目录
基于物品的旅游产品推荐系统
surprise介绍
设计surprise时考虑到以下目的
常用类
项目实践
选择工具,导入相关模块
导入数据(重要)
构建训练集
模型训练和评估
训练模型
寻找相似度最高的用户集群
完整代码
预测推荐评分
增加预测分排序功能
附加知识
surprise可使用的模型
surprise如何优化参数(网格调参)
基于物品的surprise案例
总结
每文一语
基于物品的旅游产品推荐系统
摘要:近年来,旅游行业风生水起,随着社会经济的快速发展,国民消费水平不断的提高,人们将物质上的满足不断转型到精神上的需求。外出旅游成为每一个人的精神需求和物质消费倾向。2016年12月7日,国务院印发《“十三五”旅游业发展规划》,并指出要把握好时代的契机,优化旅游产业结构,创新旅游行业,保障旅游质量。
旅游行业的多元化发展和设计,不仅给相关部门带来了管理难度,也给消费者增加了选择的难度,旅游产品过多,不知道如何选择?产品质量如何?用户体验如何?大众评价又如何?这些都已经成为游客出行考虑的问题,前期做大量的旅游攻略,不仅浪费时间,而且容易造成审美疲劳,导致厌倦,最终造成消费不佳,消费动力不足,间接地影响到国民旅游的良性发展。
CF算法分为两大类,一类为基于memory的(Memory-based),另一类为基于Model的(Model-based),User-based和Item-based算法均属于Memory-based类型。推荐系统应用数据分析技术,找出用户最可能喜欢的东西推荐给用户,现在很多电子商务网站都有这个应用。目前用的比较多、比较成熟的推荐算法是协同过滤(Collaborative Filtering,简称CF)推荐算法,CF的基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
User-based的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
1. 数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
2. 算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
由于本研究数据量稍大,用户较多,所以本文通过基于物品的协同过滤推荐算法,针对用户进行个性化推荐和精准服务,达到游客和旅游部门之间的有效融合,对游客进行推荐服务,提高消费质量和消费趋势,加快相关部门的产业升级。
基于物品的协同过滤推荐,要找出与自己喜欢的物品相似的物品来推荐。基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。例如:可以知道物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。
Item-based算法首选计算物品之间的相似度,计算相似度的方法有以下几种:
1. 基于余弦(Cosine-based)的相似度计算,通过计算两个向量之间的夹角余弦值来计算物品之间的相似性,其中分子为两个向量的内积,即两个向量相同位置的数字相乘。公式如下:
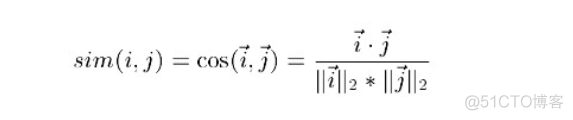
2. 基于关联(Correlation-based)的相似度计算,计算两个向量之间的Pearson-r关联度,公式如下:
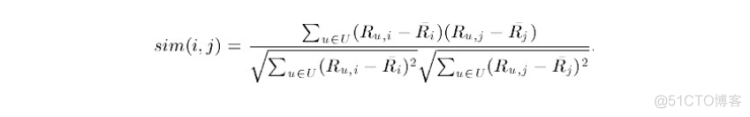
3. 调整的余弦(Adjusted Cosine)相似度计算,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:
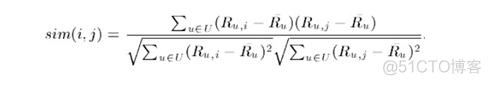
根据之前算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法:
1. 加权求和。
用过对用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分,公式如下:

了解过算法原理之后,我们就开始使用Python进行编写代码
需要简单易懂的项目代码请下载:
旅游消费数据集——包含用户id,用户评分、产品类别、产品名称等指标,可以作为推荐系统的数据集案例-数据集文档类资源-CSDN下载
机器学习-推荐系统(基于物品).ipynb-机器学习文档类资源-CSDN下载
机器学习-推荐系统(基于用户).ipynb-机器学习文档类资源-CSDN下载
上面介绍的是基于协同过滤的推荐原理的实现方法,因为这样的实现虽然简单,但是较多繁琐,在编写Python代码的时候,由于我们知道,Python是一个神器的工具,它的优势就在于调用第三方库,那么推荐系统有没有这样的呢?答案是有!!
