elasticsearch集群运维及故障排查
1.elasticsearch集群分片有的地方空缺
问题描述:集群增加到3个节点后,为什么testinfo、linuxbook、index1等索引都出现了很多空缺?
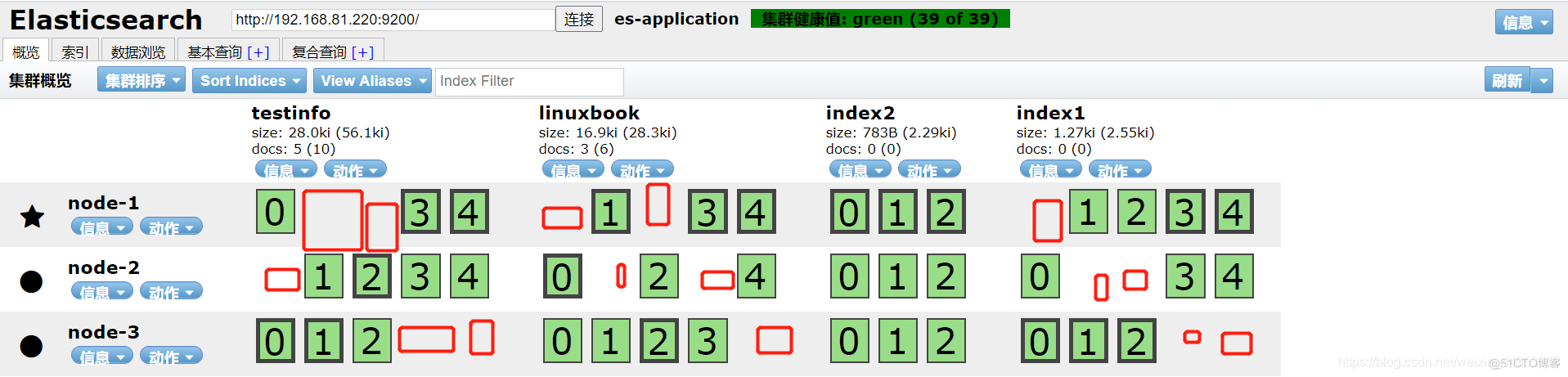
原因:由于我们testinfo、linuxbook、index1等索引库都是默认的副本分片配置,即1副本5分片,副本就是备份,一个节点就相当于一个副本分片的存放,因此抛开主分片,副本分片只有1个,有3个主机,主分片已经存放在一台机器了,那么副本分片就会分开存放,其实主分片、副本分片都会分开存放,这样可以保证数据的完整性,即使有一个node节点坏掉了,数据也是可以恢复的
比如下图,即使node1完全坏掉了,node2和node3都可以互相交替拼凑成一个完整的数据
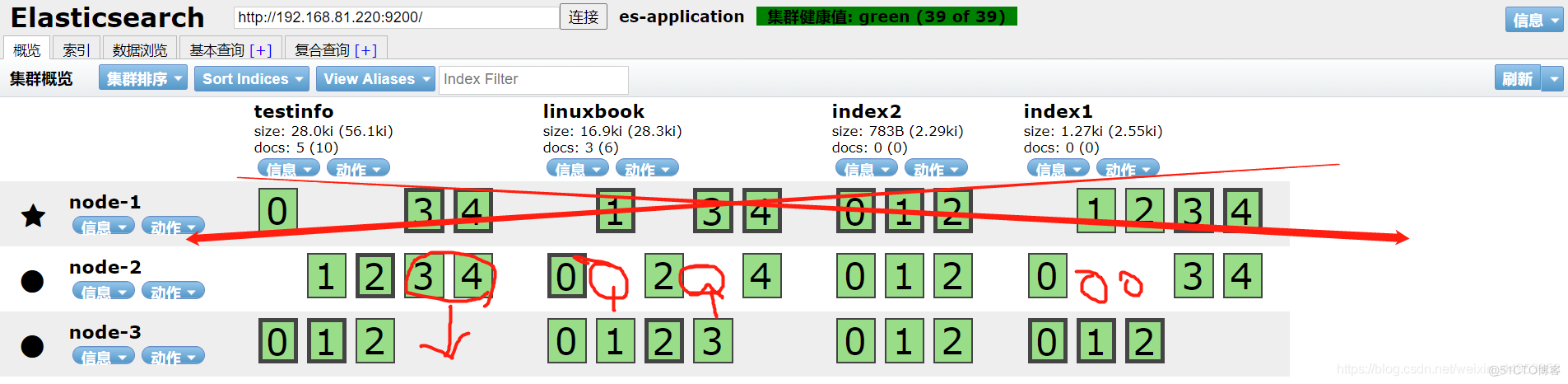
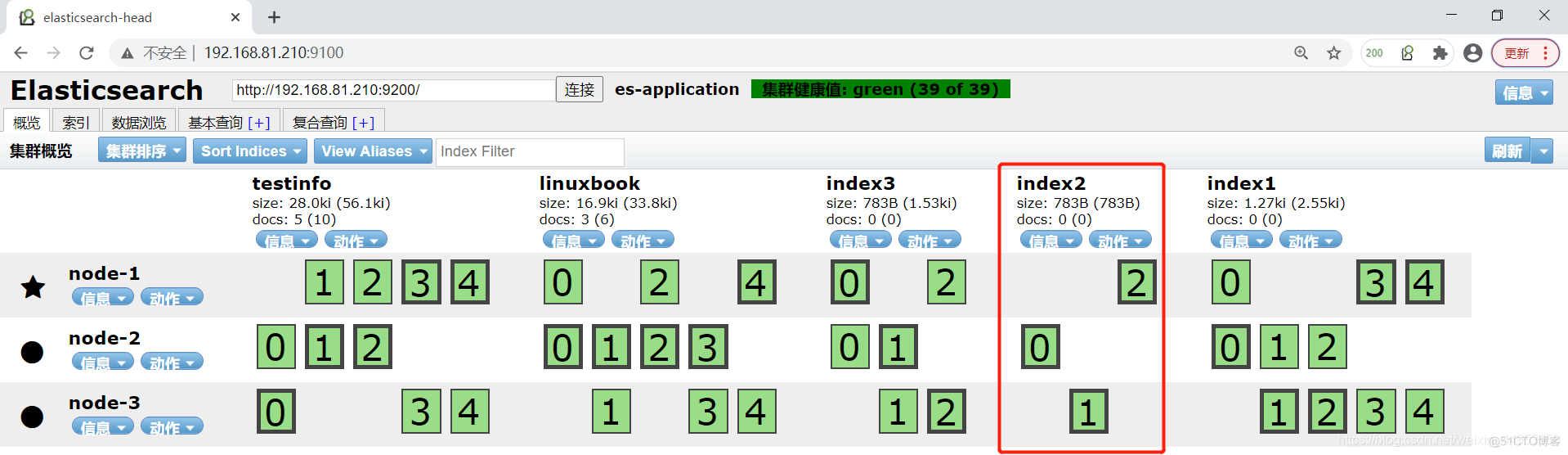
2.主分片副本分片为什么要分散存储
