首先我们应该知道np.sum是用C语言写的矢量计算,应用场景为规模较大的numpy数组求和。本文要说的就是numpy.sum是不是对规模较小的numpy数组求和也同样会有不错的性能? 代码: import n
首先我们应该知道np.sum是用C语言写的矢量计算,应用场景为规模较大的numpy数组求和。本文要说的就是numpy.sum是不是对规模较小的numpy数组求和也同样会有不错的性能?
代码:
import numpy as npimport time
data_0 = []
data_1 = []
for _ in range(1000000):
tmp = np.random.randint(100, size=(6,))
data_0.append(tmp)
data_1.append(tmp.tolist())
a_time = time.time()
for d in data_0:
x=np.sum(d)
b_time = time.time()
print(b_time-a_time)
a_time = time.time()
for a,b,c,d,e,f in data_1:
x=a+b+c+d+e+f
b_time = time.time()
print(b_time-a_time)
从上面的代码中我们可以知道,第一个运算是使用numpy.sum对长度为6的numpy数组求和;第二个运算是使用python原生的加和运算。
运算结果:
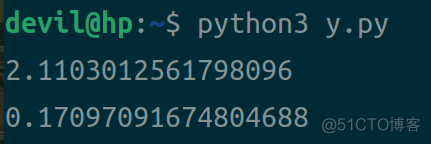
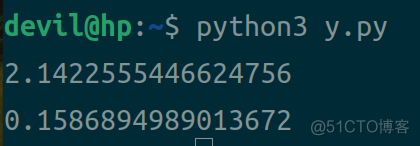
结果分析:
从上面的结果可以看到,在对小规模数组求和时,numpy.sum求和计算的性能是没有python原生计算性能高的,而且这个差距还很大,在上面的结果中相差了10多倍。由此我们可以知道,在对小规模数组求和时,使用python原生加和运算的性能要优于numpy.sum的。
========================================
numpy.sum的性能只有对较大规模数组求和才有很好体现,为此我们再加一个测试,对数组长度为10000的数组求和。
代码:
import numpy as npimport time
data_0 = []
data_1 = []
for _ in range(100000):
tmp = np.random.randint(100, size=(10000,))
data_0.append(tmp)
data_1.append(tmp.tolist())
a_time = time.time()
for d in data_0:
x=np.sum(d)
b_time = time.time()
print(b_time-a_time)
a_time = time.time()
for data in data_1:
s = 0
for d in data:
s += d
b_time = time.time()
print(b_time-a_time)
运行结果:
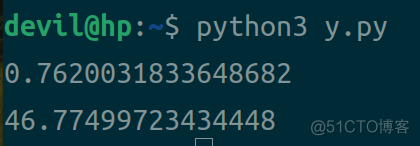
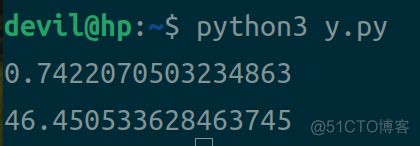
结果分析:
通过上面的测试,可以知道在对规模为10000的数组求和时,numpy.sum的性能是python原生的63倍;而在上面对长度为6的数组求和时,python原生的性能是numpy.sum的20倍。这个结果更加证明了numpy.sum只适合对大规模数组求和的情况,否则它的性能会原差于python原生。
=======================================