在 Java 的集合框架里除了 Collection 类族外还有 Map 类族,在 Java 中 Collection 类族表示存储着对象的各种集合数据结构,而 Map 类族则表示存储着键值对的映射表数据结构。
类族的意思是可以归为一大类的接口、抽象类、实现类。Collection 和 Map 本身都是接口,代表一大类具有共性的数据结构,一个代表集合另外一个代表映射表。而集合、映射表是有序的还是无序的、底层用什么数据结构,则是由类族里的各个实现类决定的,比如 ArrayList 的元素是有序的,HashSet 内的元素不可重复且无序等等。
聊明白了 Collection 和 Map 类族具体是什么后,进入主题,学习一下 Map。本文的大纲如下:
Map 类族的成员
下面的层级架构图可以很好地展示出 Map 类族里都有哪些接口,抽象类和实现类。
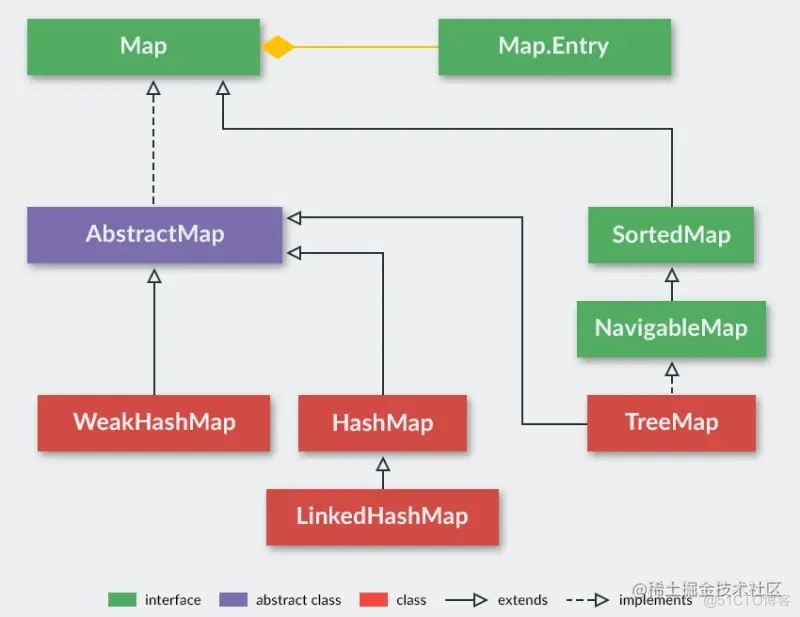
上图清晰地表示出了Map 类族里的 接口、抽象类、实现类还有它们相互之间的关系。
- Map 接口表示一个保存键值对(key-value)的映射表。Map 中不能包含重复的键;每个键最多只能映射到一个值。
- AbstractMap 是一个抽象类,它实现了 Map 接口中的核心 API。其它 Map 的实现类可以通过继承 AbstractMap 来减少重复编码。
- SortedMap 是继承自 Map 的接口,用来表示有序的键值对映射表。
- HashMap、TreeMap、LinkedHashMap 和 WeakHashMap 是具体的 Map 实现类,其中常用的是HashMap 和 TreeMap,另外两个能用到的场景很少见。
- Map.Entry 在上图用组合关系(Composition)表示了它是 Map 的构成元素。 Map.Entry 接口是 Map 接口中定义的内嵌接口,表示 Map 中的单个键值对实体。
HashMap 和 TreeMap
HashMap
HashMap 底层使用哈希表来存储元素。键和值可以是任何类型,也可以是 null 。HashMap 不保证元素的任何存储和遍历顺序,当集合发生变化时,元素的顺序可能会发生变化。存储在 HashMap 中元素被分装到了不同的桶中。元素的 hashCode() 方法确定它属于哪个桶。
举个简单的例子,比如哈希码从 1 到 100 的元素属于第一个桶,哈希码 101 到 200 的元素属于第二个桶,依此类推。以这种分桶的方式存储元素的意义在于,我们可以在搜索、删除元素时消除对不相关桶中的元素的影响,添加元素时如果不发生桶溢出,也不会影响到其他桶的元素。
TreeMap
TreeMap 是提供了顺序保证的键值对结构,其中的元素默认按照元素 Key 的自然排序顺序进行存储,也可以在构造时提供 Comparator 来指定元素的存储顺序。 TreeMap 底层使用平衡的红黑树来存储元素,因此元素插入时间和搜索时间都比较稳定。当需要使用存有大量数据的Map数据结构时,TreeMap 是一个不错的选择。
另外在 Set 章节中我们学习过的例子 TreeSet 其就是依赖 TreeMap 实现的,当时我们也演示过怎么给容器设置排序器(Comparator)。
HashMap 是所有 Map 实现中最快的,如果数据量不大,且对元素的顺序没有要求的场景中更推荐使用 HashMap。
创建 Map
创建 Map 就是创建 Map 接口的实现类的实例,下面是创建 HashMap 和 TreeMap 的示例。
Map mapA = new HashMap();Map mapB = new TreeMap();
默认情况下,可以把任何对象放入Map,但是从 Java 5 开始,使用泛型可以限制 Map 中的键和值的对象类型。
Map<String, Student> map = new HashMap<>();这个 Map 现在只能接受 String 类型的键和 Student 类型的值。这样在访问和迭代Map的键值对时,就无需再对他们进行强制类型转换。
for(Student student : map.values()){// ...
}
for(String key : map.keySet()){
Student value = map.get(key);
// ...
}
声明和创建 Map 时应该始终指定键值对的泛型类型,泛型类型可帮助我们避免向 Map 中插入错误的对象,并使阅读代码的人更容易理解 Map 包含的对象类型。
关于TreeMap 我们还可以在创建实例时给构造方法传递一个 Comparator 来指定元素的排列顺序。
Map<Student, Integer> map = new TreeMap<>(new Comparator<Student>() {public int compare(Student p1, Student p2) {
return p1.score > p2.score ? -1 : 1;
}
});
上面这个示例指定了 map 按照 Student 实例的分数倒序排序。
往 Map 中写入单个元素
调用 Map 实例的 put() 方法,可以往 Map 中写入键值对
Map<String, String> map = new HashMap<>();map.put("key1", "element 1");
map.put("key2", "element 2");
map.put("key3", "element 3");
调用 put() 方法后,会将键映射到值,并将值返回。
只有 Java 的对象才可以用作 Map 中的键和值。如果将原始值(例如 int、double 等)作为键或值传递给 Map,原始值将在作为参数传递之前进行自动装箱。
map.put("key", 123);上例中传递给 put() 方法的值是一个原始 int 值,不过,Java 会将它自动装箱到一个 Integer 实例中。因为 put() 方法需要 Oject或其子类的实例作为键和值,所以将原始值作为键传递给 put() 方法时,会发生自动装箱。
一个给定的键只能在 Map 中出现一次。这意味着,对于键“key1”,在同一个 Map 实例中只能映射一个值。当然,在不同的 Map 实例中是可以存在相同的键的。 如果使用相同的键多次调用 put() 想一个 Map 实例中写入值的话,新值将覆盖旧值,即键只能映射到最后一次调用 put() 方法时传递过来的值。
Map 的键和值可以是Null
有点让人惊讶的是,可以使用 null 作为 Map 中的键。
Map map = new HashMap();map.put(null, "value for null key");
String value = map.get(null);
调用Map 实例的 get() 方法,把 null 作为参数,即可获取 null 键对应的值。null 作为键时同样满足Map 内键不可多次出现的约束,整个 Map 实例中只允许出现一个为 null 的键。
既然键可以为null ,那值更是允许存储为 null 了。
map.put("D", null);Object value = map.get("D");
往 Map 中写入多个元素
Map 接口有一个叫 putAll() 的方法,该方法可以从另一个 Map 实例复制所有键值对到调用 putAll() 方法的 Map 实例中。在集合论中,这也称为两个 Map 实例的并集。
Map<String, String> mapA = new HashMap<>();mapA.put("key1", "value1");
mapA.put("key2", "value2");
Map<String, String> mapB = new HashMap<>();
mapB.putAll(mapA);
上面例程里会把 mapA 中的所有键值对拷贝到 mapB 中。注意,调用 mapB.putAll(mapA) 只会将 mapA 中的键值对复制到 mapB,而不会发生从 mapB 复制到 mapA,要想反向复制,则必须执行代码 mapA.putAll(mapB)。
从 Map 中获取值
要获取存储在 Map 中的指定元素,可以调用 Map 实例的 get() 方法,将该元素的键作为参数传递给 get() 方法,获取对应的值。
Map map = new HashMap();map.put("key1", "value 1");
String element1 = (String) map.get("key1");
get() 方法会返回一个 Java 对象,因为创建 Map 时没有使用泛型限制Map 的键和值的类型,所以返回的是 Object 类的对象,使用时还需要对其进行类型转换。
Map<String, String> map = new HashMap<>();map.put("key1", "value 1");
String element1 = map.get("key1");
如果我们使用泛型为 Map 的键和值指定具体类型,就不再需要转换 get() 方法返回的对象。
getOrDefault
getOrderDefault() 方法的第二个参数可以指定一个默认值,用来在 Map 中不存在给定 Key 的时候,作为默认值进行返回。
Map<String, String> map = new HashMap<>();map.put("A", "1");
map.put("B", "2");
map.put("C", "3");
String value = map.getOrDefault("E", "default value");
检查 Map 中是否存在给定 Key
可以使用 containsKey() 方法检查 Map 是否包含给定的键。
boolean hasKey = map.containsKey("123");如果 map 中存在字符串键"123"的键值对,则 hasKey 变量为 true,否则为 false。
检查 Map 中是否存在给定 Value
Map 接口还有一个 containsValue() 方法可以检查 Map 是否包含某个值。
boolean hasValue = map.containsValue("value-a");如果 Map 存储的键值对中有 "value-a" 这个值,那么 hasValue 变量为 ture,否则为 false。
遍历 Map 的 Key
有三种常用的遍历 Map 的所有 Key 的方式:
- 使用从 keySet() 获取的迭代器。
- 使用 for-each 循环遍历 KeySet
- 使用 Stream API
Map 的 keySet() 方法返回的是一个 Set 数据结构,在之前的章节已经讲过,它实现了 Iterable 接口,且提供了获取 Iterator 的方法,所以这里三种遍历的 Set 方式我们在之前 Set 的章节都已经细讲过,这里直接看一下遍历的例程。
Map<String, String> map = new HashMap<>();map.put("one", "first");
map.put("two", "second");
map.put("three", "third");
// 使用迭代器遍历 Map 的 Key
Iterator<String> iterator = map.keySet().iterator();
while(iterator.hasNext(){
String key = iterator.next();
String value = map.get(key);
}
// 使用 for-each 循环遍历 Map 的 Key
for(String key : map.keySet()) {
String value = map.get(key);
}
// 使用 Stream API
Stream<String> stream = map.keySet().stream();
stream.forEach((value) -> {
System.out.println(value);
});
遍历 Map 的 Value
遍历 Map 的 Value 的方式与 Key 的类似,Map 的 values() 方法会返回Map中所有值组成的集合,所以常用的遍历方式也是那三种。
Map<String, String> map = new HashMap<>();map.put("one", "first");
map.put("two", "second");
map.put("three", "third");
// 使用迭代器遍历
Iterator<String> iterator = map.values().iterator();
while(iterator.hasNext()) {
String nextValue iterator.next();
}
// 使用 for-each 循环遍历
for(String value : map.values()){
System.out.println(value);
}
// 使用 Stream API
Stream<String> stream = map.values().stream();
stream.forEach((value) -> {
System.out.println(value);
});
遍历 Map 的键值对
在开头我们解释 Map 类族层级图时,我们说过在 Map 类族中,用 Map.Entry 接口表示单个键值对实体,Map 接口中有一个 entrySet() 方法可以返回 Map 中的所有键值对组成的 Set 集合。
Map<String, String> map = new HashMap<>();map.put("one", "first");
map.put("two", "second");
map.put("three", "third");
// 通过迭代器遍历 所有Map.Entry
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while(iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
String key = entry.getKey();
String value = entry.getValue();
}