可以看到,图中除了index2,其余都是分散存储的,没有分散存储是因为创建index2索引时,只有两个node节点,但是副本分片却设置了个,因此后来我们新增了一个node节点,才会导致集合在一起
创建一个俩副本的索引
[root@elasticsearch ~]# curl -XPUT 'http://localhost:9200/index3?pretty' -H 'Content-Type: application/json' -d ' > { > "settings": { > "number_of_shards":3, > "number_of_replicas": 2 > } > }' { "acknowledged" : true, "shards_acknowledged" : true, "index" : "index3" }
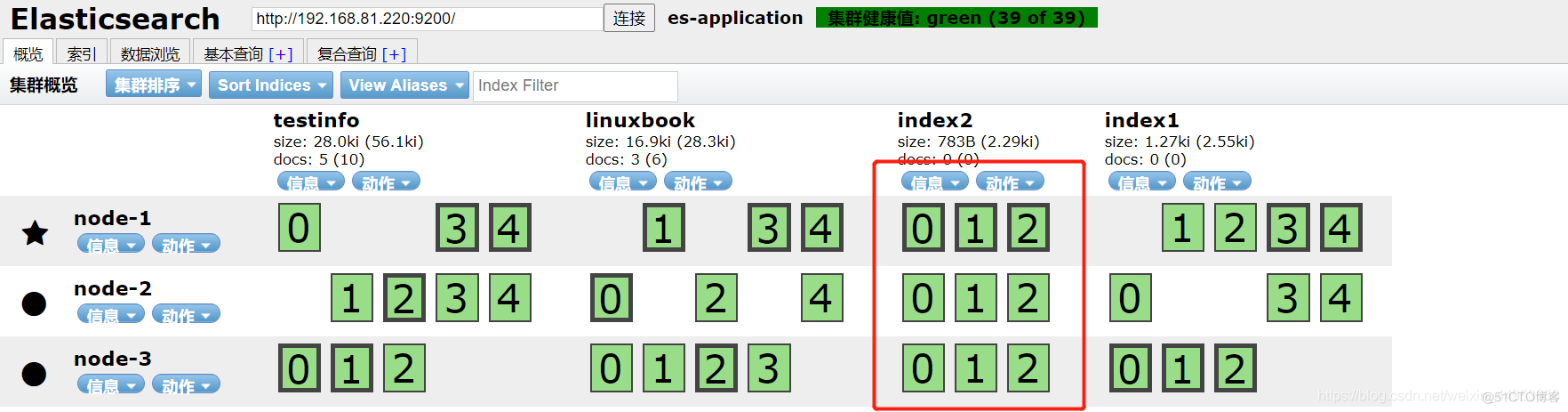
可以非常清楚的看到不同的分片已经分散存储了
分散存储的好处:当一个node坏了,可以将其他node上的数据整合,最终还是不会影响业务的使用
3.将一个node节点停止运行查看分片的散布
