快速体验 @Query 的方法
沿⽤我们之前的例⼦,新增⼀个 @Query 的⽅法:
// 通过 query 注解根据 name 查询 user 信息@Query("From User where name=:name")
User findByQuery(@Param("name");
新增⼀个测试方法:
@Testpublic void testQueryAnnotation(){
userRepository.save(User.builder().name("jackxx").email("123456@126.com").sex("man").address("shanghai").build());
User user = userRepository.findByQuery("jackxx");
System.out.println(user);
}
运行结果如下:
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)Hibernate: select user0_.id as id1_0_, user0_.address as address2_0_, user0_.email as email3_0_, user0_.name as name4_0_, user0_.sex as sex5_0_ from user user0_ where user0_.name=?
User(id=1, name=jackxx, email=123456@126.com, sex=man, address=shanghai)
通过上⾯的例⼦可以发现,这次不是通过⽅法名来⽣成查询语法,⽽是 @Query 注解在其中起了作⽤,使 “From User where name=:name” JPQL ⽣效了。那么它的实现原理是什么呢?通过源码来看⼀下。
JpaQueryLookupStrategy 关键源码剖析
我们在之前已经介绍过 QueryLookupStrategy 的策略值有哪些,那么我们来看下源码是如何起作⽤的。
我们先打开 QueryExecutorMethodInterceptor 类,找到如下代码:
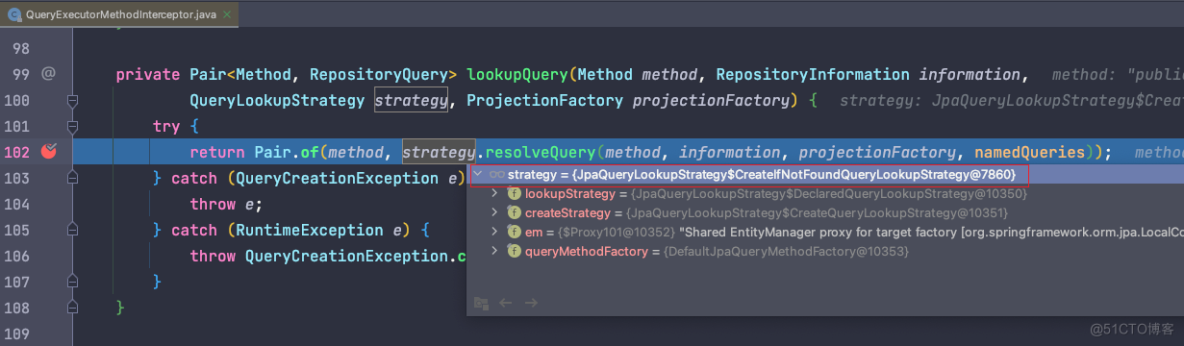
再运⾏上⾯的测试⽤例,这时候在这⾥设置⼀个断点,可以看到默认的策略是 CreateIfNotFoundQueryLookupStrategy,也就是如果有 @Query 注解,那么以 @Query 的注解内容为准,可以忽略⽅法名。
我们继续往后⾯看,进⼊到 org.springframework.data.jpa.repository.query.JpaQueryLookupStrategy.DeclaredQueryLookupStrategy#resolveQuery ⾥⾯,如下所示:
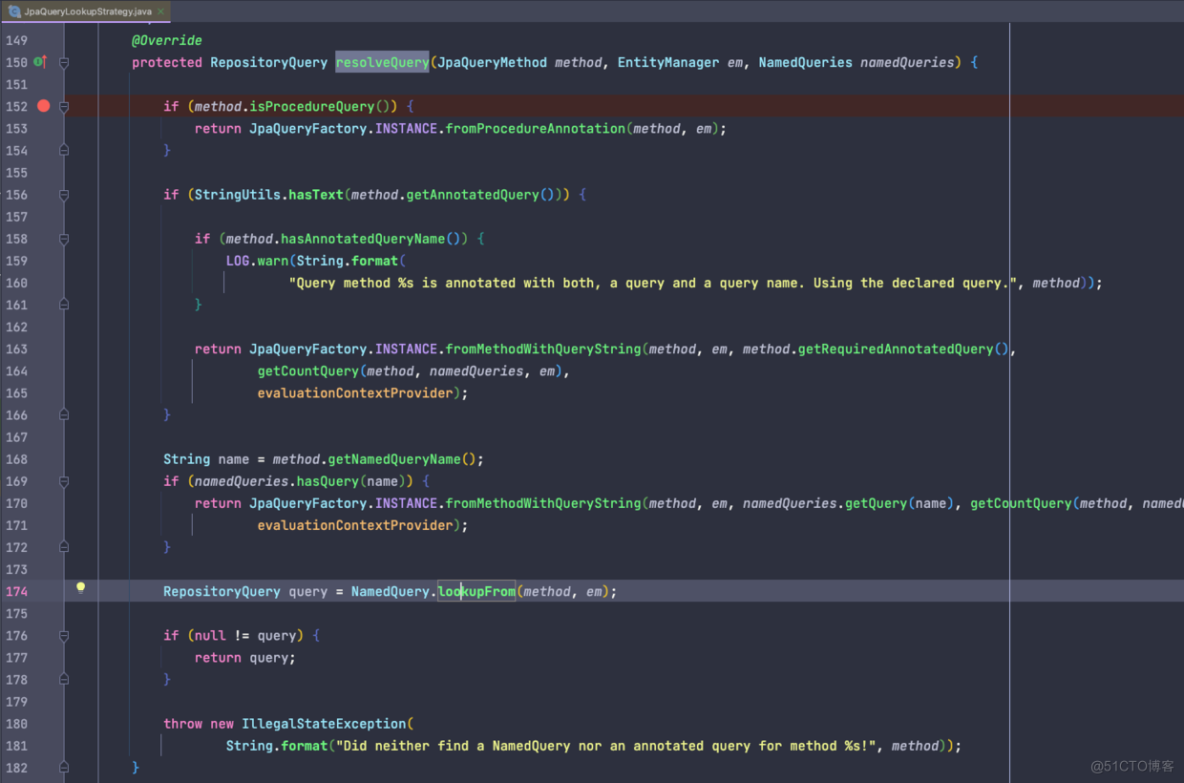
