
计算机视觉研究院专栏
作者:Edison_G

感谢大家一直支持“计算机视觉研究院”微信公众号,平时有没做好的地方望大家见谅,做的不好的希望您指出来,我们会修正不对之处,将做得更好,将最好的分享给大家!

今天给大家讲讲DNN(深度神经网络)在训练过程中遇到的一些问题,然后我们应该怎么去注意它,并学会怎么去训练它。
1、数据集的准备:
必须要保证大量、高质量且带有准确标签的数据,没有该条件的数据,训练学习很困难的(但是最近我看了以为作者写的一篇文章,说明不一定需要大量数据集,也可以训练的很好,有空和大家来分享其思想---很厉害的想法);
2、数据预处理:
这个不多说,就是0均值和1方差化,其实还有很多方法;

3、Minibatch:
这个有时候还要根据你的硬件设备而定,一般建议用128,8这组,但是128,1也很好,只是效率会非常慢,注意的是:千万不要用过大的数值,否则很容易过拟合;
4、梯度归一化:
其实就是计算出来梯度之后,要除以Minibatch的数量,这个可以通过阅读源码得知(文章链接:各类的梯度优化);
5、学习率:
① 一般都会有默认的学习率,但是刚开始还是用一般的去学习,然后逐渐的减小它;
② 一个建议值是0.1,适用于很多NN的问题,一般倾向于小一点;但是如果对于的大数据,何凯明老师也说过,要把学习率调到很小,他说0.00001都不为过(如果记得不错,应该是这么说的);
③ 一个对于调度学习率的建议:如果在验证集上性能不再增加就让学习率除以2或者5,然后继续,学习率会一直变得很小,到最后就可以停止训练了;
④ 很多人用的一个设计学习率的原则就是监测一个比率(每次更新梯度的norm除以当前weight的norm),如果这个比率在10e-3附近,且小于这个值,学习会很慢,如果大于这个值,那么学习很不稳定,由此会带来学习失败。
6、验证集的使用:
使用验证集,可以知道什么时候开始降低学习率和什么时候停止训练;
7、weight初始化:
① 如果你不想繁琐的话,直接用0.02*randn(num_params)来初始化,当然别的值也可以去尝试;
② 如果上面那个建议不太好使,那么就依次初始化每一个weight矩阵用init_scale / sqrt(layer_width) * randn,init_scale可以被设置为0.1或者1;
③ 初始化参数对结果的影响至关重要,要引起重视;
④ 在深度网络中,随机初始化权重,使用SGD的话一般处理的都不好,这是因为初始化的权重太小了。这种情况下对于浅层网络有效,但是当足够深的时候就不行,因为weight更新的时候,是靠很多weight相乘的,越乘越小,类似梯度消失的意思。
8、RNN&&LSTM(这方面没有深入了解,借用别人的意思):
如果训练RNN或者LSTM,务必保证gradient的norm被约束在15或者5(前提还是要先归一化gradient),这一点在RNN和LSTM中很重要;
9、梯度检查:
检查下梯度,如果是你自己计算的梯度;如果使用LSTM来解决长时依赖的问题,记得初始化bias的时候要大一点;
10、数据增广:
尽可能想办法多的扩增训练数据,如果使用的是图像数据,不妨对图像做一点扭转,剪切,分割等操作来扩充数据训练集合;
11、dropout:(文章链接:Dropout终于要被替换 (文末有下载链接及源码))
12、评价结果:
评价最终结果的时候,多做几次,然后平均一下他们的结果。

摘自于——PaperWeekly
补充:
1、选择优化算法
传统的随机梯度下降算法虽然适用很广,但并不高效,最近出现很多更灵活的优化算法,例如Adagrad、RMSProp等,可在迭代优化的过程中自适应的调节学习速率等超参数,效果更佳;
2、参数设置技巧
无论是多核CPU还是GPU加速,内存管理仍然以字节为基本单元做硬件优化,因此将参数设定为2的指数倍,如64,128,512,1024等,将有效提高矩阵分片、张量计算等操作的硬件处理效率;
3、正则优化
除了在神经网络单元上添加传统的L1/L2正则项外,Dropout更经常在深度神经网络应用来避免模型的过拟合。初始默认的0.5的丢弃率是保守的选择,如果模型不是很复杂,设置为0.2就可以;
4、其他方法
除了上述训练调优的方法外,还有其他一些常用方法,包括:使用mini-batch learning方法、迁移训练学习、打乱训练集顺序、对比训练误差和测试误差调节迭代次数、日志可视化观察等等。
当今RL的问题很多,诸如收敛看运气效果看天命之类的,之前有很多大佬也有吐槽过。今天要讨论的 RL 泛化能力问题,就是这样的一个问题。

案例一,众所周知DeepMind和OpenAI都做游戏 AI,一个做星际一个做Dota,为了训练出一个超过人类水平的 AI,两家共同的思路就是 self-play,但是实际上 self-play 会遇到训练时过拟合于对手策略的问题,因为实际部署时会遇到各种各样奇葩的对手策略,训练时从来没有见过奇葩对手的模型会严重翻车。

案例二,robotics 训练,因为机器人机械臂有使用寿命的限制,目前常用的一种方式是在物理仿真模拟环境中训练,模型收敛后部署到现实世界中,然而模拟器不大可能建模出现实世界中所有的变量,实际上模拟器中表现良好的模型,在现实世界的表现会有所下降。
目前主要考虑两种解决方案:一是在训练期在模拟器中加入随机化,二是认为从模拟器到现实是一个迁移学习的,以 sim2real 为关键词搜索,这方面的研究非常多,这里简单列举两篇:
案例三,环境动态表现出高度 non-stationary 特性的任务,如推荐系统、定价系统、交易系统等(应该是没有哪个公司真的在交易系统里上 RL 的吧),这些任务的一个共同特点是业务敏感,绝对不会真的让模型在训练时与环境交互。
一般的做法是线上开一个子进程去收集样本回来做完全意义上的 off-policy 训练(就此延伸出去的一个研究方向叫 batch reinforcement learning,不过这已经不在本文讨论范围内了)。由于环境动态高度非平稳,三个月前训练的模型可能现在已经不 work 了,据我了解到的一点点情况,目前工业界没啥太好的办法,唯不停地重新训练而已。


DRL的过拟合是一个属于RL的问题还是一个属于DL的问题?

