

1. 概述
MVS是一种从具有一定重叠度的多视图视角中恢复场景的稠密结构的技术,传统方法利用几何、光学一致性构造匹配代价,进行匹配代价累积,再估计深度值。虽然传统方法有较高的深度估计精度,但由于存在在缺少纹理或者光照条件剧烈变化的场景中的错误匹配,传统方法的深度估计完整度还有很大的提升空间。
近年来卷积神经网络已经成功被应用在特征匹配上,提升了立体匹配的精度。在这样的背景下,香港科技大学Yaoyao等人,在2018年提出了一种基于深度学习的端到端深度估计框架——MVSNet[1]。
虽然这两年已经有更多的框架在精度和完整度上面超过了MVSNet,但笔者发现,无论是基于监督学习的R-MVSNet 、Cascade – MVSNet等网络,还是基于自监督学习的M3VSNet,核心网型设计都是在借鉴MVSNet而完成的,而且MVSNet也是比较早期且较为完整的三维重建深度学习框架,了解该框架的原理、数据IO与实际操作能加深对2020年以来各种新方法的理解。
本篇的主要内容为MVSNet的深度估计框架介绍、深度估计原理及如何利用MVSNet进行三维重建的具体操作。
(注意:本方法需要11GB以上的GPU,推荐使用至少NVIDIA 1080Ti,且同样建议使用Linux进行操作。驱动建议安装CUDA9.0以上版本。)
2. MVSNet框架
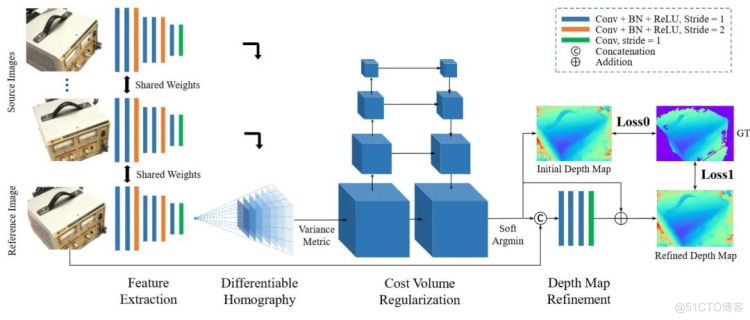
图1 MVSNet网络形状
由上图所示,MVSNet是一种监督学习的方法,以一个参考影像和多张原始影像为输入,而得到参考影像深度图的一种端到端的深度学习框架。网络首先提取图像的深度特征,然后通过可微分投影变换构造3D的代价体,再通过正则化输出一个3D的概率体,再通过soft argMin层,沿深度方向求取深度期望,获得参考影像的深度图。
3. 基于深度学习的深度估计原理
按照立体匹配框架[2],基于M VSNet的深度图估计步骤如下:深度特征提取,构造匹配代价,代价累计,深度估计,深度图优化。
深度特征提取。深度特征指通过神经网络提取的影像特征,相比传统SIFT、SURF的特征有更好的匹配精度和效率[3]。经过视角选择之后,输入已经配对的N张影像,即参考影像和候选集。首先利用一个八层的二维卷积神经网络(图2)提取立体像对的深度特征Fi,输出32通道的特征图.
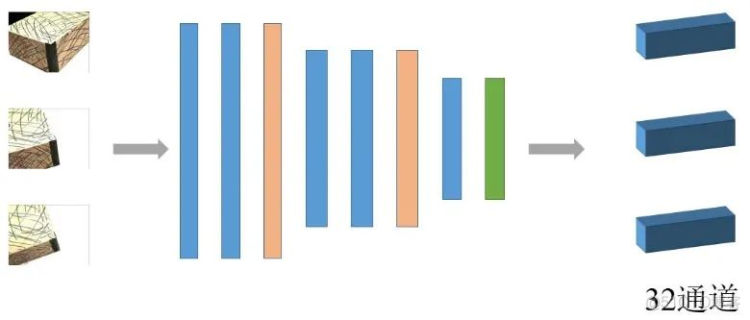
图2 特征采样的神经网络
为防止输入的像片被降采样后语义信息的丢失,像素的临近像素之间的语义信息已经被编码到这个32通道的特征中,并且各个图像提取过程的网络是权值共享的。