我们可以看到 JPA 的判断顺序
1.先判断是否定义存储过程,有的话优先使用存储过程并返回
2.再判断是否有 Query 注解,如果有的话,再对注解进行处理并返回
3.最后再根据方法名生成 SQL
4.如果都没有符合条件的话,就抛出异常
@Query 的基本用法
在讲解它的语法之前,我们看⼀下它的注解源码,了解⼀下基本⽤法。
package org.springframework.data.jpa.repository;public @interface Query {
/**
* 指定 JPQL 的查询语句。
* (nativeQuery=true 的时候,是原⽣的 Sql 语句)
*/
String value() default "";
/**
* 指定 count 的 JPQL 语句,如果不指定将根据 query ⾃动⽣成。
* (如果当 nativeQuery=true 的时候,指的是原⽣的 Sql 语句)
*/
String countQuery() default "";
/**
* 根据哪个字段来 count,⼀般默认即可。
*/
String countProjection() default "";
/**
* 默认是 false,表示 value ⾥⾯是不是原⽣的 sql 语句
*/
boolean nativeQuery() default false;
/**
* 可以指定⼀个 query 的名字,必须唯⼀的。
* 如果不指定,默认的⽣成规则是:
* {$domainClass}.${queryMethodName}
*/
String name() default "";
/*
* 可以指定⼀个 count 的 query 的名字,必须唯⼀的。
* 如果不指定,默认的⽣成规则是:
* {$domainClass}.${queryMethodName}.count
*/
String countName() default "";
}
所以到这⾥你会发现, @Query ⽤法是使⽤ JPQL 为实体创建声明式查询⽅法。我们⼀般只需要关⼼ @Query ⾥⾯的 value 和 nativeQuery、countQuery 的值即可,因为其他的不常⽤。
使⽤声明式 JPQL 查询有个好处,就是启动的时候就知道你的语法正确不正确。那么我们简单介绍⼀下 JPQL 语法。
JPQL 的语法
我们先看⼀下查询的语法结构,代码如下:
SELECT ... FROM ...[WHERE ...]
[GROUP BY ... [HAVING ...]]
[ORDER BY ...]
你会发现它的语法结构有点类似我们 SQL,唯⼀的区别就是 JPQL FROM 后⾯跟的是对象,⽽ SQL ⾥⾯的字段对应的是对象⾥⾯的属性字段。
同理我们看⼀下 update 和 delete 的语法结构:
DELETE FROM ... [WHERE ...]UPDATE ... SET ... [WHERE ...]