surprise介绍
- Surprise是一个基于Python scikit构建和分析推荐系统。
- Surprise(Simple Python Recommendation System Engine)是一款推荐系统库,是scikit系列中的一个。
- 简单易用,同时支持多种推荐算法:基础算法、基于近邻方法(协同过滤)、矩阵分解等(SVD, PMF, SVD++, NMF)
设计surprise时考虑到以下目的
- 让用户完美控制他们的实验。为此,特别强调文档,试图通过指出算法的每个细节尽可能清晰和准确。
- 减轻数据集处理的痛苦。用户可以使用内置数据集(Movielens, Jester)和他们自己的自定义数据集。
- 提供各种即用型预测算法, 例如:基线算法, 邻域方法,基于矩阵因子分解( SVD, PMF, SVD ++,NMF)等等。此外, 内置了各种相似性度量(余弦,MSD,皮尔逊…)。可以轻松实现新的算法思路
- 提供评估, 分析和比较算法性能的工具。使用强大的CV迭代器(受scikit-learn优秀工具启发)以及对一组参数的详尽搜索,可以非常轻松地运行交叉验证程序 。
常用类


项目实践
选择工具,导入相关模块
import warningswarnings.filterwarnings("ignore")
from surprise import SVD,KNNBaseline,Reader,Dataset
from surprise.model_selection import cross_validate,train_test_split
import pandas as pd
import numpy as np
导入数据(重要)
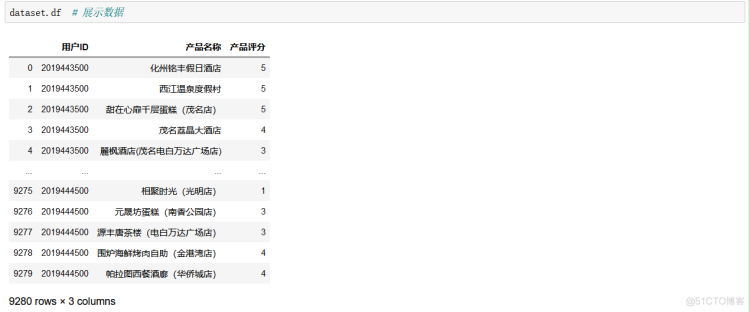
alldata = pd.read_excel("data.xlsx")data = alldata[["用户ID","产品名称","产品评分"]]
reader = Reader(line_format="user item rating")
dataset = Dataset.load_from_df(data,reader=reader)
这里我们将其保存为一个csv文件,因为我们只需要这几列数据,用于我们的推荐系统的实现,而在surprise模块中,读取数据就是一个需要谨慎考虑的东西。
reader = Reader(line_format='user item rating')dataset = Dataset.load_from_df(data,reader=reader)
使用surprise库下面的Reader函数进行读取,注意里面是文件的路口,由于我将其放在了当前路径下,所以只需要填写名称。
例如:
reader = Reader(line_format="user item rating", sep=',', skip_lines=1)对于这个 Reader() 类,主要的功能是设置一个读取器。从 Reader 的使用也可以看出来,要求的输入是每行的格式,每行的分隔符,要忽略的行数。
从这个类实例时的输入上,我们可以判断出来,这个 Reader() 类的作用是构造一个读取器对象 reader,这个读取器 reader 包含了一些如何去读数据的属性。比如 reader 知道每行的数据是按照 “user item rating” 来分布的,知道每行数据由符号 "," 分割开,知道第一行的数据应该被跳过。
所以我们在构建了这个 reader 以后,就可以将它传给 Dataset() 类,来辅助我们从数据集中,按照我们想要的格式读取出来数据内容。
数据载入,由 Reader 和 Dataset 两个类来提供功能,具体的思路是由 Reader() 提供读取数据的格式,然后 Dataset 按照 Reader 的设置来完成对数据的载入。
这个时候就返回了我们surprise系统的数据格式,我们就可以按照这个开源的包进行我们的推荐了。
构建训练集
# 构建训练集trainset = dataset.build_full_trainset()
但是这个返回的是一个surprise的:
<surprise.trainset.Trainset at 0x2b38e9098c8>
我们需要转换一下(dataframe格式),便于我们看清楚数据的样式:
pd.DataFrame(list(trainset.all_ratings()))
极大地提高了我们的编写效率和可读性!
