryFile()代替,f.name属性为临时文件的文件名,当需要将文件名传递给其它代码来打开这个文件时会有用,和TemporaryFile()一样,文件关闭时会被自动删除掉,如果不这么做用delte=False
另,tempfile.mkstemp()|tempfile.mkdtemp(),可在更低级别创建临时文件和目录,并不会做进一步的管理,仅返回一个原始的OS文件描述符,需要自己将它转为一个真正的文件对象并清理这些文件;
tempfile.gettempdir() #临时文件在系统默认的位置被创建,如/var/tmp/
f = NamedTemporaryFile(prefix='mytemp', suffix='.txt', dir='/tmp') #所有临时文件相关函数都允许通过关键字参数prefix|suffix|dir来自定义目录及命名规则
f.name
In [115]: with TemporaryFile('w+t') as f: #模式'w+t'|'w+b',这个模式同时支持rw操作,还支持跟open()一样的参数encoding='utf-8',errors='ignore'
...: f.write('Hello world\n')
...: f.write('Testing\n')
...: f.seek(0)
...: data = f.read()
...: print(data)
...:
Hello world
Testing
In [116]: from tempfile import NamedTemporaryFile
In [117]: with NamedTemporaryFile('w+t') as f:
...: print(f.name)
...:
C:\Users\ADMINI~1.SC-\AppData\Local\Temp\tmpuim869zd
In [118]: from tempfile import TemporaryDirectory
In [119]: with TemporaryDirectory() as dirname:
...: print(dirname)
...:
C:\Users\ADMINI~1.SC-\AppData\Local\Temp\tmppff7oo_8
In [121]: from tempfile import gettempdir
In [122]: gettempdir() #临时文件在系统默认的位置被创建,如/var/tmp/
Out[122]: 'C:\\Users\\ADMINI~1.SC-\\AppData\\Local\\Temp'
20、与串行端口的数据通信serial
典型场景是和一些硬件设备打交道,如机器人|传感器;
所有涉及到串口的I/O都是二进制模式的,因此确保代码使用的是字节而不是文本,另当需要创建二进制编码的指令或数据包时,struct模块有用;
pip install pySerial #提供了对高级特性的支持,如超时|控制流|缓冲区刷新|握手协议等
21、序列化py对象pickle
import pickle
pickle.dump()
pickle.dumps() #将一个对象转储为一个字符串
pickle.load()
pickle.loads() #从字节流中恢复一个对象
六、数据编码和处理
1、读写csv数据csv.reader()|csv.DictReader()|csv.writer()|csv.DictWriter()
应优先选择csv模块来解析csv数据,如果自己手动分割row = line.split(',')还要处理一些棘手的细节问题,如被引号包围的字段值中有逗号程序会出错;
默认csv可识别excel所使用的csv编码规则,会带来最好的兼容性;
支持用tab分割的数据,f_csv = csv.reader(f, delimiter='\t')
读取数据时使用命名元组,要注意对列名进行合法性认证(要是py标识符),否则报ValueError;
csv产生的数据都是字符串类型的,它不会做任何其它类型的转换,要自己手动实现;
如果读取csv数据的目的是做数据分析和统计,用Pandas包,它包含了一个非常方便的函数pandas.read_csv()可加载csv数据到一个DataFrame对象中,然后利用这个对象可生成各种形式的统计|过滤数据及其它高级操作;
In [1]: import csv
In [2]: with open(r'c:/test.txt') as f:
返回reader对象
返回列表
...: for row in f_csv:
...: print(row) #访问字段需用row[0]这种方式
...:
['AA', '39.48', '6/11/2007', '9:36am', '-0.18', '181800']
['AIG', '71.38', '6/11/2007', '9:36am', '-0.15', '195500']
['AXP', '62.58', '6/11/2007', '9:36am', '-0.46', '935000']
['BA', '98.31', '6/11/2007', '9:36am', '+0.12', '104800']
['C', '53.08', '6/11/2007', '9:36am', '-0.25', '360900']
['CAT78.29"6/11/2007""9:36"0.232254']
In [6]: with open(r'c:/test.txt') as f:
...: f_csv = csv.reader(f)
...: headers = next(f_csv)
...: Row = namedtuple('Row', headers)
...: for r in f_csv:
...: row = Row(*r)
...: print(row) #可用row.Symbol,row.Change访问,前提列名要为合法的py标识符,否则要改原始的列名
...:
Row(Symbol='AA', Price='39.48', Date='6/11/2007', Time='9:36am', Change='-0.18', Volume='181800')
Row(Symbol='AIG', Price='71.38', Date='6/11/2007', Time='9:36am', Change='-0.15', Volume='195500')
Row(Symbol='AXP', Price='62.58', Date='6/11/2007', Time='9:36am', Change='-0.46', Volume='935000')
Row(Symbol='BA', Price='98.31', Date='6/11/2007', Time='9:36am', Change='+0.12', Volume='104800')
Row(Symbol='C', Price='53.08', Date='6/11/2007', Time='9:36am', Change='-0.25', Volume='360900')
Row(Symbol='CAT', Price='78.29', Date='6/11/2007', Time='9:36am', Change='-0.23', Volume='225400')
In [12]: with open(r'c:/test.txt') as f:
...: f_csv = csv.DictReader(f)
...: for row in f_csv:
...: print(row) #可用row['Symbol']访问