Does robust optimization work for RL generalization?
学术界中,robust optimization(以下简称 RO)是一个比较容易想到的解决方案,在早期 RL 研究者们还聚焦于各种 MDP 数学意义上的 tractability 的时候,就已经有一些工作研究在不完美、或者包含 uncertainty 的环境动态的基础上进行优化,这种优化一般被称作 robust MDP。



解决方案归类
总结一下上面提到的几类方法:
- Robust optimization
- environmental randomization
- heuristic regularization
- sim2real (only applicable for robotics)
目前学术界对 RL 泛化问题的研究实际上很难完全分类,因为目前鲜有能构成体系的研究工作,提出的各种解决方案颇有东一榔头西一棒槌之感,下面列两篇无法分类到以上任何类别的工作:
Improving Generalization in Meta Reinforcement Learning using Neural Objectives
https://openreview.net/forum?id=S1evHerYPr
On the Generalization Gap in Reparameterizable Reinforcement Learning
https://arxiv.org/abs/1905.12654
第二篇是 RL 泛化问题上为数不多的理论文章之一,用 finite sample analysis 做分析的,值得一读,缺点是只能用于 on-policy 和 reparameterizable state 的情况。
你说的这个环境随机化,它香吗?
目前的工业应用中,环境加随机化可能是使用最广泛的解决方案,在18年Assessing Generalization in Deep Reinforcement Learning一文中,作者基于若干组MuJoCo 的实验,声称环境加随机化是目前为止提升泛化能力最有效的方法。
但A Study on Overfitting in Deep Reinforcement Learning在迷宫环境上的实验则得出了完全相反的结论,作者称RL训练出的模型会死记硬背,随机化技巧无法避免RL模型的过拟合。
那么,这个环境随机化,它真的那么香吗?
首先一个比较容易想到的问题,环境复杂度的问题:加入随机化后环境的数量会随随机变量数量的上升而指数上升,今年ICLR就有审稿人提出了这一质疑:
If there are, e.g., 20 parameters, and one picks 3 values for each, there are 3^20 variations of the environment. This exponential growth seems problematic, which is also mentioned by R3.
环境复杂度的问题会进一步提升训练的复杂度:加入环境随机化后,模型训练达到收敛所需的样本量实际上也显著上升了,由于其他论文里都不怎么提,这里以TD3为 baseline放一点点自己的实验图作为证据(忽略绿色曲线),这里可以看到HalfCheetah-v2环境上,加入了环境随机的模型用了大约三倍的 iteration 才达到了原始版本TD3的水平。
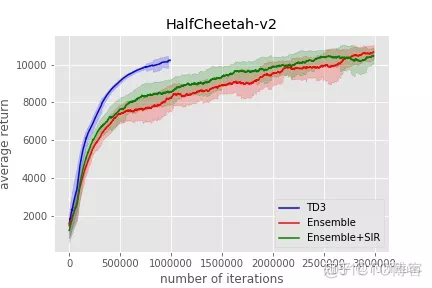
从上面的图中还可以看出一个新的问题:方差问题。加入环境随机化以后,模型表现无论是在训练环境中,还是测试环境中,表现出的方差要大于在单一环境上训练,这也与本渣渣去年在公司实习期间的一些实验结论一致,当时的结论是随机化训练的方差会比只在一个固定环境上训练高出若干个数量级。
对于加入随机化以后过度探索的问题,OpenAI提出过一个不错的解决思路:
https://openai.com/blog/solving-rubiks-cube/
Difficulties
理论层面,由于RL本身的理论建模中不存在泛化问题,目前学术界的研究大部分都是empirical的工作,理论性文章很少,上面列举的唯一一篇理论paper的假设条件还离实践比较远。
实践层面,最大的困难来自于当前model-free RL高方差的尿性,开篇已经提到过,MuJoCo和Atari一类的环境对于RL泛化问题是比较弱的,如果你有机会在企业级别的场景下做RL实验,那么一定会在泛化方面有更深刻的体会。
因此,在MuJoCo、Atari、或者是之前有作者用过的随机迷宫之类的环境中,如果你做出了某种提升,可能提升的幅度还不如代码层面优化换random seed或者reward scaling来的明显,今年ICLR就有一篇讲RL的code-level optimization的文章工作被accept,足以说明现在的RL研究者对reproducibility的殷切期盼。
Implementation Matters in Deep RL: A Case Study on PPO and TRPO
https://openreview.net/forum?id=r1etN1rtPB
众所周知 model-free RL 换个 seed 或者做个 reward scaling 就可能让模型的表现从地下到天上,那么除非你的方法表现可以全方位碾压各种 baseline,否则如何说明这种影响不是来源于 seed 之类的无关影响因素呢?
/End.
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

计算机视觉研究院