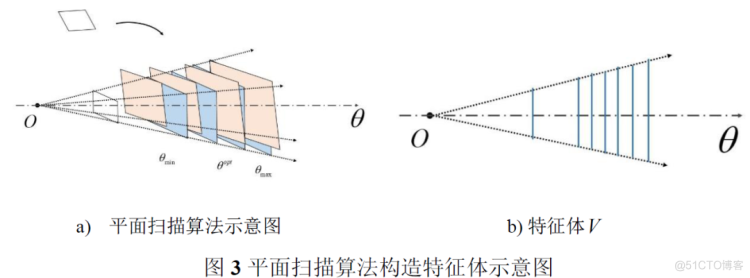

考虑到对亚像素的深度估计,以保证深度图平滑,该单应性矩阵是完全可以微分的。通过投影变换,N张影像可形成N个特征体(图3-b),这个特征体就是匹配代价的表示。
代价累积。MVSNet的代价累积通过构造代价体实现的。代价体是一个由长、宽与参考影像长宽一样的代价图在深度方向连接而成的三维结构(图4-a),在深度维度,每一个单位表示一个深度值。其中,某一深度的代价图上面的像素表示参考影像同样的像素在相同深度处,与候选集影像的匹配代价。

图4 代价累计结果

当已知概率体时,最简单的方法可以获取参考影像的所有像素在不同深度的概率图,按照赢者通吃原则[6]直接估计深度图。
然而,赢者通吃原则无法在亚像素级别估计深度,造成深度突变、不平滑情况。所以需要沿着概率体的深度方向,以深度期望值作为该像素的深度估计值,使得整个深度图中的不同部分内部较为平滑。
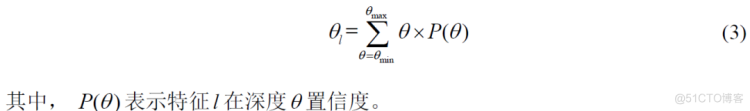
深度图优化。原始代价体往往是含有噪声污染的,因此,为防止噪声使得网络过度拟合,MVSNet中使用基于多尺度的三维卷积神经网络进行代价体正则化,利用U-Net网络[7],对代价体进行降采样,并提取不同尺度中的上下文信息和临近像素信息,对代价体进行过滤(图5)。
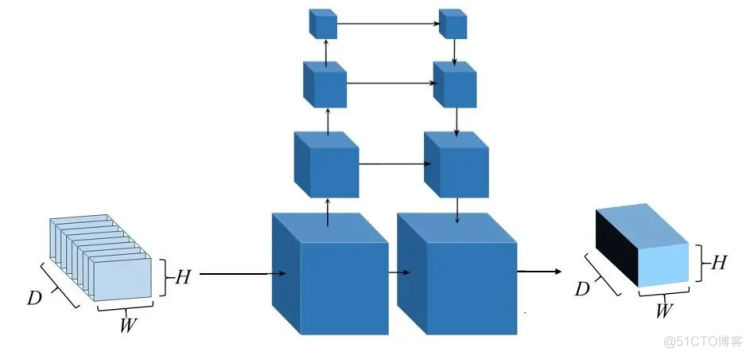
图5 MVSNet代价体正则化
4. MVSNet实战操作
首先感谢Yaoyao(香港科技大学)给出的开源代码和已经预处理好的模型和数据。其次,本节首先介绍MVSNet利用开源数据集中的数据进行深度估计和点云恢复,之后,回顾该网络数据IO相关的要求和数据文件夹结构,最后,介绍如何利用自己采集的数据进行深度估计和点云恢复。
4.1 利用开源数据集进行深度估计
1) 环境配置
参考Yaoyao的github主页中installation即可完成环境配置。
(https://github.com/YoYo000/MVSNet)
2) 数据整理
在文末分享的百度云盘中下载数据集preprocessed_inputs/dtu.zip和预训练好的网络models/tf_model_19307.zip。将tf_model解压,在其中的3DCNNs/中获得训练好的模型 model.ckpt-100000.data-00000-of-00001。
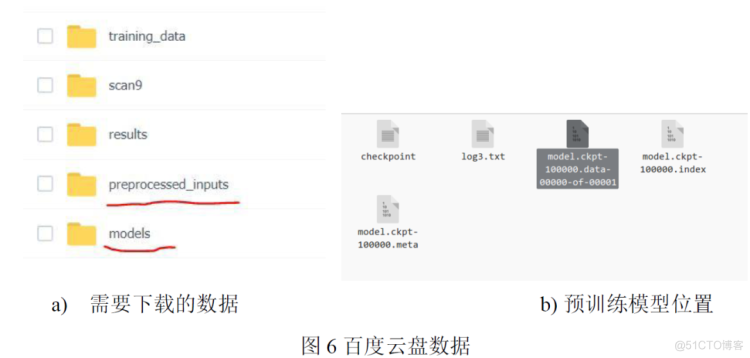
将test.py 中的pretrained_model 地址改为tf_model中3DCNNs的地址。
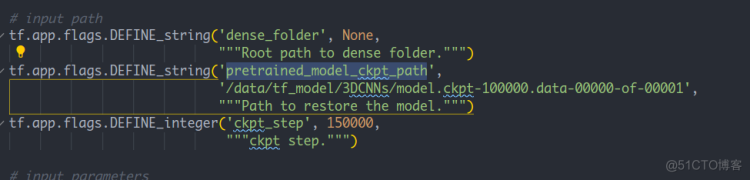
图7 更改预训练模型的地址
解压下载好的dtu.zip,到用于深度估计的数据集。以scan10为例,该文件夹的结构如下图。
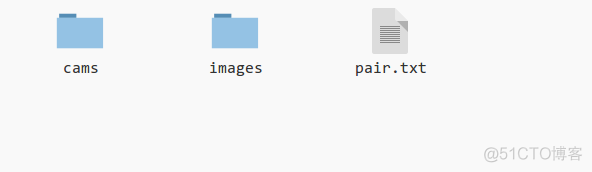
图8 scan10文件夹结构
3) 深度估计
运行代码:
注意:
- flag --dense_folder 要设定为scan10的地址。
- flag –regularization表示正则化代价体的方式,MVSNet中使用的是3D卷积神经网络。
- 图片的大小可以按照GPU的大小变更参数,但是需要时32的整数倍(特征提取时2D神经网络要求图像是32的整数倍)
- Max_d 和interval_scale 建议先按照默认的要求,在使用自己的数据时,我们会给出调整的方式
4) 查看深度估计结果
深度估计结束后,会在dense_folder文件夹中生成文件夹depths_mvsnet/。利用visualize.py 即查看相关的深度图和概率图(图9),输入代码:
python visualized.py XXXXXXX.pfm
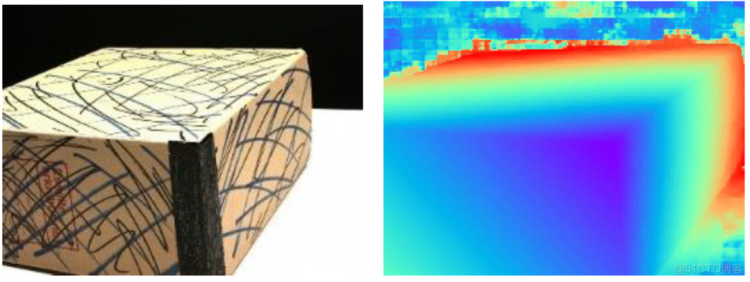

