经过几天的努力,简单的对爬虫有点认识,获取mantis上bug相关信息已经成功了 在浏览器登录内网mantis,进入登录网页,但是不要登录 右击选择“检查”或者F 11, 调出网页编码,
经过几天的努力,简单的对爬虫有点认识,获取mantis上bug相关信息已经成功了
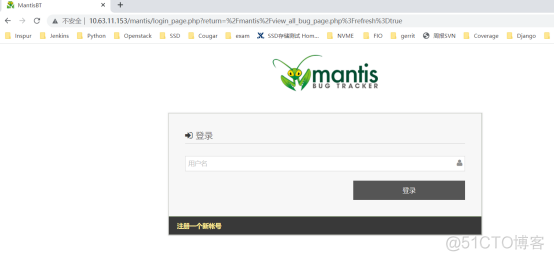
在浏览器登录内网mantis,进入登录网页,但是不要登录
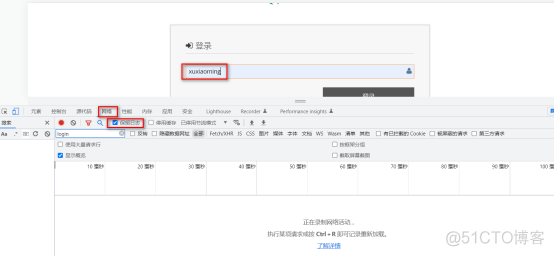
右击选择“检查”或者F11,调出网页编码,然后再输入登录的用户名
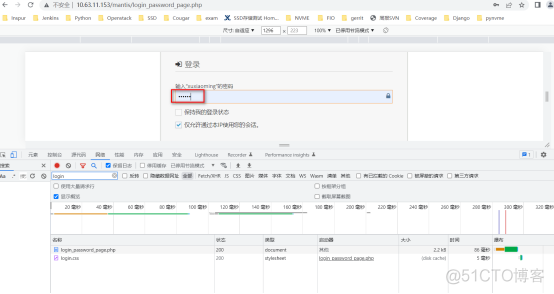
再输入密码
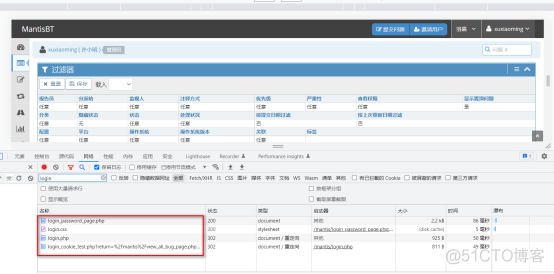
这时就可以看到登录的网页相关信息。(我一开始一溜烟的输入用户名和密码,然后F12,发现什么都没有,看不到任何login网页信息,犯了一个低级错误,这就是菜鸟应该踩的坑)
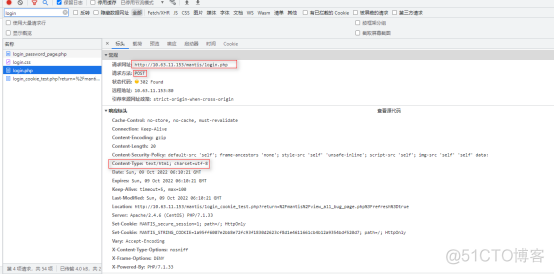
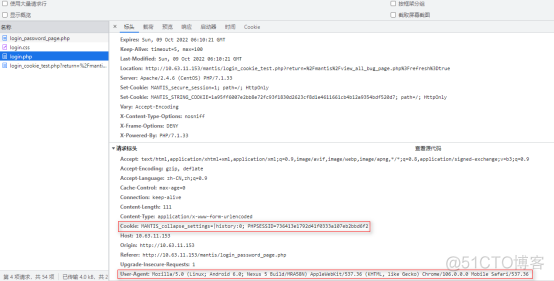
搜索login主页面,可以看到登录的相关信息,重点关注一下登录的网址,有时候这个网址,可能跟我们在浏览器中输入的网址不一样,一定要用这个网址。
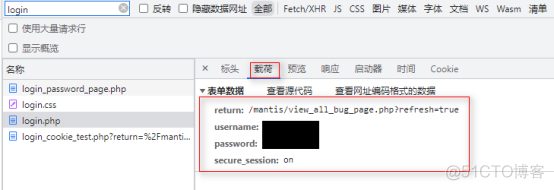
在载荷中可以看到我们登录的相关账号信息,但是本次试验不用账号和密码登录,使用cookie信息登录

