第二十四章 shell 中色彩处理和 awk 使用技巧
(上课时间2021-07-22,笔记整理时间2021-07-29)
本节所讲内容:
24.1 shell 中的色彩处理
24.2 awk 基本应用
24.3 awk 高级应用
24.1 Shell 中的色彩处理
shell 脚本中 echo 显示内容带颜色显示,echo 显示带颜色,需要使用参数-e
格式 1: echo -e “\033[背景颜色;文字颜色 m 要输出的字符 \033[0m”
格式 2:echo -e “\e[背景颜色;文字颜色 m 要输出的字符\e[0m”
例:绿底蓝字
如图:

注:其中 42 的位置代表底色,34 的位置代表的是字的颜色,0m 是关闭属性
1、字背景颜色和文字颜色之间是英文的分号";"
2、文字颜色后面有个 m
3、字符串前后可以没有空格,如果有的话,输出也是同样有空格
4、echo 显示带颜色,需要使用参数-e ,-e 允许对下面列出的加反斜线转义的字符进行解释。
控制选项:
\033[0m 关闭所有属性
\033[1m 设置高亮度,加粗
\033[5m 闪烁
[root@CentOS83 ~]# echo -e "\e[42;34m hello world\e[5m" #执行后,发现后期所有输出都闪烁状态,如何关闭? [root@CentOS83 ~]# echo -e " \e[0m" #可以使用\e[0m 关闭所有属性 [root@CentOS83 ~]# echo -e " \033[0m" #可以使用\033[0m 关闭所有属性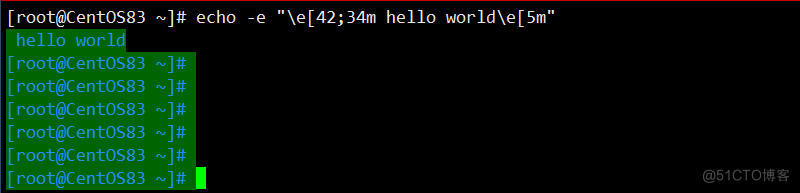
shell 色彩应用实战:
[root@CentOS83 ~]# echo -e "\033[31m 开始部署apache环境 \033[0m" \ && yum -y install httpd &> /dev/null \ && systemctl start httpd \ && echo -e "\033[42m apache启动成功 \033[0m" || echo -e "\033[41m apache启动失败!\033[0m"#安装服务,部署开始时输出红色字体。部署成功并启动服务后输出绿底 start 字样,失败则输出红底 error 字样。
24.2 awk 基本应用
grep 和 egrep:文本过滤的
sed:流编辑器,实现编辑的
awk:文本报告生成器,实现格式化文本输出
24.2.1 概念
AWK 是一种优良的文本处理工具,Linux 及 Unix 环境中现有的功能最强大的数据处理引擎之一。
这种编程及数据操作语言的最大功能取决于一个人所拥有的知识。awk 命名:Alfred Aho Peter (阿尔弗雷德·霍彼得)、Weinberger(温伯格)和 brian kernighan(布莱恩·柯林汉)三个人的姓的缩写。
awk---->gawk 即: gun awk
在 linux 上常用的是 gawk,awk 是 gawk 的链接文件
man gawk----》pattern scanning and processing language 模式扫描和处理语言。
任何 awk 语句都是由模式和动作组成,一个 awk 脚本可以有多个语句。模式决定动作语句的触发条件和触发时间。