图9 MVSNet深度图估计结果
5) 点云生成
MVSNet只能生成深度图,需要借助其他点云融合方法。这里Yaoyao给出了一种方法——fusible.可以直接利用生成的深度图和RGB图片,生成稠密点云。
- 安装fusible
git clone https://github.com/YoYo000/fusibile
cd fusible
mkdir build && cmake .
make .
- 运行代码
注意:每一个深度图在估计的时候,都有一个对应的概率图,及表示该像素沿深度方向不同的概率,所以flag –prob_threhold 表示用于过滤深度的概率阈值,即如果当前深度图的某个像素的深度对应的概率低于该阈值,则在点云融合的时候,该像素的深度不被使用,即该像素不会被投影到三维空间点。这样可以对稠密点云进行过滤优化。
在dense_folder中,之后会生成新的文件夹points_mvsnet。在该文件夹下,找到consisitency_Check-time/final3d_model.ply. 即为融合之后的三维点云,利用meshlab打开即可。图10是笔者实验过后的稠密点云。

图10 深度图融合之后的稠密点云
6) 流程回顾
环境配置 -> 整理输入数据 -> 配准好flag,运行代码 -> 安装深度融合软件 -> 生成稠密点云
4.2 数据IO要求及数据配置回顾
MVSNet的整个流程完整、简单,再回顾一下整个流程中文件夹的结构。
1) Input
输入时,有一个初始的文件夹(--dense_folder),存放了两个文件夹cams,images 和一个pair.txt.(图8以scan10为例)
其中images文件夹,包含了49张照片,是放置畸变校正之后RGB图像的地方, cams中也包含了49个.txt文件,每一个txt文件就是对应序号图片的相机内参数和外参数. 第三个pair.txt 保存了,当每一个照片为参考影像时, 与其最相似的前十张相片(具体的排序方式是:在稀疏重建过程中, 两张相片共视的三维点数, 共视的三维点越多,则排名越高.)
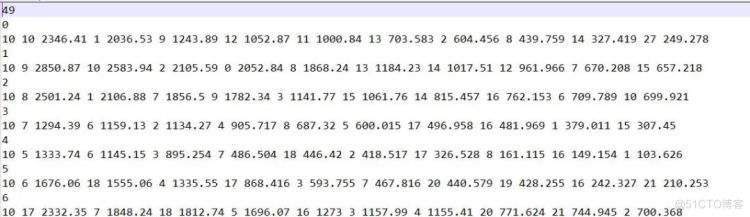
图11 pair.txt文件
逐行解释如下:

10 选取排名较高的前十张影像 10号 得分 2346.41分 1号, 得分2036.53 9号 得分1243.89。所以,对于0号影像来说,筛选前5个类似影像为10号,1号,9号,12号,11号,从数据集找出对应的RGB图片可观察筛选情况(图12)。

图12 0号(ref) 10号 1号 9号 12号 11号 影像
如果将MVSNet暂时看成黑箱, 那么输入到MVSNet的input文件夹,结构一定要遵从上述结构(图8)。
2) Output
在深度估计结束后, 会在dense_folder下新建一个depths_mvsnet, 里面包含了生成的深度图,点云生成后,还有一个文件夹points_mvsnet,里面包含场景的三维点云。