其中“…”省略的部分是实体对象名字和实体对象⾥⾯的字段名字,⽽其中类似 SQL ⼀样包含的语法关键字有:SELECT FROM WHERE UPDATE DELETE JOIN OUTER INNER LEFT GROUP BY HAVING FETCH DISTINCT OBJECT NULL TRUE FALSE NOT AND OR BETWEEN LIKE IN AS UNKNOWN EMPTY MEMBER OF IS AVG MAX MIN SUM COUNT ORDER BY ASC DESC MOD UPPER LOWER TRIM POSITION CHARACTER_LENGTH CHAR_LENGTH BIT_LENGTH CURRENT_TIME CURRENT_DATE CURRENT_TIMESTAMP NEW EXISTS ALL ANY SOME。
@Query 的用法案例
我们通过⼏个案例来了解⼀下 @Query 的⽤法,你就可以知道 @Query 怎么使⽤、怎么传递参数、怎么分⻚等。
案例 1: 要在 Repository 的查询⽅法上声明⼀个注解,这⾥就是 @Query 注解标注的地⽅。
@Query("select u from User u where u.emailAddress = ?1")User findByEmailAddress(String emailAddress);
案例 2: LIKE 查询,注意 firstname 不会⾃动加上“%”关键字。
@Query("select u from User u where u.firstname like %?1")List<User> findByFirstnameEndsWith(String firstname);
案例 3: 直接⽤原始 SQL,nativeQuery = true 即可。
@Query(value = "SELECT * FROM USERS WHERE EMAIL_ADDRESS = ?1", nativeQuery = true)User findByEmailAddress(String emailAddress);
注意:nativeQuery 不⽀持直接 Sort 的参数查询。
案例 4: 下⾯是 nativeQuery 的排序错误的写法,会导致⽆法启动。
@Query(value = "select * from user_info where first_name=?1",nativeQuery = true)List<UserInfoEntity> findByFirstName(String firstName, Sort sort);
案例 5: nativeQuery 排序的正确写法。
@Query(value = "select * from user_info where first_name=?1 order by ?2",nativeQuery = true)List<UserInfoEntity> findByFirstName(String firstName, String sort);
// 调⽤的地⽅写法 last_name 是数据⾥⾯的字段名,不是对象的字段名
repository.findByFirstName("jackzhang","last_name");
通过上⾯⼏个案例,我们看到了 @Query 的⼏种⽤法,你就会明⽩排序、参数、使⽤⽅法、LIKE、原始 SQL 怎么写。下⾯继续通过案例来看下 @Query 的排序。
@Query 的排序
@Query 中在⽤ JPQL 的时候,想要实现排序,⽅法上直接⽤ PageRequest 或者 Sort 参数都可以做到。
在排序实例中,实际使⽤的属性需要与实体模型⾥⾯的字段相匹配,这意味着它们需要解析为查询中使⽤的属性或别名。我们看⼀下例⼦,这是⼀个 state_field_path_expression JPQL 的定义,并且 Sort 的对象⽀持⼀些特定的函数。
案例 6: Sort and JpaSort 的使⽤,它可以进⾏排序。
@Query("select u from User u where u.lastname like ?1%")List<User> findByAndSort(String lastname, Sort sort);
@Query("select u.id, LENGTH(u.firstname) as fn_len from User u where u.lastname like ?1%")
List<Object[]> findByAsArrayAndSort(String lastname, Sort sort);
//调⽤⽅的写法,如下:
repo.findByAndSort("lannister", new Sort("firstname"));
repo.findByAndSort("stark", new Sort("LENGTH(firstname)"));
repo.findByAndSort("targaryen", JpaSort.unsafe("LENGTH(firstname)"));
repo.findByAsArrayAndSort("bolton", new Sort("fn_len"));
上⾯这个案例讲述的是排序⽤法,再来看下 @Query 的分⻚⽤法。
@Query 的分页
@Query 的分⻚分为两种情况,分别为 JPQL 的排序和 nativeQuery 的排序。看下⾯的案例。
案例 7:直接⽤ Page 对象接受接⼝,参数直接⽤ Pageable 的实现类即可。
@Query(value = "select u from User u where u.lastname = ?1")Page<User> findByLastname(String lastname, Pageable pageable);
//调⽤者的写法
repository.findByFirstName("jackzhang", new PageRequest(1,10));
案例 8:@Query 对原⽣ SQL 的分⻚⽀持,并不是特别友好,因为这种写法⽐较“骇客”,可能随着版本的不同会有所变化。我们以 MySQL 为例。
@Query(value = "select * from user_info where first_name=?1 /* #pageable# */",countQuery = "select count(*) from user_info where first_name=?1",
nativeQuery = true)
Page<UserInfoEntity> findByFirstName(String firstName, Pageable pageable);
//调⽤者的写法
userRepository.findByFirstName("jackzhang",new PageRequest(1, 10, Sort.Direction.DESC,"last_name"));
打印出来的 sql:
select * from user_info where first_name=? /* #pageable# */ order by last_name desc limit ?, ?注意:这个注释 / #pageable# / 必须有。
另外,随着版本的变化,这个⽅法有可能会进⾏优化。此外还有⼀种实现⽅法,就是⾃⼰写两个查询⽅法,⾃⼰⼿动分⻚。
关于 @Query 的⽤法,还有⼀个需要了解的内容,就是 @ Param ⽤法。
@Param 的用法
@Param 注解指定⽅法参数的具体名称,通过绑定的参数名字指定查询条件,这样不需要关⼼参数的顺序。我⽐较推荐这种做法,因为它⽐较利于代码重构。如果不⽤ @Param 也是可以的,参数是有序的,这使得查询⽅法对参数位置的重构容易出错。我们看个案例。
案例 9:根据 firstname 和 lastname 参数查询 user 对象。
@Query("select u from User u where u.firstname = :firstname or u.lastname = :lastname")User findByLastnameOrFirstname(@Param("lastname") String lastname, @Param("firstname") String firstname);
案例 10: 根据参数进⾏查询,top 10 前⾯说的“query method”关键字照样有⽤,如下所示:
@Query("select u from User u where u.firstname = :firstname or u.lastname =:lastname")User findTop10ByLastnameOrFirstname(@Param("lastname") String lastname, @Param("firstname") String firstname);
这⾥说下我的经验之谈:你在通过 @Query 定义⾃⼰的查询⽅法时,我建议也⽤ Spring Data JPA 的 name query 的命名⽅法,这样下来⻛格就⽐较统⼀了。
上⾯我介绍了 @Query 的基本⽤法,下⾯介绍⼀下 @Query 在我们的实际应⽤中最受欢迎的两处场景。
@Query 之 Projections 应用返回指定 DTO
利用 UserDto 类
我们在之前的例⼦的基础上新增⼀张表 UserExtend,⾥⾯包含身份证、学号、年龄等信息,最终我们的实体变成如下模样:
@Entity@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class UserExtend { //⽤户扩展信息表
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Long userId;
private String idCard;
private Integer ages;
private String studentNumber;
}
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User { //⽤户基本信息表
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
@Version
private Long version;
private String sex;
private String address;
}
如果我们想定义⼀个 DTO 对象,⾥⾯只要 name、email、idCard,这个时候我们怎么办呢?这种场景⾮常常⻅,但好多⼈使⽤的都不是最佳实践,我在这⾥介绍⼏种⽅式做⼀下对⽐。
我们先看⼀下,刚学 JPA 的时候别⼿别脚的写法:
/*** 查询⽤户表⾥⾯的name、email和UserExtend表⾥⾯的idCard
*
* @param id
* @return
*/
@Query("select u.name,u.email,e.idCard from User u,UserExtend e where u.id=e.userId and u.id=:id")
List<Object[]> findByUserId(@Param("id") Long id);
我们通过下⾯的测试⽤例来取上⾯ findByUserId ⽅法返回的数据组结果值,再塞到 DTO ⾥⾯,代码如下:
@Testpublic void testQueryAnnotation() {
// 新增⼀条⽤户数据
userDtoRepository.save(User.builder().name("jack").email("123456@126.com").sex("man").address("shanghai").build());
// 再新增⼀条和⽤户⼀对⼀的UserExtend数据
userExtendRepository.save(UserExtend.builder().userId(1L).idCard("shengfengzhenghao").ages(18).studentNumber("xuehao001").build());
// 查询我们想要的结果
List<Object[]> userArray = userDtoRepository.findByUserId(1L);
System.out.println(String.valueOf(userArray.get(0)[0]) + String.valueOf(userArray.get(0)[1]));
UserDto userDto = UserDto.builder().name(String.valueOf(userArray.get(0)[0])).build();
System.out.println(userDto);
}
其实经验的丰富的“⽼司机”⼀看就知道这肯定不是最佳实践,这多麻烦呀,肯定会有更优解。那么我们再对此稍加改造,⽤ UserDto 接收返回结果。
⾸先,我们新建⼀个 UserDto 类的内容。
@Data@Builder
@AllArgsConstructor
public class UserDto {
private String name,email,idCard;
}
其次,我们看下利⽤ @Query 在 Repository ⾥⾯怎么写。
public interface UserDtoRepository extends JpaRepository<User, Long> {@Query("select new com.example.jpa.example1.UserDto(CONCAT(u.name,'JK123'),u.email,e.idCard) from User u,UserExtend e where u.id= e.userId and u.id=:id")
UserDto findByUserDtoId(@Param("id");
}
我们利⽤ JPQL,new 了⼀个 UserDto;再通过构造⽅法,接收查询结果。其中你会发现,我们⽤ CONCAT 的关键字做了⼀个字符串拼接,这时有的同学就会问了,这种⽅法⽀持的关键字有哪些呢?