这里可以看到cookie的相关信息,以及使用期限
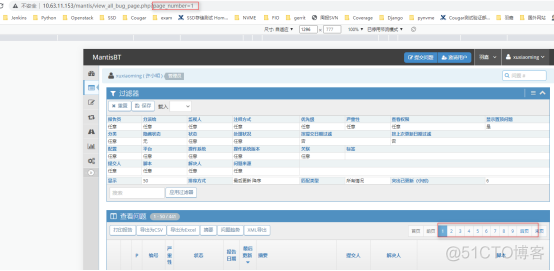
由于我们的网页是分屏显示的,可能有多页,实际中在网址中需要加page_number
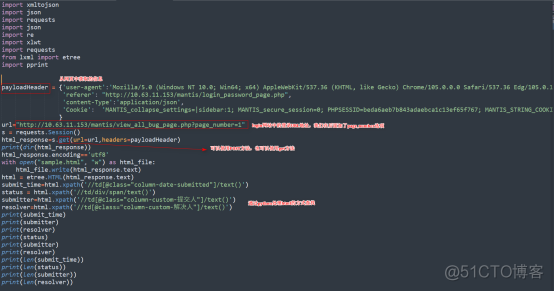
这是实际运行的脚本,payloadHeader也可以用账号和密码来做。
在获取网页信息的时候可以用个get和post两种方法,最好选择login中的方法
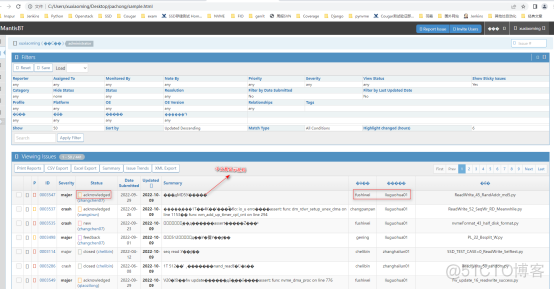

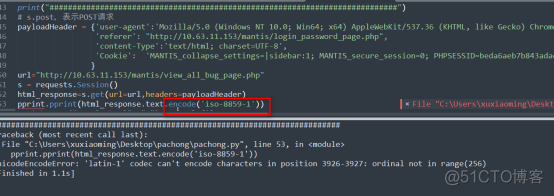
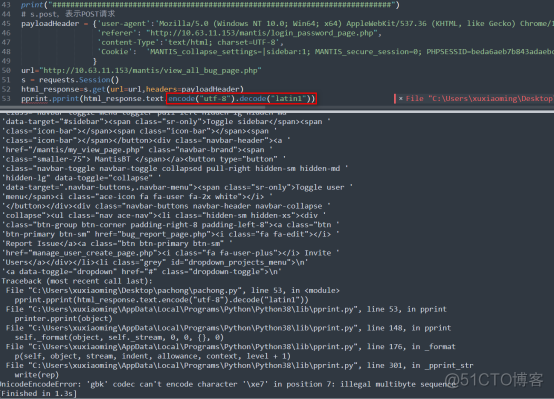
爬到的内容,中文无法显示,一直无法解决?但是在实际搜索中是用中文搜索的。

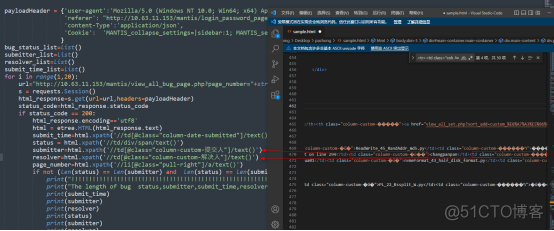
根据HTML的结构特征,我们通过python处理html的方式去获取我们想要的内容
问题:
采取了如下的解码方法,中文始终无法解决,都是乱码