图13 output文件夹结构
4.3 利用自采数据进行深度估计
将MVSNet看做一个黑箱, 需要将自采数据整理成4-1中dense_folder的文件夹结构,即需要每一个包含经过畸变矫正的RGB图片的images文件夹、包含每一个相片的内外参数的cams文件夹,和一个pair.txt文件。
一般的自采数据,可获得RGB图片,所以,需要再利用稀疏重建的原理获得相机的内外参数和相关中间输出。这里提供了一个完整的数据处理pipeline,第一,先利用COLMAP进行稀疏重建,第二,导出相机文件和稀疏场景的信息,第三利用Yaoyao提供的python代码,将COLMAP结果直接转换为MVSNet的输入格式。具体步骤如下:
1) 稀疏重建
利用COLMAP进行稀疏重建,根据上一篇文章, 稀疏重建结束后,可得到了如下的场景。
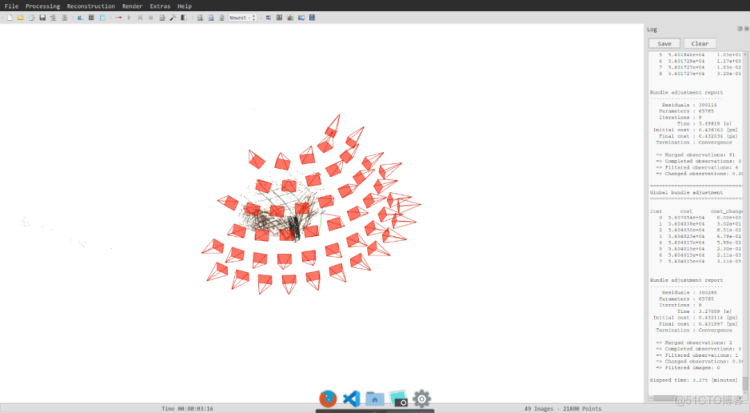
图14 稀疏重建结果
2) 图像纠正
点击“reconstruction” 中的“dense reconstruction”. 打开稠密重建窗口,进行图像畸变纠正。选择dense_folder为worksapce地址,点击“undistortion”进行图像去畸变。(原理这里不再赘述)
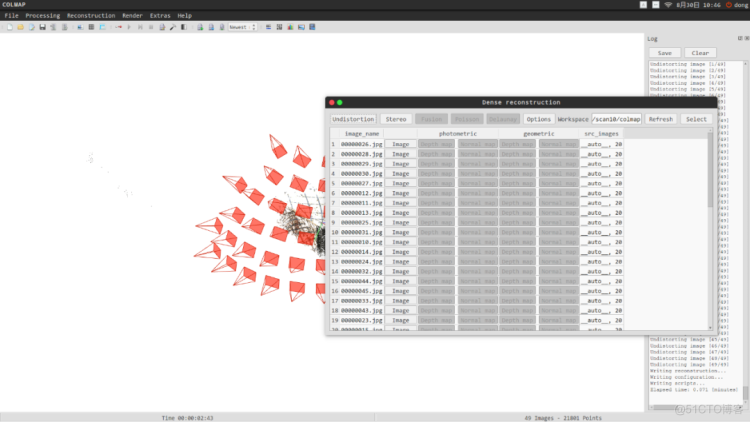
图15 图像纠正窗口
再返回到dense_folder下,可以看到当前的文件夹结构(图16)。这里的sparse是自动创建的保存相机数据和稀疏场景结构的文件夹。
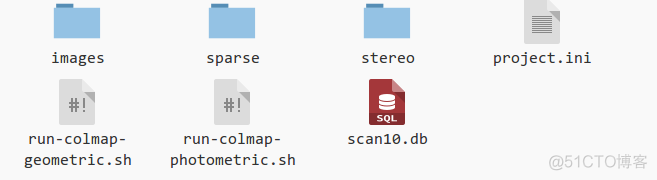
图16 纠正之后的文件结构
3) 导出相机参数和中间数据
点击COLMAP中“file”的 “export data as TXT”, 并以2)中的sparse/文件夹作为导出地址,导出三个文件:camera.txt, images.txt, points3D.txt.
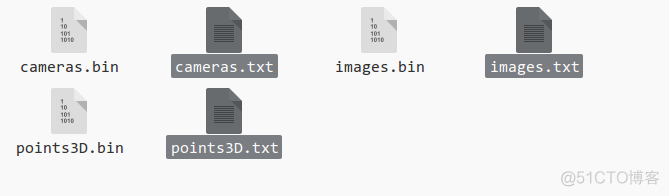
图17 相机数据和中间数据(选中部分)
- camera.txt是保存相机内参数的文件
- images.txt是保存图片外参数和图片二维特征与三维空间点对应信息的文件
- points3D.txt是保存三维空间点在世界坐标系下坐标、RGB值以及在各个影像上的轨迹(track)
4) 结果转换
感谢Yaoyao的结果转换代码(colmap2mvsnet.py),可以将COLMAP的结果直接转化成MVSNet输入需要的结果。执行代码为:
- Flag –dense_folder 需要以我们的dense_folder作为地址,里面必须包含sparse文件夹
- --max_d 表示,最大估计的离散深度采样区间数,因为MVSNet是按照平面扫描原理进行深度估计的,所以深度是离散采样的,一般我们设定为192个深度采样区间。
- --interval_scale表示每个深度区间的大小,默认为1.06(mm)。
- 深度估计范围:已知深度最小值depth_min,则深度最大值满足:
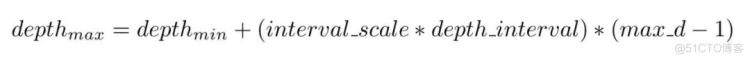
- 注意:我们需要估计自采数据的深度范围,已保证在深度采样区间内,能对目标场景进行有效的深度估计,举个例子,如果自采数据的深度范围为45cm – 80cm,那么我们用于深度估计的区间范围应该是35cm,从45 – 80cm。此时如果我们设定的深度区间为0 – 35cm,那么估计出来的深度图肯定是错误的。所以对于自采数据,大家需要尝试不同的深度区间,以找到合适的取值范围。
- 在估计自采数据的深度范围时,需要修改Yaoyao的代码,需要的朋友们可以私戳笔者,获取修改之后的代码。
5) 深度估计
转换结束后,将dense_folder中的取出cams,images两个文件夹和pair.txt文件,放入一个新的文件夹中,该文件夹就可以作为MVSNet的输入。然后,参考4-1节即可利用自采数据进行深度估计和稠密重建。


图18 自采数据运行结果
原图,深度图,稠密点云
6) 流程回顾
利用自己采集的数据进行深度估计的步骤为:采集数据 -> 稀疏重建 -> COLMAP文件导出 -> 数据转换 -> 输入MVSNet -> 输出深度图 -> 深度融合,恢复点云。
5. 总结
MVSNet是一种端到端的基于监督学习的深度估计网络,从2018年提出伊始,就作为一种比较流行的深度学习框架,其提出的深度代价匹配和构造方法能快速对MVS数据进行参考影像的深度估计,其精度相比较传统方法也有一定的提升。
可是,其在正则化过程中仍旧消耗近11GB的内存,这使得许多人在使用MVSNet的时候受到限制,下一篇文章,将讲述如何利用循环神经网络和一种链式的Cost Volume构造方法减少MVSNet的GPU消耗,敬请期待。
参考文献
[1] Yao Yao, Luo Zixin, Li Shiwei, Fang Tian, Quan Long. MVSNet: Depth Inference for Unstructured Multi-View Stereo. European Conference on Computer Vision (ECCV)
[2] Scharstein D , Szeliski R . A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms[J]. International Journal of Computer Vision, 2002, 47(1-3):7-42.
[3] Han, X., Leung, T., Jia, Y., Sukthankar, R., Berg, A.C.: Matchnet: Unifying feature and metric learning for patch-based matching. Computer Vision and Pattern Recognition (CVPR) (2015)
[4] Collins R T . A Space-Sweep Approach to True Multi-Image Matching[C] Computer Vision and Pattern Recognition, 1996. Proceedings CVPR '96, 1996 IEEE Computer Society Conference on. IEEE, 1996.
[5] Yang R , Pollefeys M . Multi-Resolution Real-Time Stereo on Commodity Graphics Hardware[C] 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings. IEEE, 2003.
[6] Furukawa Y , Hernández, Carlos. Multi-View Stereo: A Tutorial[J]. Foundations & Trends in Computer Graphics & Vision, 2015, 9(1-2):1-148.
[7] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) (2015)
附录
开源数据集下载链接:(感谢香港科技大学 姚遥开源的数据集链接)我们需要下载的是用于测试的数据集,在公众号「3D视觉工坊」后台回复「mvsnet」,即可获得下载链接。打开百度云链接时,点击 “mvsnet”,再点击“preprocessed_inputs”,下载其中的“dtu.zip”和“tankandtemples.zip”即可(图18)。
图19 目标目录
本文仅做学术分享,如有侵权,请联系删文。