// 使用 for-each 循环遍历所有 Map.Entry
for(Map.Entry<String, String> entry : map.entrySet()){
String key = entry.getKey();
String value = entry.getValue();
}
注意,遍历键值对是,需要通过 Map.Entry 的实例的 getKey() 和 getValue() 方法才能获取到键和值。
从 Map 中删除条目
可以通过调用 remove(Object key) 方法删除 Map 中键为 key 参数指定值的键值对条目。
map.remove("key1");上面的程序执行后,变量 map 引用的 Map 将不再包含键 "key1" 对应的条目(键值对)。
remove() 方法是删除键对应的单个条目,如果想要清空 Map 中的所有条目,可以通过 Map 实例调用 clear() 方法进行清空。
map.clear();replace方法-存在则替换
使用 replace() 方法可以替换 Map 实例中的元素。
map.replace(key, value)可能有人会说,直接调用 put 方法把键对应的新值存储到 Map 实例里不就是更新了吗? 其实 replace() 方法除了提供更新键值的基础功能外,还提供了存在则替换的特性,什么意思呢?如果replace() 方法的 key 参数指定的键在 Map 中已经存在对应的键值对,则 replace() 方法会把键值对的值更新成 value 参数指定的值。如果在 Map 里没有值映射到给定键,则不会插入任何值。
Map map = new HashMap<>();map.replace("key", "val2"); // map 中还没有"key"对应的条目, 不更新
map.put("key", "val1"); // 向 map 中存入 "key" ==> "val1" 条目
map.replace("key", "val2"); // 将条目更新成 "key" ==> "val2"
获取 Map 包含的键值对数量
使用 size() 方法可以获取到 Map 中的条目数。
int entryCount = map.size();检查 Map 是否为空
Map 接口有一个特殊的方法来检查 Map 是否为空。这个方法是 isEmpty(),如果 Map 实例包含 1 个或多个条目,isEmpty() 方法将返回 false。如果 Map 不包含条目,isEmpty() 将返回 true。
if (map.isEmpty()) {// do something...
}
把对象List 转化为 Map
真实开发场景下用到 List 转换成 Map的操作时,往往是把对象 List 转换成 以对象ID为 Key 的Map,这种情况下我们可以用下面这个程序进行转换,当然Key不一定非得是对象的ID,换成Name 之类的属性值也是同样方法进行转换。
import java.util.ArrayList;import java.util.List;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
public class ListStreamToMap {
public static void main(String[] args) {
List<Animal> aList = new ArrayList<>();
aList.add(new Animal(1, "Elephant"));
aList.add(new Animal(2, "Bear"));
Map<Integer, Animal> map = aList.stream()
.collect(Collectors.toMap(Animal::getId, Function.identity()));
map.forEach((integer, animal) -> {
System.out.println(animal.getName());
});
}
}
总结
这篇文章给大家盘点了一下 Map 的整个体系中都有哪些实现类,并针以最常使用的 HashMap 为切入点,介绍了 Map 这种数据结构在开发中常会使用到的功能。
这篇文章主要是让新手快速入门或者是让老手在开发中快速查询参考,对于 Map 底层的数据结构实现、怎么解决哈希碰撞、怎么扩容这些并没涉及,这块面试的时候还精彩被问到,在会使用 Map 的基础上,一定要再看看这方面的知识。
这里介绍的 Map 都是并发不安全的容器,在多线程环境下不能使用,JUC 里的 ConcurrentHashMap 是 Java 专门针对多线程并发环境提供的 Map 类并发容器,具体怎么使用等到后面学习 JUC 和并发容器的时候我们再细讲。