源码角度了解ConcurrentHashMap
ConcurrentHashMap大家都知道,它的数据结构前期是链表后期是红黑树,我们通过节点类型是Node节点和TreeNode节点可以知道它目前的结构是链表还是红黑树,ConcurrentHashMap为什么使用红黑树呢?说白了,当元素变多的时候,红黑树能有更好的查询和更新速度,还能解决Hash冲突的问题
ConcurrentHashMap是使用CAS和synchronized来实现线程安全的,从以下的源码中我们就能了解到。
ConcurrentHashMap的结构如下:

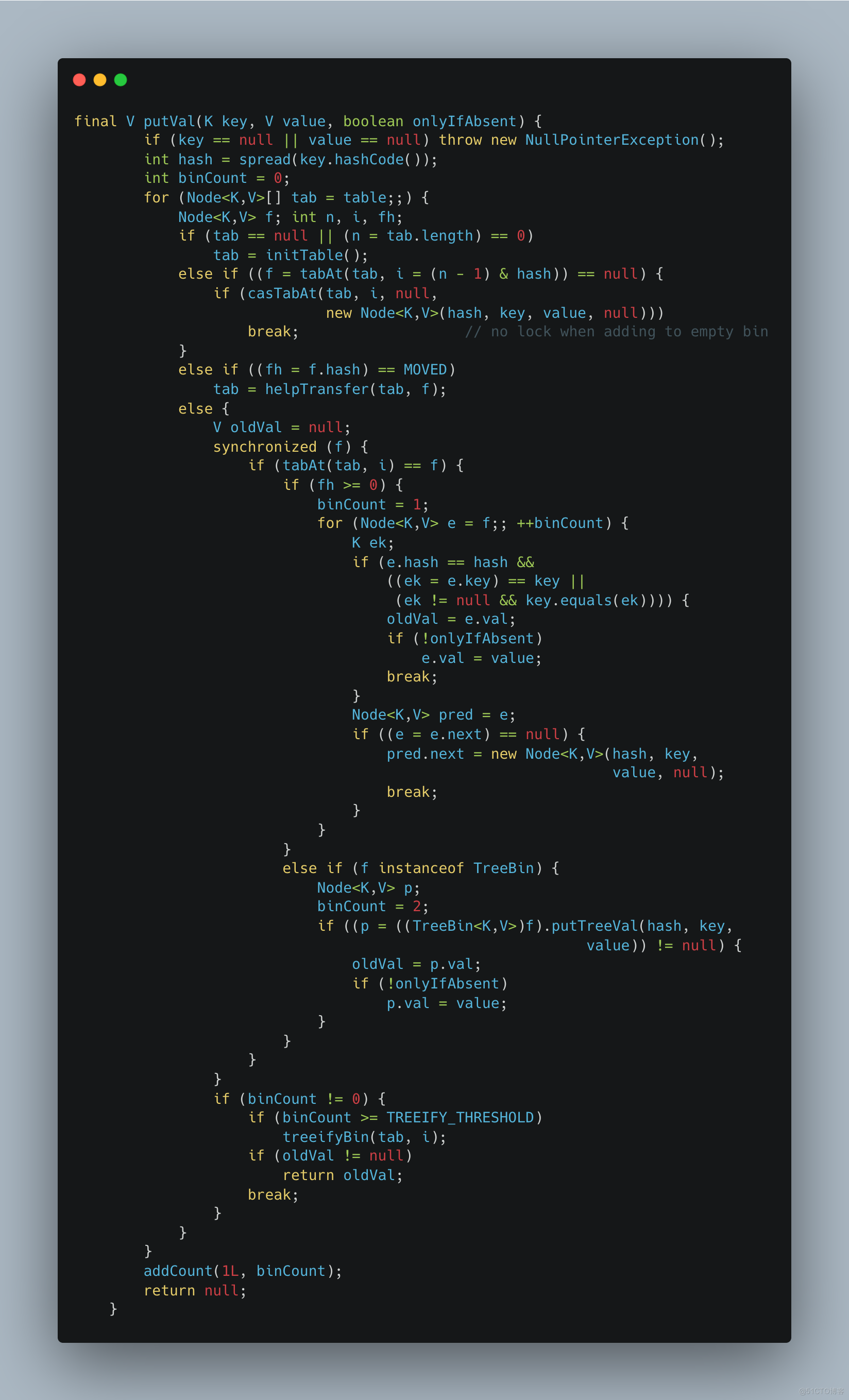
put()方法
initTable()方法初始化数组
初始化ConcurrentHashMap,使用sizeCtl记录大小
sizeCtl为-1表示ConcurrentHashMap正在初始化
sizeCtl小于-1表示正在扩容,-n表示有n-1个线程正在扩容
sizeCtl为正数,如果tab=null表示未初始化之前的初始容量,如果已经初始化,sizeCtl存储的是下一次扩容的阈值0.75n
private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } break; } } return tab; }值得注意的是这段有两行(tab = table) == null || tab.length == 0校验数组是否为空,这里是单例模式双重检查锁DCL(double-checked locking)的体现
treeifyBin()扩容或转为红黑树
在给定索引处替换 bin 中的所有链接节点转为红黑树,如果数组太小,调整数组大小扩容。
private final void treeifyBin(Node<K,V>[] tab, int index) { Node<K,V> b; int n, sc; if (tab != null) { if ((n = tab.length) < MIN_TREEIFY_CAPACITY) tryPresize(n << 1); else if ((b = tabAt(tab, index)) != null && b.hash >= 0) { synchronized (b) { if (tabAt(tab, index) == b) { TreeNode<K,V> hd = null, tl = null; for (Node<K,V> e = b; e != null; e = e.next) { TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null); if ((p.prev = tl) == null) hd = p; else tl.next = p; tl = p; } setTabAt(tab, index, new TreeBin<K,V>(hd)); } } } } }tryPresize()方法
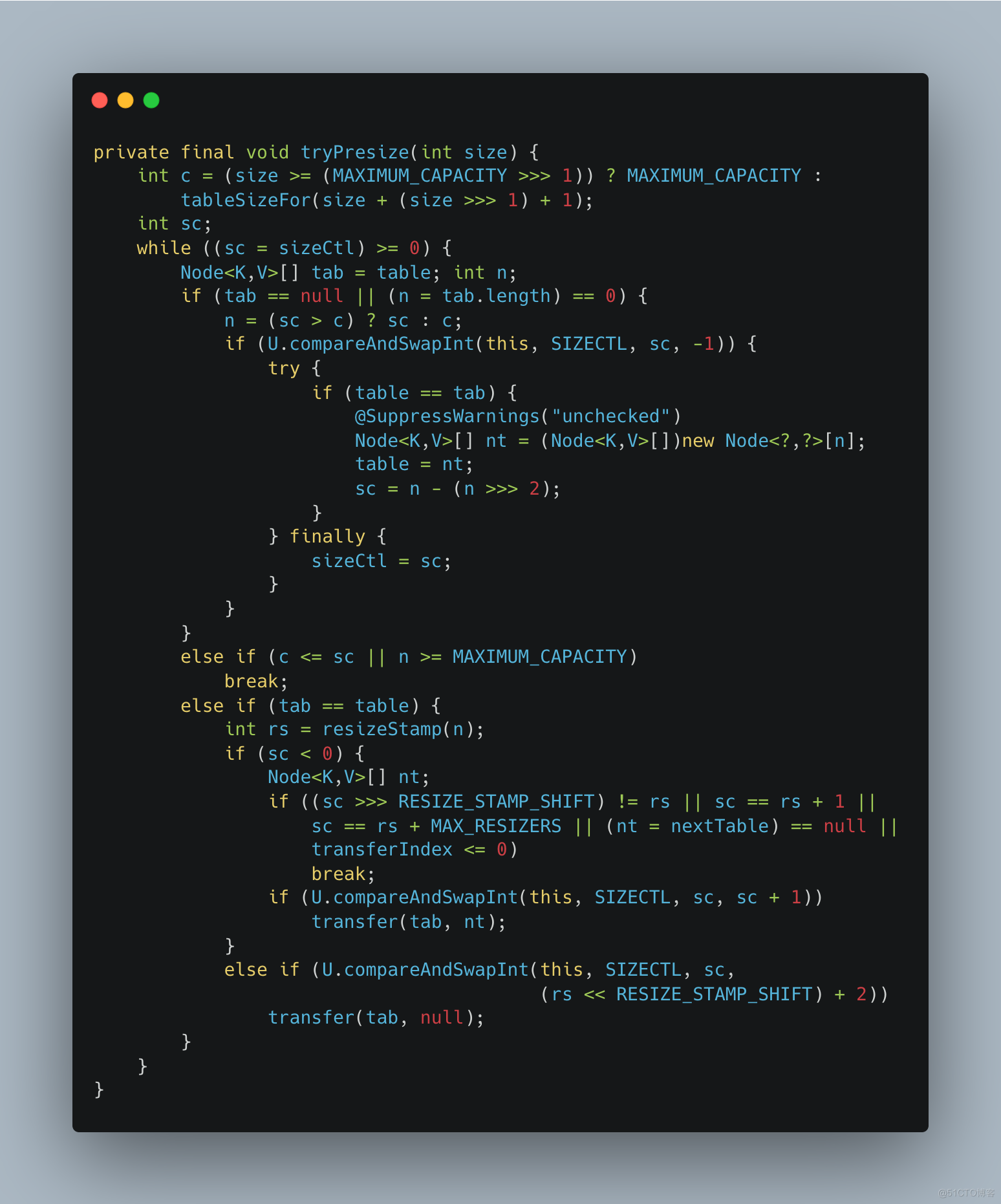
对扩容数组的长度进行判断,看是否达到最大容量,如果达到最大容量设置成最大容量,如果没有就调用tableSizeFor()方法将扩容大小转换为2的n次幂
如果tab为空,进行初始化数组
如果扩容长度小于阈值或者数据长度大于等于最大容量了,表示扩容完成了
以上都不满足就进行扩容,如果sc小于0表示正在扩容,那么就进行帮助扩容,否则就调用transfer()方法进行扩容
ransfer()方法中
stride表示了一个线程扩容的长度,步长和CPU和核数有关,最小步长为16位,每个线程扩容这一段,
变量transferIndex记录扩容的进度,初始值是n,当一个线程扩容完后减去stride的值,到0 的时候表示扩容完成,由于transferIndex可能被多个线程操作,所有使用CAS方法compareAndSwapInt()改变transferIndex的值。
在扩容过程中,ForwardingNode连接了两个数组,如果需要访问key对应的value的话,会访问ForwardingNode来获取数据。
setTabAt()方法就是把构造的链表ln和hn放入新的数组中,同时把旧的数组的i位置添加ForwardingNode节点,表示这个位置的元素已经转移
总结
ConcurrentHashMap是面试中常问的知识点,它的数据结构和扩容机制还是比较复杂的,这篇文章基于put()方法进行分析,了解它是如何进行扩容,初始长度是16,链表长度大于等于8并且数组长度达到64由链表转为红黑树。
❤️ 感谢大家
如果你觉得这篇内容对你挺有有帮助的话: