一、Numpy的切片索引
1.1 使用slice内置函数(不常用)
ndarray对象的内容可以通过切片来访问,与 Python 中 list 的切片操作完全一样。 使用slice 并设置start, stop 及 step 参数进行;举例如下:
a = slice(2,9,2) # 2为起点,9为终点,间隔为2 b = np.arange(0,10,1) # b: [0 1 2 3 4 5 6 7 8 9] print(b[a]) # 输出:[2 4 6 8]1.2 使用 [] 切片 (常用,*** 非常重要***)
使用方式与slice相同,上面的例子可以书写为:
b = np.arange(0,10,1) print(b[2:9:2]) # 输出:[2 4 6 8]注意:
1.2.1 针对一维数组:
1.2.2 针对二维数组,与一维数组类似,可以用冒号:代替所有
举例如下:
a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print (a[:,1]) # 第2列元素,输出:[2 4 5] print (a[1,:]) # 第2行元素,输出:[3 4 5] print (a[:,1:]) # 第2列及剩下的所有元素,输出:[[2 3] [4 5] [5 6]]二、Numpy的高级索引
2.1 布尔索引 (常用,*** 非常重要***)
在高级索引中,最为有用的便是:布尔索引; 简单来说就是,在切片的中括号内[],使用筛选条件,该条件会返回一个布尔数据作为Mask,将需要的数据选取出来;实际上,我们并不需要知道Numpy是如何选取出来数据的,只要只要如何使用即可;举例如下:
b = np.arange(0,10,1) print(b[b>5]) # [6 7 8 9] print(b[(b>5) & (b<8)]) # [6 7]注意点一:应用多个条件时,可以使用 &, 各个条件需要放在()内;如上例中的:b[(b>5) & (b<8)] 注意点二:布尔索引不一定要对数组中的所有元素,也可以针对某一行或者某一列进行筛选;举例如下:
a = np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]]) print(a[(a[:,0]>2) & (a[:,1]<10)]) # 输出:[[4 5 6] [7 8 9]] # (a[:,0]>2) 选择出第一列大于2的所有行; # (a[:,1]<10) 选择出第二列小于10的所有行,然后取交集得到最后结果;2.2 花式索引
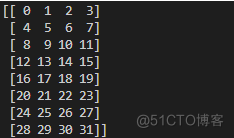
花式索引(Fancyindexing)是一个NumPy术语,它指的是利用整数数组进行索引。假设我们有一个8×4数组:
a = np.arange(32).reshape(8,4)
通过花式索引,我们可以进行如下操作:
选出指定的行,例如选出第1,3,5,7 行: print(a[[1,3,5,7]]), 输出为:

也可以传入负数,选出倒数的行,例如选出最后3行: print(a[[-3,-2,-1]]), 输出为:

也可以传入多个索引数组,返回对应值的一维数组,例如选出 (2,2), (3,3), (5,3) 三个数: print(a[[2,3,5],[2,3,3]]) , 输出为:
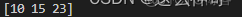
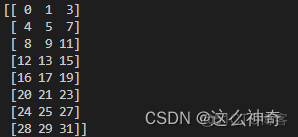
选出指定的列,例如选出第0,1, 3列:print(a[:,[1,2,3]]) , 输出为:
选出指定的行与指定的列,例如选出第0,2,3列,第2,5,6 行的一个3*3数组; print(a[[2,5,6]][:,[0,2,3]]), 输出为:

在5的基础上,还可以通过交换输入的顺序,调整输出的顺序,例如:想要调换2,3列的顺序,同时调换 2,6 行的顺序;print(a[[6,5,2]][:,[0,3,2]])