user_based_sim_option = {'name': 'pearson_baseline', 'user_based': True}
# item-based
item_based_sim_option = {'name': 'pearson_baseline', 'user_based': False}
ucf_model = KNNBaseline(k=10, sim_options=user_based_sim_option)
icf_model = KNNBaseline(k=10, sim_options=item_based_sim_option)
模型训练和评估
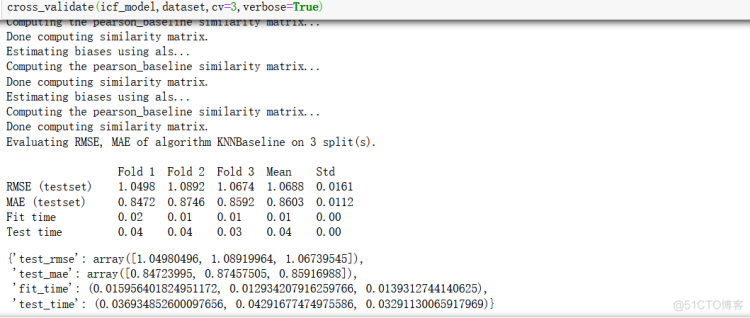
cross_validate(ucf_model,dataset,cv=3,verbose=True)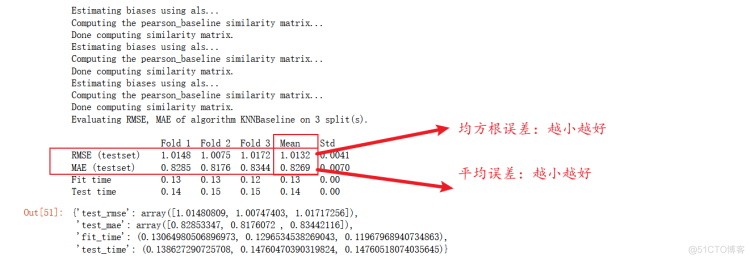
注:平均绝对误差
参数说明:第一个是选用的模型(基于用户还是基于物品),数据集,几折交叉,是否展示模型评估效果。
训练模型
ucf_model.fit(trainset)寻找相似度最高的用户集群
我们也可以使用surprise里面的KNN,寻找和你最相似的用户:
# user-baseduser_based_sim_option = {'name': 'pearson', 'user_based': True}
# 获取训练集,这里取数据集全部数据
trainset = dataset.build_full_trainset()
# 考虑基线评级的协同过滤算法
algo = KNNBaseline(sim_option = user_based_sim_option)
# 拟合训练集
algo.fit(trainset)
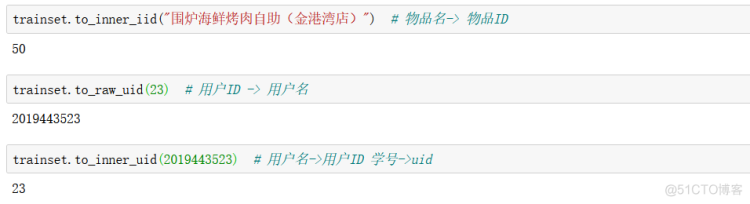
# 将原始id转换为内部id
inner_id = algo.trainset.to_inner_uid(2019443818)
# 使用get_neighbors方法得到10个最相似的用户
neighbors = algo.get_neighbors(inner_id, k=10) # 得到相似用户的内部索引编号
neighbors_uid = ( algo.trainset.to_raw_uid(x) for x in neighbors ) # 得到相似用户的真实编号
print(list(neighbors_uid))
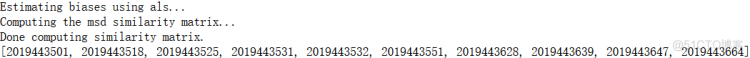
完整代码
最后我们将其编写为函数,方便我们调用
def get_similar_users_recommendations(uid, dataset=dataset,n=10):# 获取训练集,这里取数据集全部数据
trainset = dataset.build_full_trainset()
# 考虑基线评级的协同过滤算法(使用基于用户的算法)
algo = KNNBaseline(sim_option = user_based_sim_option)
# 拟合训练集
algo.fit(trainset)
# 将原始id转换为内部id
try:
inner_id = algo.trainset.to_inner_uid(uid)
except:
return algo,set()
# 使用get_neighbors方法得到10个最相似的用户
neighbors = algo.get_neighbors(inner_id, k=10) # 得到相似用户的内部索引编号
neighbors_uid = ( algo.trainset.to_raw_uid(x) for x in neighbors ) # 得到相似用户的真实编号
recommendations = set()
#把评分为5的产品加入推荐列表
for user in neighbors_uid:
if len(recommendations) > n:
break
