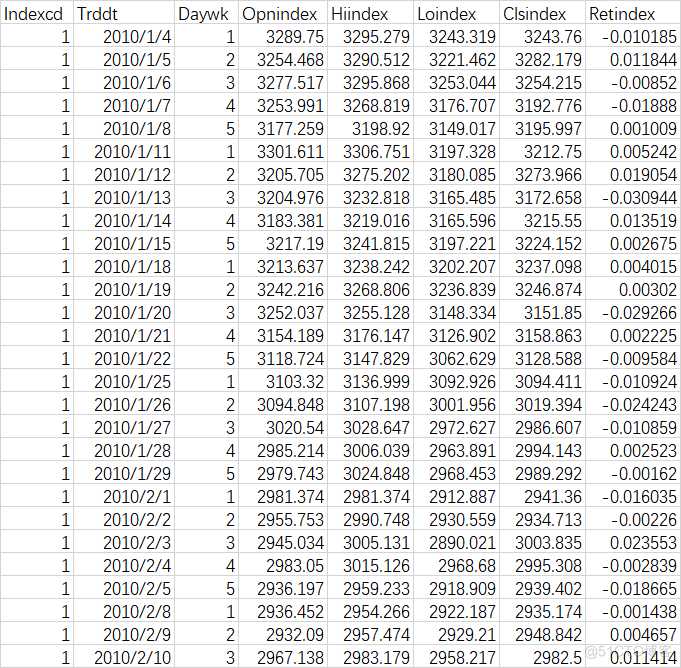
示例数据:
1. 选取头尾数据
1.1 head
head() 方法默认选取Dataframe的前五行数据
df.head()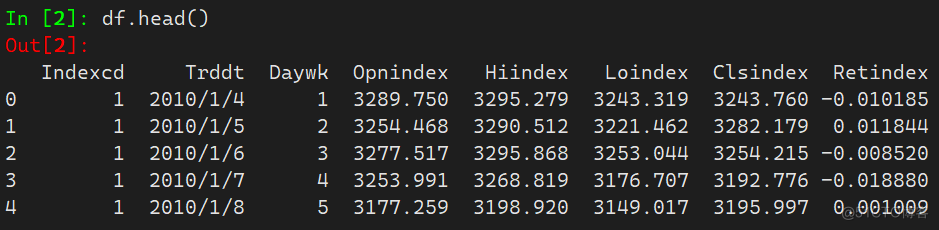
1.2 tail
tail()方法默认选取Dataframe的末尾五行数据
df.tail()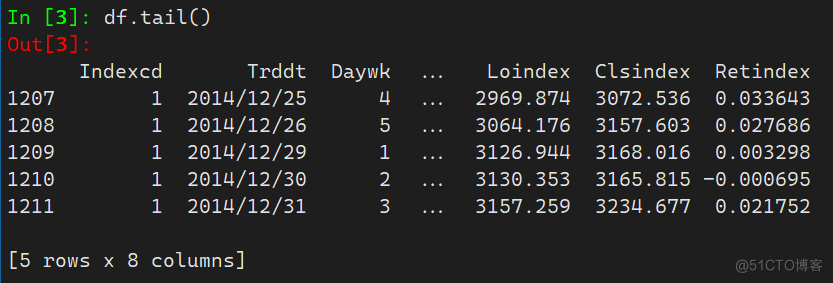
2. 选取列数据
2.1 df[col]
col表示列名,传入指定列名选择指定列
df["Clsindex"]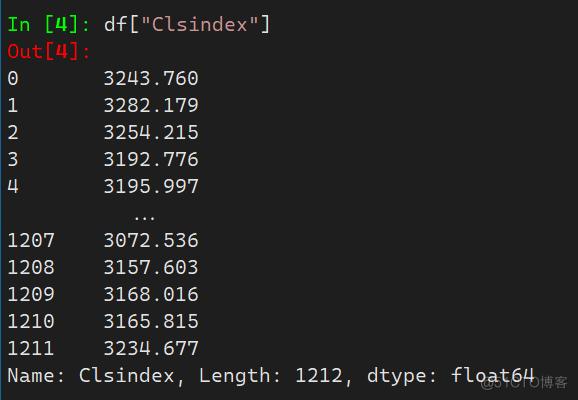
2.2 df.col
以 . 连接,注意用这种方式选取列不可以存在空格以及 .