停止node2
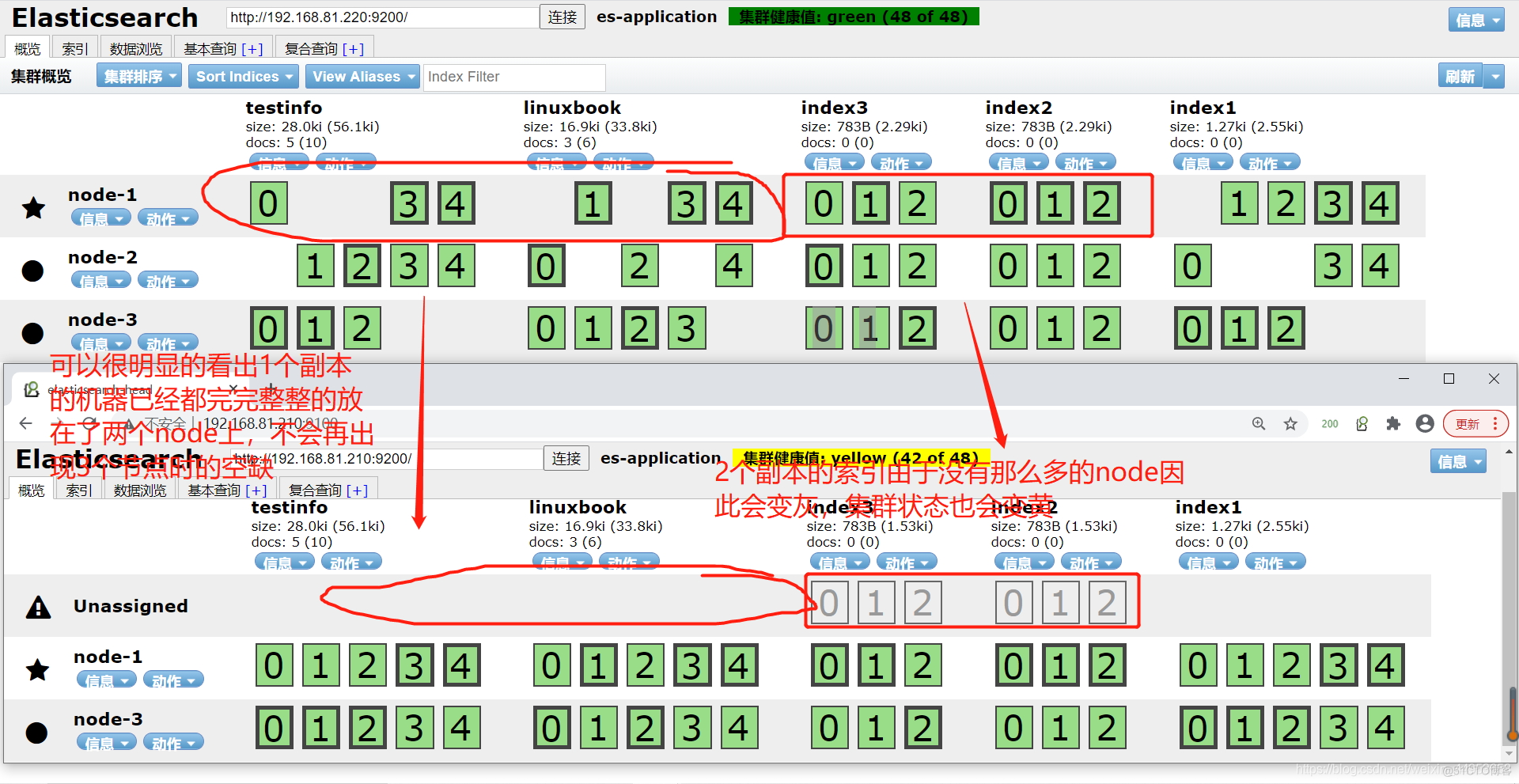
[root@node-2 ~]# systemctl stop elasticsearch停掉一个node后,可以看到node2已经不会显示在集群了,虽然node2挂掉了,但是node1和node3依然可以组成一份完整的数据,比如在node1上形成了主分片,node之间会进行数据同步,稍等会后node1和node3上的主分片和副本分片会再次形成,至于index2、index3上由于是2个副本分片,node节点没有那么多,因此导致变灰,集群状态变黄
4.elasticsearch集群监控
对于elasticsearch需要哪些监控哪些指标:
- 监控集群node节点的数量
- 监控集群状态值
4.1.为什么要监控node节点数量
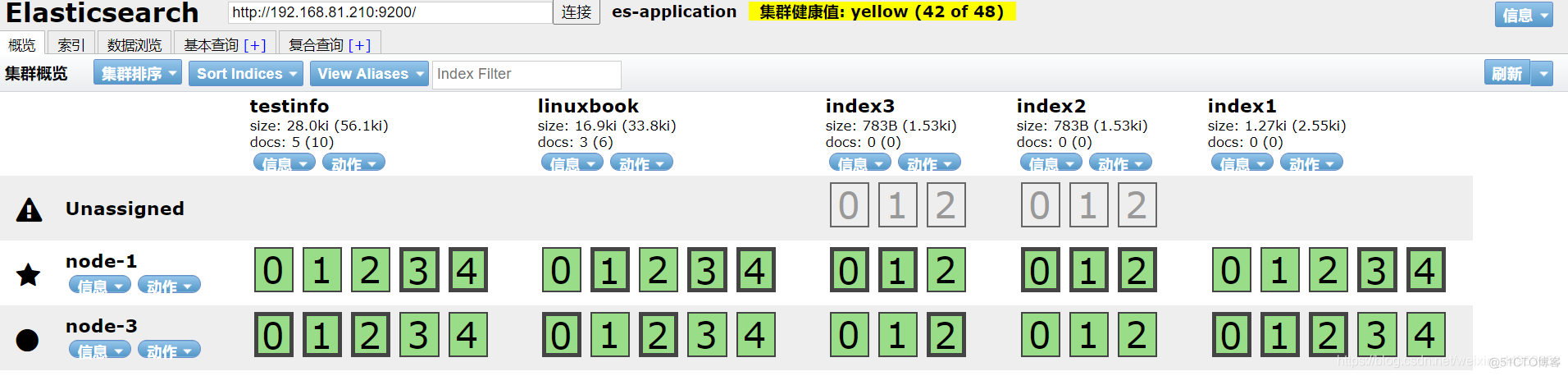
对于node节点的数量一定要监控起来,否则,当集群少了一台机器都不知道,有一种情况,集群挂了一个node,但是索引的副本分片没有收到影响,集群的状态值是green,这时运维压根不知道少了一台机器