模式:
正则表达式 : /root/ 匹配含有 root 的行 /*.root/
**关系表达式: < > && || + ***
匹配表达式: ~ !~
动作:
变量 命令 内置函数 流控制语句
它的语法结构如下:
awk [options] 'BEGIN{ print "start" } ‘pattern{ commands }’ END{ print "end" }' file
其中:BEGIN END 是 AWK 的关键字部,因此必须大写;这两个部分开始块和结束块是可选的

特殊模块:
BEGIN 语句设置计数和打印头部信息,在任何动作之前进行
END 语句输出统计结果,在完成动作之后执行
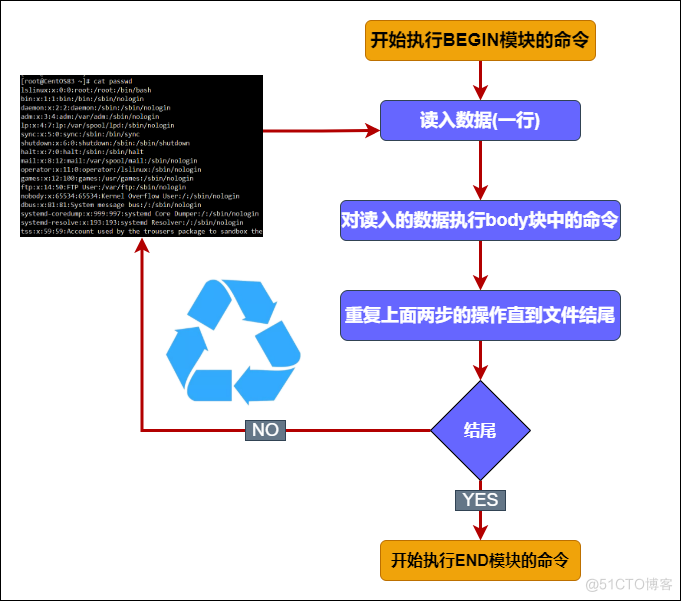
通过上面我们可以知道;AWK 它工作通过三个步骤
1、读:从文件、管道或标准输入中读入一行然后把它存放到内存中
2、执行:对每一行数据,根据 AWK 命令按顺序执行。默认情况是处理每一行数据,也可以指定模式
3、重复:一直重复上述两个过程直到文件结束
AWK 支持两种不同类型的变量:内建变量,自定义变量
awk 内置变量:
字符 定义 $n 当前记录的第 n 个字段,比如: $1 表示第一个字段,$2 表示第二个字段 $0 这个变量包含执行过程中当前行的文本内容 FILENAME 当前输入的文件名 FS 字段分隔符(默认是空格) NF 表示字段数,在执行过程中对应于当前的字段数,NF:列的个数 FNR 各文件分别计数的行号 NR 表示记录数,在执行过程中对应于当前的行号 , NR :行号 OFS 输出字段分隔符(默认值是一个空格) ORS 输出记录分隔符(默认值是一个换行符) RS 记录分隔符(默认是一个换行符)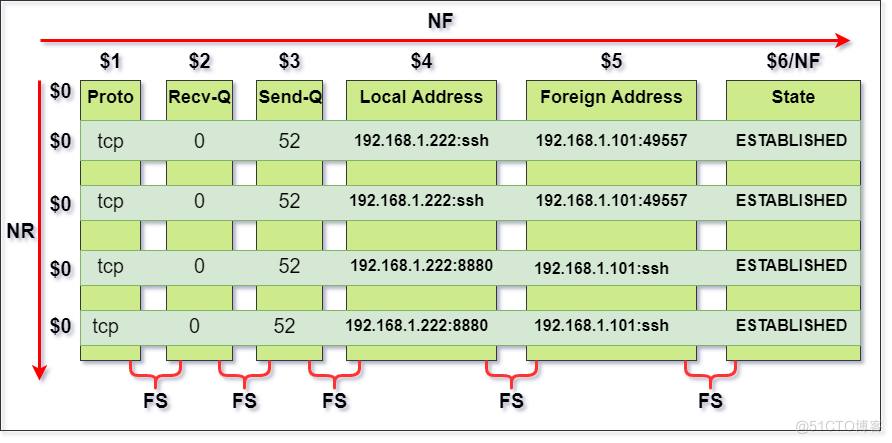
24.2.2 实例演示
常用的命令选项:
-F fs 指定分隔符
-v 赋值一个用户自定义变量
-f 指定脚本文件,从脚本中读取 awk 命令
(1)分隔符的使用
用法:-Ffs 其中 fs 是指定输入分隔符,fs 可以是字符串或正则表达式;分隔符默认是空格
常见写法:-F: -F, -F[Aa]
[root@CentOS83 ~]# echo "AA BB CC DD" | awk '{print $2}' [root@CentOS83 ~]# echo "AA BB CC DD" | awk '{print $2}' BB [root@CentOS83 ~]# echo "AA|BB|CC|DD" | awk -F "|" '{print $2}' BB [root@CentOS83 ~]# echo "AA,BB,CC,DD" | awk -F "," '{print $2}' BB [root@CentOS83 ~]# echo "AA,BB,CC,DD" | awk -F , '{print $2}' BB [root@CentOS83 ~]# awk -F: '{print $1}' /etc/passwd root bin daemon ………… [root@CentOS83 ~]# cut -d: -f1 /etc/passwd root bin daemon ………… [root@CentOS83 ~]# echo "86AxAbADXaAD53" | awk -F "[aA]" '{print $1}' 86 #指定多个分隔符 [root@CentOS83 ~]# echo "86AxAbADXaAD53" | awk 'BEGIN {FS="aA"} {print $2}' D53 #使用 FS 指定分隔符 [root@CentOS83 ~]# ifconfig ens33 | grep netmask inet 10.170.80.83 netmask 255.255.255.0 broadcast 10.170.80.255 [root@CentOS83 ~]# ifconfig ens33 | grep netmask | awk '{print $2}' 10.170.80.83 #过滤出本系统的 IP 地址(2)关系运算符的使用
[root@CentOS83 ~]# echo "5 6 7 9" > echo1.txt [root@CentOS83 ~]# awk '{print $1+10}' echo1.txt 15 [root@CentOS83 ~]# awk '{print $2+10}' echo1.txt 16 [root@CentOS83 ~]# echo "5 6 7 9" > echo1.txt [root@CentOS83 ~]# awk '{print $1+10}' echo1.txt 15 [root@CentOS83 ~]# awk '{print $2+10}' echo1.txt 16 [root@CentOS83 ~]# echo "one two three four" | awk '{print $4}' four [root@CentOS83 ~]# echo "one two three four" | awk '{print $NF}' four [root@CentOS83 ~]# echo "one two three four" | awk '{print $(NF-2)}' two ##打印倒数第3列 [root@CentOS83 ~]# echo "one two three four" | awk '{print $(NF/2-1)}' one打印出 passwd 文件中用户 UID 小于 10 的用户名和它登录使用的 shell
参数: $NF 最后一列
[root@CentOS83 ~]# awk -F: '$3<10{print $1 $NF}' /etc/passwd root/bin/bash bin/sbin/nologin ………… [root@CentOS83 ~]# awk -F: '$3<10{print $1 "<======>" $NF}' /etc/passwd root<======>/bin/bash #awk 格式化输出 bin<======>/sbin/nologin ………… [root@CentOS83 ~]# awk -F: '$3<10{print $1 "\t" $NF}' /etc/passwd root /bin/bash #在$1 和$NF 之间加一下\t tab bin /sbin/nologin …………注:awk 最外面使用了单引号'' ,里面都使用双引号“”
输出多个列时,可以加,分隔一下.