df.Clsindex输出结果同上
2.3 df.get
使用get方法,参数key表示要选取的列,参数default表示存在未查找到的列时所返回的值
df.get( key=["Clsindex", "Retindex"], default="error" )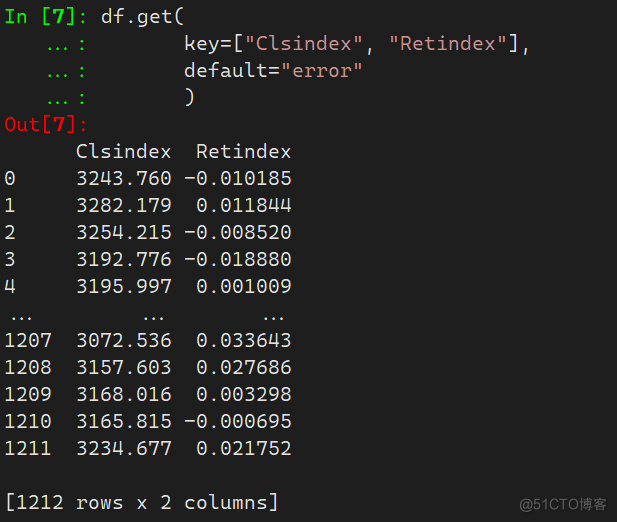
3. select_dtypes 数据类型筛选
select_dtypes方法可以通过每一列的数据类型进行筛选,参数include表示要包含的列,参数exclude表示不包含的列
df.dtypes # 查看数据类型 df.select_dtypes( include="float64", exclude=["int64", "object"] )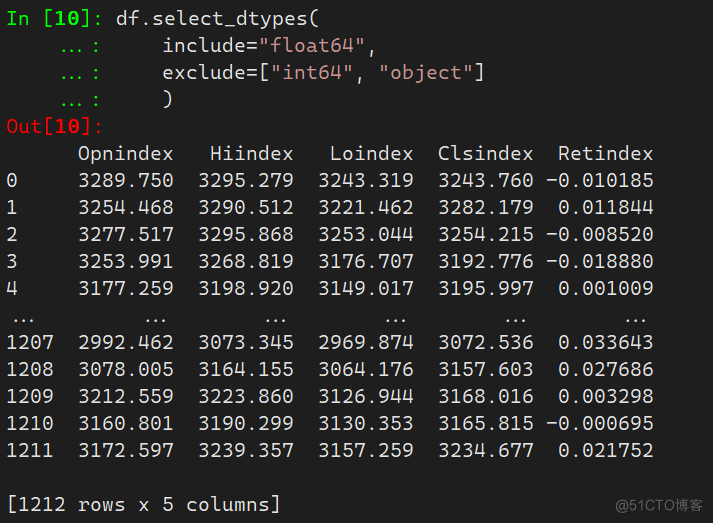
4. isin筛选
- 正向筛选
isin方法可以通过筛选出含有指定信息的列,当无法查找到时不显示
year_list = ["2010/1/8", "2014/12/26"] df[df["Trddt"].isin(year_list)]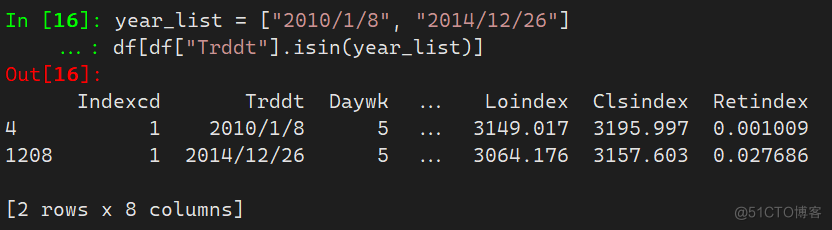
- 反向筛选
将筛选条件使用( )括起来然后在其前面加~号即可
year_list = ["2010/1/8", "2014/12/26"] df[~(df["Trddt"].isin(year_list))]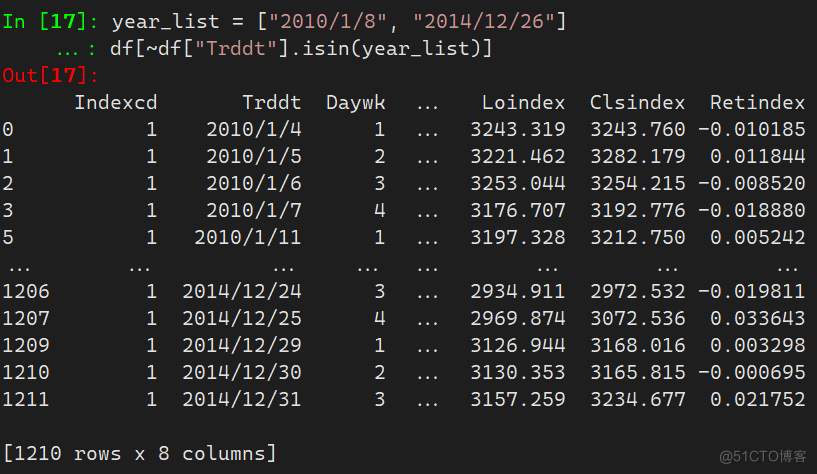
5. sample 随机选取数据
sample的参数较多,可以直接看下面代码中的注释
df.sample( n=2, # 随机获取数据的数量 frac=None, # 随机获取数据的比例 replace=False, # 是否允许数据重复出现 weights=None, # 随机数值出现的权重 random_state=None, # 随机种子数 axis=0, # 轴方向的设置,选取行还是选取列 )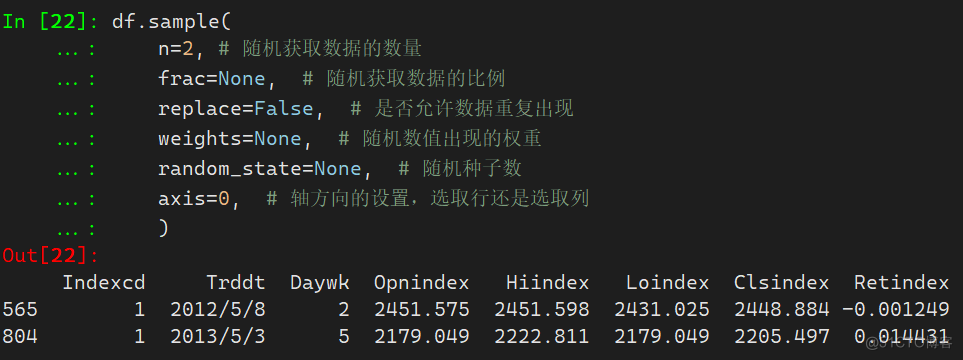
6. loc
loc方法是df.loc[row_name, col_name],其使用行名搭配列名使用的,使用频率非常高。