对于下图,我们就能知道,我们有3台node节点,现在挂掉了一台,集群状态之所以是黄的是因为索引副本分片数量导致的,我们可以将索引的副本数量进行调整
我们将index3、index2的副本数量调整为1
[root@elasticsearch ~]# curl -XPUT 'http://localhost:9200/index3/_settings?pretty' -H 'Content-Type: application/json' -d ' > { > "settings" : { > "number_of_replicas" : 1 > } > }' { "acknowledged" : true } [root@elasticsearch ~]# curl -XPUT 'http://localhost:9200/index2/_settings?pretty' -H 'Content-Type: application/json' -d ' { "settings" : { "number_of_replicas" : 1 } }' { "acknowledged" : true }调整之后,副本数已经满足了要求,但是我们的node其实是挂掉了一台,假如我的环境确实有3台主机,索引的副本分片也都是1的话,我们是感受不到集群中挂了一个node的,因此就需要监控node节点的数量
4.2.node节点数量监控方式
可以自定义监控项,通过elasticsearch的交互式拿到节点的数量,在通过触发器比较这个值,当小于集群节点数时就报警
1.编写监测node节点数量的脚本 [root@elasticsearch ~]# vim es_node_count.sh #!/bin/bash node_cz_count=`curl -XGET 'http://localhost:9200/_cat/nodes?human&pretty' -s /dev/null | wc -l` node_zs=3 if [ $node_cz_count -lt $node_zs ];then echo "$node_cz_count" fi 2.执行脚本 [root@elasticsearch ~]# sh es_node_count.sh 2脚本执行的结果输出是2,但是咱们node节点是3个,这时候就要报警了,可以把这个脚本做成自定义监控项,最后添加一个触发器,当最新值不是3的时候就告警