item = data[(data['用户ID']==user)&(data['产品评分']==5)]["产品名称"]
for i in item.values:
recommendations.add(i)
print(f'\n推荐用户的ID是"{uid}":')
# print(recommendations)
for i, j in enumerate(list(recommendations)):
# print(i)
if i >= 10:
break
print(j)
return algo,recommendations
algo,recom = get_similar_users_recommendations(2019443818,dataset, 10)

为什么要推荐这些,首先是这些产品是基于用户的相似性得到的一个大的产品范围,然后我们再用surprise库进行训练得到10个推荐产品,这些产品我们是可以预测它的评分的。
预测推荐评分
for item in recom:algo.predict(2019443818,item,r_ui=5,verbose=True)

从上面我们得知,最好的一个推荐产品已经产生了,首先它是评分为5的产品,其次预测出的评分也是十分接近的!但是作为一个推荐系统,我们需要的是,我虽然很喜欢这个产品,但是第二次消费的时候,总不能总是推荐我上一次消费的产品吧,这样就容易让用户产生无趣感!
所以我们可以去给我们的推荐系统增加一个筛选功能,当用户进入推荐系统,可以自定义选择是否要延续第一次的消费产品,如果不需要,那么就需要将这类产品在推荐目录下去除!

这个时候,我们又发现一个产品,推荐分和本身相似用户的评分就不错的!
此外我们还可以对预测评分进行一个排序,便于用户在选择的时候,不仅可以参考名称也可以参考预测评分!
for group_label,group_df in alldata.groupby("产品分类"):data = group_df[["用户ID","产品名称","产品评分"]]
reader = Reader(line_format="user item rating")
dataset = Dataset.load_from_df(data,reader=reader)
print(group_label.center(50,'#'))
get_similar_users_recommendations(2019443818,dataset, 10)

增加预测分排序功能
d={}users=[]
ranks=[]
ests=[]
items=[]
for item in recom:
user=algo.predict(2019443818,item,r_ui=5,verbose=True).uid
rank=algo.predict(2019443818,item,r_ui=5,verbose=True).r_ui
items.append(item)
est=algo.predict(2019443818,item,r_ui=5,verbose=True).est
users.append(user)
ranks.append(rank)
ests.append(est)
d={"用户ID":users,"推荐产品名称":items,"产品评分":ranks,"预测分":ests}
df=pd.DataFrame(d)
df.sort_values(by=['预测分'],ascending=False)
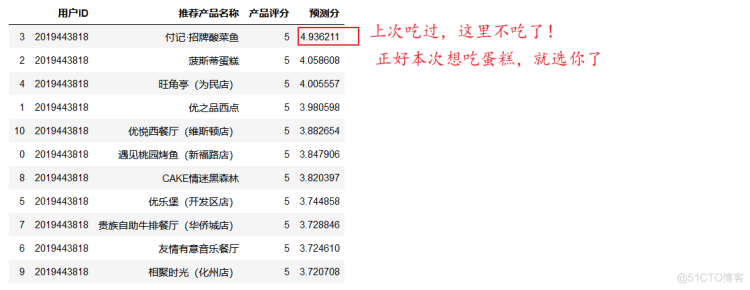
基于surprise系统进行推荐,采用基于用户的算法计算用户相似度,寻找最相似的10个用户集群,通过他们的产品评分得到一个最佳的产品推荐数据集,利用KNN进行预测产品推荐分,然后在按照预测分进行排序,最后我们就可以按照其推荐结果选择最佳的产品进行消费了!!
可能细心的伙伴会发现,为什么没有景区的推荐,因为在原始的数据里面就没有对景区发生行为,所以就没有推荐,这就是surprise模块的特点,代码量也很少,但是就可以完成推荐系统的实现!