...:
OrderedDict([('Symbol', 'AA'), ('Price', '39.48'), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', '-0.18'), ('Volume', '181800')])
OrderedDict([('Symbol', 'AIG'), ('Price', '71.38'), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', '-0.15'), ('Volume', '195500')])
OrderedDict([('Symbol', 'AXP'), ('Price', '62.58'), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', '-0.46'), ('Volume', '935000')])
OrderedDict([('Symbol', 'BA'), ('Price', '98.31'), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', '+0.12'), ('Volume', '104800')])
OrderedDict([('Symbol', 'C'), ('Price', '53.08'), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', '-0.25'), ('Volume', '360900')])
OrderedDict([('Symbol', 'CAT'), ('Price', '78.29'), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', '-0.23'), ('Volume', '225400')])
In [15]: headers = ['Symbol','Price','Date','Time','Change','Volume']
In [17]: rows = [('AA', 39.48, '6/11/2007', '9:36am', -0.18, 181800),('AIG', 71.38, '6/11/2007', '9:36am', -0.15, 19550
...: 0),('AXP', 62.58, '6/11/2007', '9:36am', -0.46, 935000)]
In [19]: with open(r'c:/test.txt','w') as f:
...: f_csv = csv.writer(f)
...: f_csv.writerow(headers)
是一行一行写入,writerows()是一次写多行
...:
In [20]: rows = [{'Symbol':'AA', 'Price':39.48, 'Date':'6/11/2007','Time':'9:36am', 'Change':-0.18, 'Volume':181800},{'
...: Symbol':'AIG', 'Price': 71.38, 'Date':'6/11/2007','Time':'9:36am', 'Change':-0.15, 'Volume': 195500},{'Symbol'
...: :'AXP', 'Price': 62.58, 'Date':'6/11/2007','Time':'9:36am', 'Change':-0.46, 'Volume': 935000}]
In [21]: with open(r'c:/test.txt','w') as f:
...: f_csv = csv.DictWriter(f, headers)
...: f_csv.writeheader()
...: f_csv.writerows(rows)
...:
In [22]: col_types = [str, float, str, str, float, int]
In [23]: with open(r'c:/test.txt') as f:
...: f_csv = csv.reader(f)
...: headers = next(f_csv)
...: for row in f_csv:
...: row = tuple(convert(value) for convert, value in zip(col_types, row))
...: print(row)
...:
()
('AA', 39.48, '6/11/2007', '9:36am', -0.18, 181800)
()
('AIG', 71.38, '6/11/2007', '9:36am', -0.15, 195500)
()
('AXP', 62.58, '6/11/2007', '9:36am', -0.46, 935000)
()
In [24]: field_types = [('Price', float),('Change', float),('Volume', int)]
In [25]: with open(r'c:/test.txt') as f:
...: for row in csv.DictReader(f):
...: row.update((key, convert(row[key])) for key, convert in field_types)
...: print(row)
...:
OrderedDict([('Symbol', 'AA'), ('Price', 39.48), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', -0.18), ('Volume', 181800)])
OrderedDict([('Symbol', 'AIG'), ('Price', 71.38), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', -0.15), ('Volume', 195500)])
OrderedDict([('Symbol', 'AXP'), ('Price', 62.58), ('Date', '6/11/2007'), ('Time', '9:36am'), ('Change', -0.46), ('Volume', 935000)])
2、读写json数据json.dumps()|json.loads()
json编码支持的基本数据类型为None|bool|int|float|str及包含这些类型数据的list|tuple|dict,对于dict,key需要是字符串类型(如果是非字符串类型会转为字符串);
为遵循json规范,应只编码py的list|dict;
在web应用中,顶层对象被编码为一个dict是一个标准做法;
json编码格式对于py语法几乎是完全一样的,有一些小差异,如True-true,False-false,None-null;
json.dumps() #py-->json,在编码json时,若想有漂亮的格式化后输出,用indent参数,使得输出和pprint()类似
json.loads() #json-->py数据结构,一般json解码会根据提供的数据创建dict|list,如果想创建其它类型的对象,用object_pairs_hook或object_hook参数;
from pprint import pprint #可用此函数代替print(),它会按key的字母顺序并以一种更美观的方式输出