索引设置 输出 df.loc[:] 选取所有行和列 df.loc[:, "Trddt"] 选取所有行,Trddt列 df.loc[:, "Trddt": "Clsindex"] 选取所有行,"Trddt"到"Clsindex"的列(注意此处前后均为闭区间) df.loc[:, ["Trddt", "Clsindex"]] 选取所有行,"Trddt"和"Clsindex"两列 df.loc[851] 表示选取index为851的行 df.loc[: 851] 选取从索引刚开始到索引为851的行 df.loc[850, 851], : 选取index为850和851的行 df.loc[["此处为bool型列表", :]] 通过布尔型删选为True的数据,注意布尔型列表的长度要与数据长度一致, 同理可应用于列7. iloc
iloc的使用方式为df.iloc[row_index, col_index],也是核心的筛选方式,其原理与loc方法非常相似,只是将原来通过行名列名筛选的方式变成了行索引数和列索引数筛选,需要注意iloc方法筛选数据用列表形式筛选数据是左闭右开的,此处仅介绍以下结合numpy的筛选
df.iloc[:, np.r_[0:3, 4]] # 筛选第0列到第3列以及第四列,通过这种方式可以筛选一列连续的列以及单独的列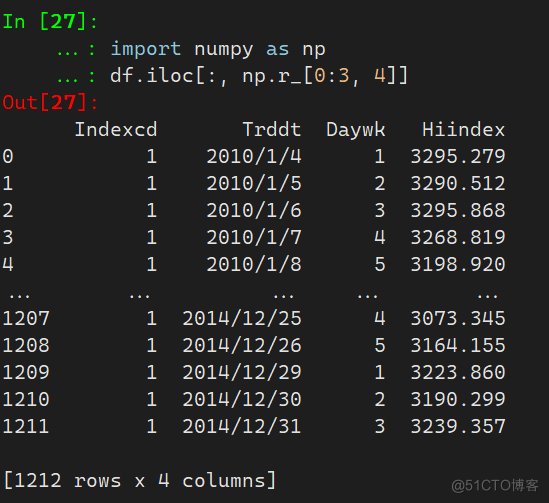
8. at和iat
at方法通过设置索引名来进行筛选, 而iat方法通过设置索引位置来进行筛选,此处仅介绍at
df.at[851, "Trddt"] df.loc[851].at["Trddt"] df["Trddt"].at[851] df.iloc[851].at["Trddt"] # 注意这里的851指的是索引数
10. 条件筛选
10.1 数学表达式
通过数学表达式进行筛选,这里仅演示一部分
函数 数学符号 含义 eq() == 等于 ne() != 不等于 le() <= 小于等于 lt() < 小于 ge() >= 大于等于 gt() > 大于- 普通比较筛选
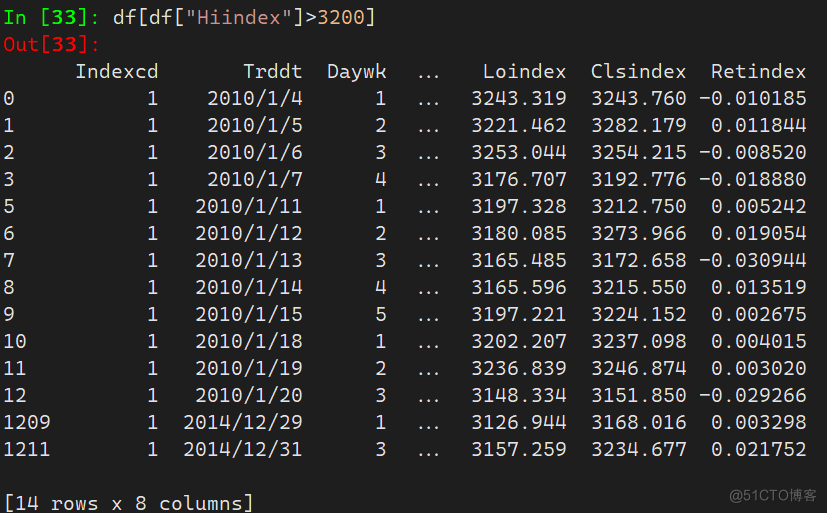
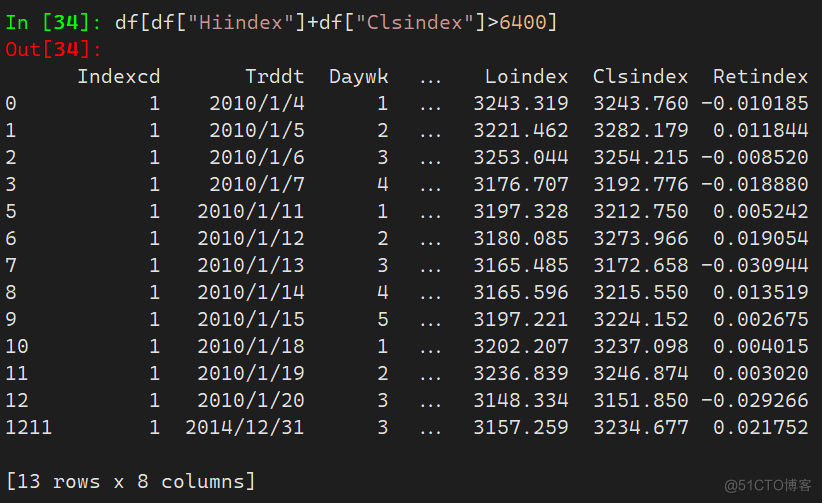
- 加减乘除运算筛选
10.2 多个条件
多条件筛选主要是通过逻辑和(&)与逻辑或(|)进行筛选的
df[(df["Hiindex"]>3200) & (df["Clsindex"]>3200)]
11. 文本数据筛选
关于文本筛选,一般是作用域Series对象上的,返回的是布尔型数据
因为数据的缘故,此处主要介绍参数
11.1 str.contains