4.3.为甚要监控集群状态
监控集群状态可以第一时间知道elasticsearch集群有问题,具体那个索引有问题
5.索引副本数为零的集群状态
将index2的索引副本数调整为0
[root@node-2 ~]# curl -XPUT 'http://localhost:9200/index2/_settings?pretty' -H 'Content-Type: application/json' -d ' { "settings" : { "number_of_replicas" : 0 } }'0副本也就是没有副本,当索引的副本数为零,集群的样子会是下图所示
只有主分片没有副本分片,且主分片都是随机分散存储在不同的node节点
之前提到过yellow状态,而这里没有副本了,为什么集群状态不是黄色呢,因为我们把副本数量设置成了0 ,而不是副本无法再node上创建,因此不会爆黄
6.模拟集群red状态
red状态表示集群中有索引产生了严重的错误,也就是副本数量不满足,且索引分片丢失,数据不完整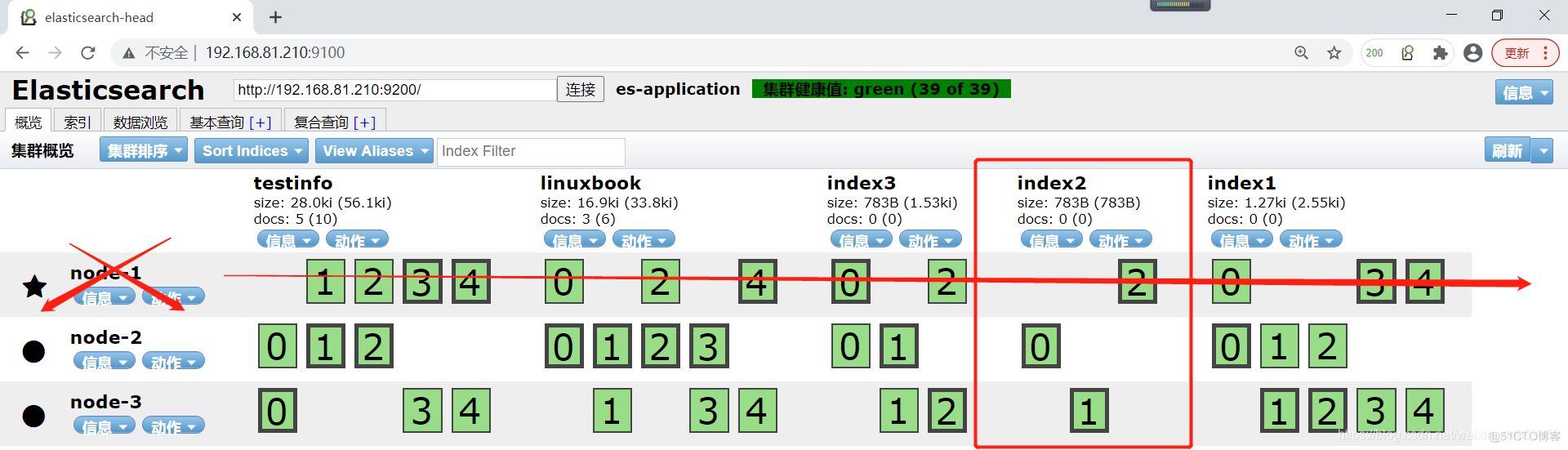
现在index2索引是没有副本分片的,每台node主机都有一个分片,当我们停掉node1后,index2索引分片就是不完整的了,从而集群的状态就会变成红色
停止noe1
[root@elasticsearch ~]# systemctl stop elasticsearch接着观察集群的状态
index2由于分片数量是3个,且node节点也是3个,3个分片都分散在不同的node上,当node1停掉后,分片也会受到影响,从而影响数据的完整性,分片一旦丢失,集群状态就会变成红色
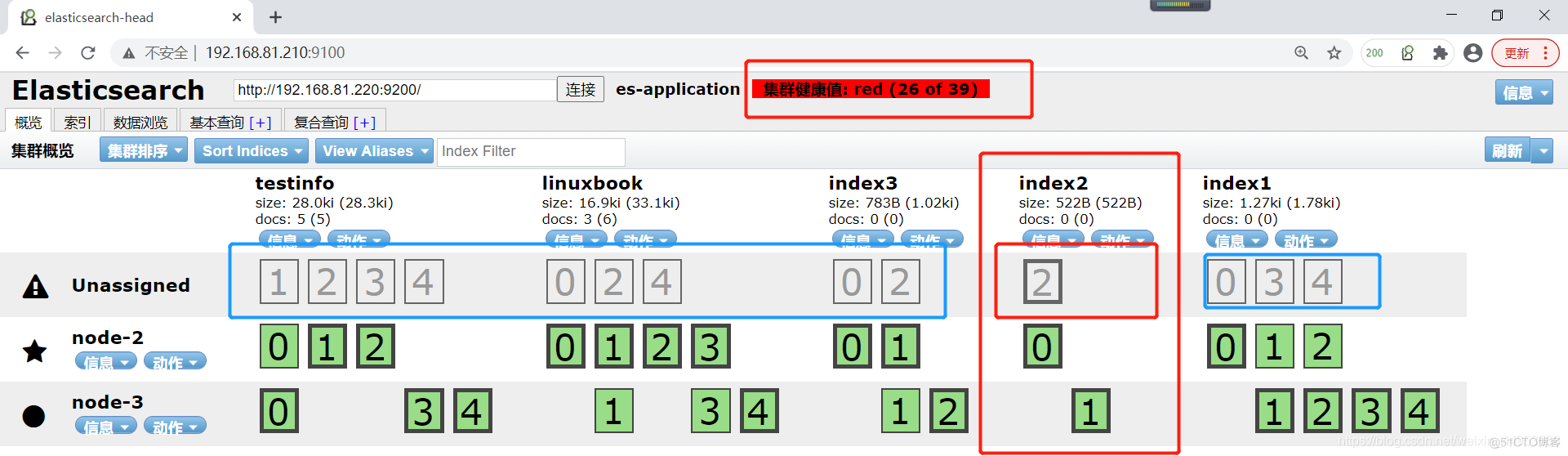
其他索引变灰是因为正在进行数据同步,在同步过程中受影响的分片首先变成紫色,变成紫色的是在决定要给那个node进行数据同步,选择好后会变成黄色,黄色代表正在同步数据,当数据同步完,其他索引又会变成绿色,只有有问题的index2索引一直会处于灰色
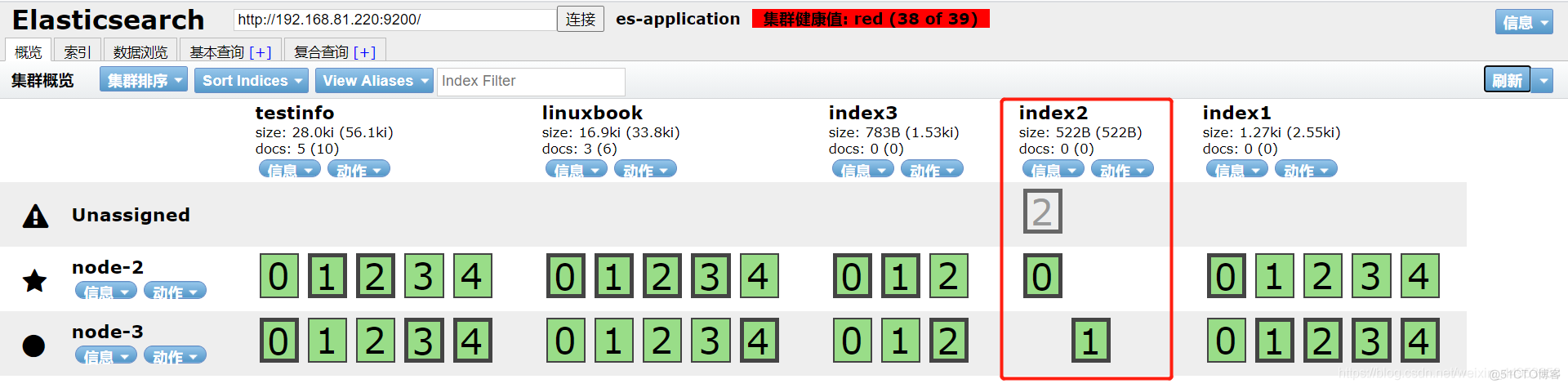