In [28]: import json
In [26]: data = {'name': 'ACME', 'shares':100, 'price':542.23}
In [30]: json_str = json.dumps(data) #py数据结构-->json
In [31]: json_str
Out[31]: '{"name": "ACME", "shares": 100, "price": 542.23}'
In [32]: data = json.loads(json_str) #json-->py
In [33]: data
Out[33]: {'name': 'ACME', 'shares': 100, 'price': 542.23}
In [35]: from collections import OrderedDict
In [36]: json_str
Out[36]: '{"name": "ACME", "shares": 100, "price": 542.23}'
In [38]: data = json.loads(json_str, object_pairs_hook=OrderedDict) #json-->py的OrderedDict
In [39]: data
Out[39]: OrderedDict([('name', 'ACME'), ('shares', 100), ('price', 542.23)])
In [40]: class PyObject:
...: def __init__(self, d):
...: self.__dict__ = d
...:
In [41]: data = json.loads(json_str, object_hook=PyObject) #json-->py对象,json解码后的字典作为一个单个参数传递给__init__(),然后就可以随心所欲的使用了
In [42]: data
Out[42]: <__main__.PyObject at 0x1d09dff9278>
In [43]: data.name
Out[43]: 'ACME'
In [46]: data
Out[46]: {'name': 'ACME', 'shares': 100, 'price': 542.23}
In [47]: json_str = json.dumps(data, indent=4)
In [50]: print(json_str)
{
"name": "ACME",
"shares": 100,
"price": 542.23
}

3、解析简单的xml数据xml.etree.ElementTree.parse()
P179
4、增量式解析大型xml文件xml.etree.ElementTruee.iterparse()
用尽可能少的内存从一个超大的xml文档中提取数据;
只要遇到增量式的数据处理,都要想到用迭代器和生成器;
P179
5、将字典转为xmlxml.etree.ElementTruee.Element
P183
6、解析和修改xmlxml.etree.ElementTree.parse()|xml.etree.ElementTree.Element
P185
7、利用命名空间解析xml文档
P187
8、与关系型数据库的交互
py中多行数据的标准方式是一个由元组构成的列表;
import sqlite3
db = sqlite3.connect('database.db')
c = db.cursor()
c.execute('') #执行查询语句,另c.executemany('')插入多条记录
db.commit()
9、编码解码16进制数binascii.b2a_hex()|binascii.a2b_hex()|base64.b16encode()|base64.b16decode()
binascii和base64,这2种技术的主要不同在于大小写的处理,base64只能操作大写形式的16进制字母,而binascii大小写都能处理;
注意:
编码函数所产生的输出总是一个字节字符串,如果想强制以unicode输出,要print(h.decode('ascii));
解码16进制数时,a2b_hex()和b16decode()可接受字节或unicode字符串,但unicode字符串必须仅只包含ascii编码的16进制数;
In [51]: import binascii
In [52]: s = b'hello'
In [53]: h = binascii.b2a_hex(s)
In [54]: h
Out[54]: b'68656c6c6f'
In [55]: binascii.a2b_hex(h)
Out[55]: b'hello'
In [56]: import base64
In [57]: h = base64.b16encode(s)
In [58]: h
Out[58]: b'68656C6C6F'
In [59]: base64.b16decode(h)
Out[59]: b'hello'
10、编码解码base64数据base64.b64encode()|base64.b64decode()
base64编码仅用于面向字节的数据,如字节字符串和字节数组,编码处理的输出结果是一个字节字符串;
如果想混合使用base64编码的数据和unicode文本,必须添加一个额外的解码步骤,a = base64.b64encode(s).decode('ascii');
解码base64时,字节字符串和unicode文本都可作为参数,但unicode字符串只能包含ascii字符;
In [60]: s
Out[60]: b'hello'
In [61]: a = base64.b64encode(s)
In [62]: a
Out[62]: b'aGVsbG8='
In [63]: base64.b64decode(a)
Out[63]: b'hello'
11、读写二进制数组数据struct
P192
12、读取嵌套和可变长二进制数据struct
struct模块可被用来编码解码几乎所有类型的二进制的数据结构;
P196
13、数据的累加与统计操作pandas
对于任何涉及到统计|时间序列|其它相关技术的数据分析问题,可考虑用pandas;
P206
十、模块与包
1、构建一个模块的层级包__init__.py
封装成包,确保每个目录都定义了__init__.py文件,就能执行import语句;
绝大多数时候让__init__.py空着,但有些情况下可能包含代码,如此文件能用来自动加载子模块;
__init__.py还可将多个文件合并到一个逻辑命名空间;
2、控制模块被全部导入的内容__all__
somemodule.py #当用from somemodule import *时,希望从模块或包导出的符号进行精确控制;如果__all__中包含未定义的名字,报AttributeError
def spam():
pass
def grok():
pass
blah = 42
__all__ = ['spam', 'grok']
3、使用相对路径名导入包中子模块
mypackage/
__init__.py
A/
__init__.py
spam.py
grok.py
B/
__init__.py
bar.py
from . import grok #在mypackage.A.spam中,既可用相对路径也可用绝对路径
from ..B import bar ##在mypackage.A.spam中
4、将模块分割成多个文件
5、利用命名空间导入目录分散的代码
6、