Series.str.contains( pat, # 字符串和正则表达式,用于设置筛选的文本 case=True, # 是否区分大小写 flags=0, # 正则表达式模式下的参数设置 na=None, # 缺失值填充参数 reges=True # 是否以正则表达式进行筛选 )补充:Series.str.findall()方法也是可以通过正则表达式进行筛选的
11.2 str.startswith和str.endwith
str.startswith和str.endwith分别用于筛选以指定字符开始或者结尾的数据
12. query
query的一般使用方法是df.query("experssion")
- 通过变量筛选,只要在变量前加@即可
- 通过列表筛选多个值
- 通过逻辑条件进行多条件筛选
- 筛选数据行或列索引中存在特殊符号
13. eval
eval与query类似,在数学运算方面
- 条件判断
- 数学运算
- 变量运算
14. filter
filter方法支持通过索引名称中是否能够匹配到指定内容来进行筛选
DataFrame.filter( item=None, # 索引名称中是否包含设置内容 like=None, # 模糊指定索引名称中是否包含设置内容 regex=None, # 通过正则表达式来指定索引名称中是否包含设置的内容 axis=None # 轴方向的设置 )15. where
符合要求的返回对应值,不符合的数据修改为指定值,默认为NA
DataFrame.where = ( cond, # 筛选条件 other=NoDefault.no_default, # 替代值的设置,默认为Na axis =None, # 轴方向 inplace=True, # 是否在原数据中进行修改操作 lever=None, # 筛选层级 # 后两个参数使用场景不多 erroea="raise", try_cast=NoDefault.no_default )16. mask
mask方法与where方法相似,不同的地方在于mask是将符合要求的地方进行替换
DataFrame.mask= ( cond, # 筛选条件 other=nan, # 替代值的设置,默认为Na axis =None, # 轴方向 inplace=True, # 是否在原数据中进行修改操作 lever=None, # 筛选层级 # 后两个参数使用场景不多 erroea="raise", try_cast=NoDefault.no_default )