7.集群状态变为red是否会影响集群的使用
集群状态变为red后,只会影响有问题的索引库,没有发生问题的索引不会影响其正常使用
当前集群的状态就是red状态
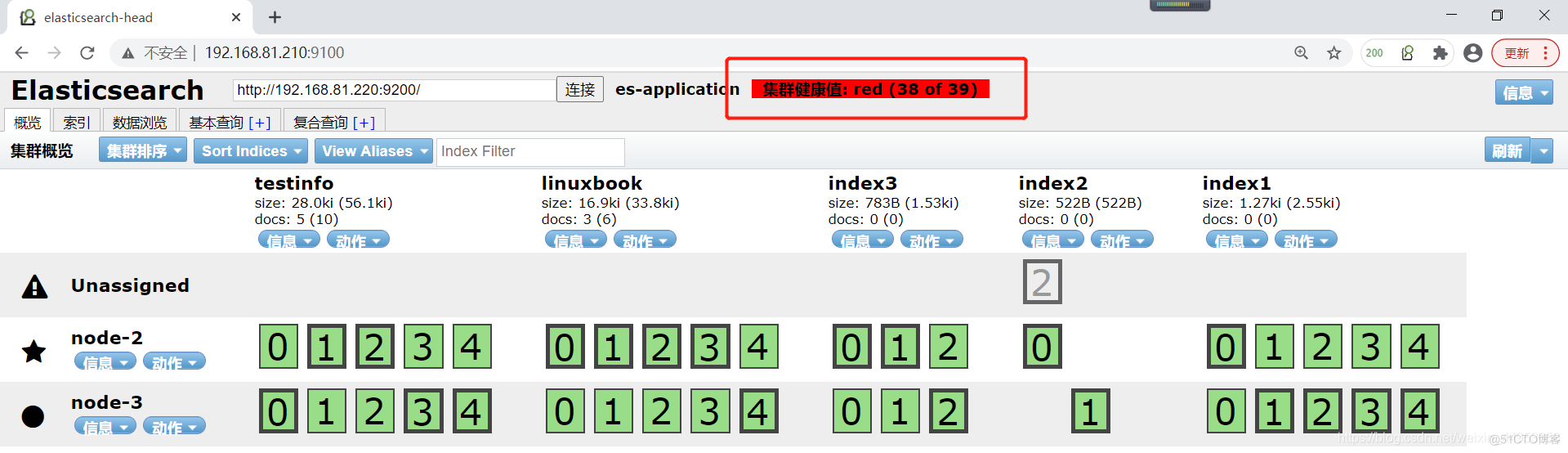
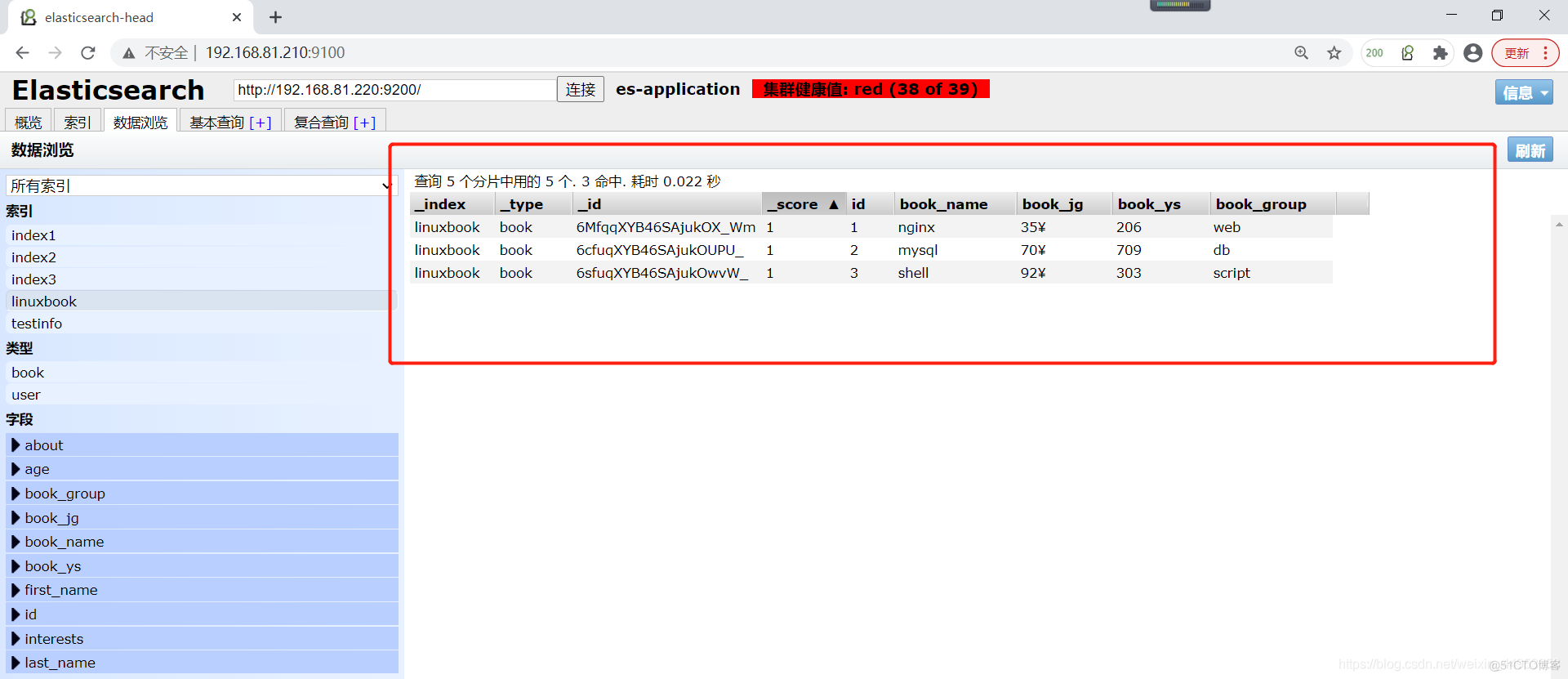
我们验证一下,查询一个linuxbook索引库的数据验证是否能正常使用
可以看到是可以正常查询数据的,不会影响业务
8.关于elasticsearch集群优化
elasticsearch集群优化
elasticsearch集群没啥可优化的,因为本身已经很强了,即使集群中某个索引产生了问题,也不会影响其他索引库的正常使用。
elasticsearch优化方面,其实最主要就是增加node节点、扩大物理机内存,elasticsearch主要就是吃内存,java项目都特别能费内存,内存优化建议最大30G,30G以上不会再提升系统性能。
【文章原创作者:华为云代理 http://www.558idc.com/hw.html处的文章,转载请说明出处】