[root@CentOS83 ~]# awk -F: '$3<10{print $1,$NF}' /etc/passwd root /bin/bash bin /sbin/nologin …………打印出系统中 UID 大于 1000 且登录 shell 是/bin/bash 的用户
[root@CentOS83 ~]# awk -F: '$3>=1000 && $NF=="/bin/bash"{print $1 "\t" $NF}' /etc/passwd dior /bin/bash which /bin/bash …………(3)在脚本中的一些应用 例:统计当前内存的使用率
[root@CentOS83 ~]# vim user_cache.sh [root@CentOS83 ~]# cat user_cache.sh #!/bin/bash echoo "当前系统内存使用百分比为:" USEFREE=`free -m | grep -i mem | awk '{print $3/$2*100"%"}'` echo -e "内存使用百分比: \e[31m${USEFREE}\e[0m" [root@CentOS83 ~]# bash user_cache.sh user_cache.sh: line 2: echoo: command not found ÄÚ´æʹÓðٷֱȣº 37.407%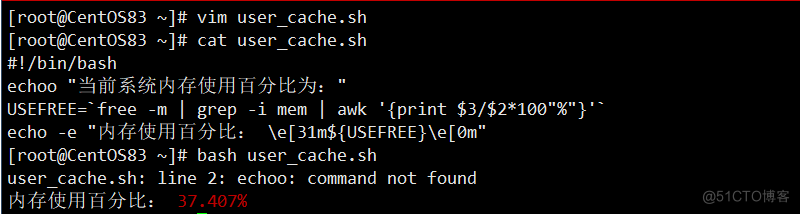
24.3 awk 高级应用
命令格式:awk [-F | -f | -v ] ‘BEGIN {} / / {command1;command2} END {}’ filename
参数 意义 -F 指定分隔符 -f 调用脚本 ‘{}’ 引用代码块 {…} 命令代码块,包含一条或多条命令 BEGIN 初始化代码块 {print A;print B} 多条命令使用分号分隔 END 结尾代码块在 awk 中,pattern 有以下几种:
empty 空模式,这个也是我们常用的
/regular expression/ 仅处理能够被这个模式匹配到的行
#打印以 dior 开头的行 [root@CentOS83 ~]# awk -F: '/^dior/{print $0}' /etc/passwd dior:x:1000:1000::/home/dior:/bin/bash3) 行范围匹配 startline,endline
#输出行号大于等于 5 且行号小于等于 10 的行 [root@CentOS83 ~]# awk -F: '(NR>=5&&NR<=10){print NR,$0}' /etc/passwd 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 8 halt:x:7:0:halt:/sbin:/sbin/halt 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 10 operator:x:11:0:operator:/root:/sbin/nologin内置变量的特殊用法:
字符 含义 $0 表示整个当前行 NF 字段数量 NF(Number 数量 ; field 字段) ;NF:列的个数 NR 每行的记录号,多文件记录递增 Record [ˈrekɔ:d] NR :行号 \t 制表符 \n 换行符 ~ 匹配 !~ 不匹配 -F'[:#/]+' 定义三个分隔符使用 NR 行号来定位,然后提取 IP 地址
注:这个思路很好,之前都是通过 过滤关键字来定位,这次是通过行号,多了一种思路
[root@CentOS83 ~]# ifconfig ens33 | awk 'NR==2{print $2}' 10.170.80.83注:NR==2 表示行号为第 2 行
NR 与 FNR 的区别
[root@CentOS83 ~]# awk '{print NR"\t"$0}' /etc/hosts /etc/hostname 1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 3 10.170.80.80 centos83 4 10.170.80.81 centos81 5 10.170.80.82 centos82 6 10.170.80.83 centos83 7 10.170.80.84 centos85 8 10.170.80.85 centos86 9 CentOS83 [root@CentOS83 ~]# awk '{print FNR"\t" $0}' /etc/hosts /etc/hostname 1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 3 10.170.80.80 centos83 4 10.170.80.81 centos81 5 10.170.80.82 centos82 6 10.170.80.83 centos83 7 10.170.80.84 centos85 8 10.170.80.85 centos86 1 CentOS83注:对于 NR 来说,在读取不同的文件时,NR 是一直加的 ; 对于 FNR 来说,在读取不同的文件时,它读取下一个文件时,FNR 会从 1 开始重新计算的
#:使用 3 种方法去除首行 [root@CentOS83 ~]# route -n | grep -v Kernel Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.170.80.1 0.0.0.0 UG 100 0 0 ens33 10.170.80.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33 方法 2:sed 1d #删除第 1 行的内容 [root@CentOS83 ~]# route -n | sed 1d 方法 3: awk [root@CentOS83 ~]# route -n | awk 'NR!=1 {print $0}'匹配,使用 awk 查出以包括 root 字符的行 , 有以下 3 种方法
[root@CentOS83 ~]# awk -F: '/root/{print}' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@CentOS83 ~]# awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@CentOS83 ~]# awk -F: '/root/{print $0}' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin做一个不匹配 root 行:
[root@CentOS83 ~]# awk -F: '!/root/{print $0}' /etc/passwd以 bash 结尾的行:
[root@CentOS83 ~]# awk -F: '/bash$/{print $0}' /etc/passwd总结:
24.1 shell 中的色彩处理
24.2 awk 基本应用
24.3 awk 高级应用