当然利用surprise做推荐系统比原生算法代码进行推荐的好处是,surprise有多种算法的选择,其次还可以进行优化参数来达到我们模型的最佳效果。
附加知识
surprise可使用的模型
music_data=dataset### 使用NormalPredictor算法,基于训练集的评分矩阵来预测空白评分的。
from surprise.model_selection import cross_validate,train_test_split
algo = NormalPredictor()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用BaselineOnly
from surprise import BaselineOnly
algo = BaselineOnly()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用基础版协同过滤
from surprise import KNNBasic
algo = KNNBasic()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用均值协同过滤
from surprise import KNNWithMeans
algo = KNNWithMeans()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用协同过滤baseline
from surprise import KNNBaseline
algo = KNNBaseline()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用SVD
from surprise import SVD
algo = SVD()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用SVD++
from surprise import SVDpp
algo = SVDpp()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)
### 使用NMF
from surprise import NMF
algo = NMF()
perf = cross_validate(algo, music_data, measures=['RMSE', 'MAE'],verbose=True)
print(perf)

surprise如何优化参数(网格调参)
类似于我们的机器学习,sklearn中的网格搜索(暴力搜索),寻找最佳参数!
# 度量准则:pearson距离,协同过滤:基于itemsim_options = {'name': 'pearson_baseline', 'user_based': False}
在寻找最佳参数的时候,我们需要定义最佳参数的范围应该是属于哪一个范围,其次在利用网格搜索进行最佳参数的搜索,那么涉及到你应该查询文献知识或者去官网查看最佳参数的范围!
from surprise.model_selection import GridSearchCV# 定义好需要优选的参数网格
param_grid = {'n_epochs': np.arange(4,10,1), 'lr_all': np.arange(0.002,0.01,0.001),
'reg_all': np.arange(0.4,0.8,0.1)}
# 使用网格搜索交叉验证
grid_search = GridSearchCV(SVD, param_grid, measures=['RMSE', 'MAE'])
# 在数据集上找到最好的参数
grid_search.fit(dataset)
# 输出调优的参数组
# 输出最好的RMSE结果
# 输出最好的RMSE结果
print(grid_search.best_score['rmse'])
# 输出对应最好的RMSE结果的参数
print(grid_search.best_params['rmse'])
# 输出最好的MAE结果
print(grid_search.best_score['mae'])
# 输出对应最好的MAE结果的参数
print(grid_search.best_params['mae'])

基于物品的surprise案例
根据一个item取回相似度最高的item,主要是用到algo.get_neighbors()这个函数
import ioimport os
from surprise import Dataset
from surprise import KNNBaseline
def read_item_names():
"""
获取电影名到电影id 和 电影id到电影名的映射
构建映射字典
:return:
"""
filename = (os.path.expanduser('~/.surprise_data/ml-100k/ml-100k/u.item'))
rid_to_name = {}
name_to_rid = {}
with io.open(filename, 'r', encoding='ISO-8859-1') as f:
for line in f:
line = line.split('|')
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
# 首先,用算法计算相互间的相似度
data = Dataset.load_builtin('ml-100k')
# 使用协同过滤必须有这行,将我们的算法运用于整个数据集,而不进行交叉验证,构建了新的矩阵
trainset = data.build_full_trainset()
# 度量准则:pearson距离,协同过滤:基于item
sim_options = {'name': 'pearson_baseline', 'user_based': False}
algo = KNNBaseline(sim_options=sim_options)
algo.fit(trainset=trainset)
rid_to_name, name_to_rid = read_item_names()
# 拿出来Toy Story这部电影对应的item id
toy_story_raw_id = name_to_rid['Toy Story (1995)']
# 转换为内部id
toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id)
# 根据内部id找到最近的10个邻居
toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, k=10)
# 将10个邻居的内部id转换为item id也就是raw
toy_story_neighbors_rids = (algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors)
# 将10个邻居的item id 转为name
toy_story_neighbors_names = (rid_to_name[raw_id] for raw_id in toy_story_neighbors_rids)
# 打印结果
print('----------The 10 nearest neighbors of Toy Story---------------')
for movie in toy_story_neighbors_names:
print(movie)
总结
在使用surprise模块进行推荐系统的实现的时候,大致的思路就是,导入数据,转换数据,选择模型,至于如何选择模型,在初期的时候我们利用多种模型进行测试,其次确定好模型之后,我们需要对参数进行调优,如何选择参数,我们需要继续网格搜索,然后确定好最佳的参数之后,需要确定我们是基于物品还是基于用户的推荐,一些相似度度量应该选择那些,最终我们通过评估模型来验证我们的数据集,然后进行推荐!
每文一语
人生有情泪沾衣,江水江花岂终极。