你可以查看JPQL的 Oracal ⽂档,也可以通过源码来看⽀持的关键字有哪些。
⾸先,我们打开 ParameterizedFunctionExpression 会发现 Hibernate ⽀持的关键字有这么多,都是 MySQL 数据库的查询关键字,这⾥就不⼀⼀解释了。
然后,我们写⼀个测试⽅法,调⽤上⾯的⽅法测试⼀下。
@Testpublic void testQueryAnnotationDto(){
userDtoRepository.save(User.builder().name("jack").email("123456@126.com").sex("man").address("shanghai").build());
userExtendRepository.save(UserExtend.builder().userId(1L).idCard("shengfengzhenghao").ages(18).studentNumber("xuehao001").build());
UserDto userDto = userDtoRepository.findByUserDtoId(1L);
System.out.println(userDto);
}
那么还有更简单的⽅法吗?答案是有,下⾯我们利⽤ UserDto 接⼝来实现⼀下。
利用 UserDto 接口
⾸先,新增⼀个 UserSimpleDto 接⼝来得到我们想要的 name、email、idCard 信息。
public interface UserSimpleDto {String getName();
String getEmail();
String getIdCard();
}
其次,在 UserDtoRepository ⾥⾯新增⼀个⽅法,返回结果是 UserSimpleDto 接⼝。
// 利⽤接⼝ DTO 获得返回结果,需要注意的是每个字段需要 as 和接⼝⾥⾯的 get ⽅法名字保持⼀样@Query("select CONCAT(u.name,'JK123') as name,UPPER(u.email) as email,e.idCard as idCard from User u,UserExtend e where u.id= e.userId and u.id=:id")
UserSimpleDto findByUserSimpleDtoId(@Param("id");
然后,测试⽤例写法如下。
@Testpublic void testQueryAnnotationDto(){
userDtoRepository.save(User.builder().name("jack").email("123456@126.com").sex("man").address("shanghai").build());
userExtendRepository.save(UserExtend.builder().userId(1L).idCard("shengfengzhenghao").ages(18).studentNumber("xuehao001").build());
UserSimpleDto userDto = userDtoRepository.findByUserSimpleDtoId(1L);
System.out.println(userDto);
System.out.println(userDto.getName()+":"+userDto.getEmail()+":"+userDto.getIdCard());
}
我们发现,⽐起 DTO 我们不需要 new 了,并且接⼝只能读,那么我们返回的结果 DTO 的职责就更单⼀了,只⽤来查询。
接⼝的⽅式是我⽐较推荐的做法,因为它是只读的,对构造⽅法没有要求,返回的实际是 HashMap。
返回结果介绍完了,那么我们来看下⼀个最常⻅的问题:如何⽤ @Query 注解实现动态查询?
@Query 动态查询解决方法
我们看⼀个例⼦,来了解⼀下如何实现 @Query 的动态参数查询。
⾸先,新增⼀个 UserOnlyName 接⼝,只查询 User ⾥⾯的 name 和 email 字段。
//获得返回结果public interface UserOnlyName {
String getName();
String getEmail();
}
其次,在我们的 UserDtoRepository ⾥⾯新增两个⽅法:⼀个是利⽤ JPQL 实现动态查询,⼀个是利⽤原始 SQL 实现动态查询。
/*** 利⽤JQPl动态查询⽤户信息
*/
@Query("select u.name as name,u.email as email from User u where (:name is null or u.name=:name) and(:email is null or u.email=:email)")
UserOnlyName findByUser(@Param("name") String name, @Param("email");
/**
* 利⽤原始sql动态查询⽤户信息
*/
@Query(value = "select u.name as name, u.email as email " +
"from user u " +
"where (:#{#user.name} is null or u.name = :#{#user.name}) " +
" and (:#{#user.email} is null or u.email =:# {#user.email})",
nativeQuery = true)
UserOnlyName findByUser(@Param("user");
然后,我们新增⼀个测试类,测试⼀下上⾯⽅法的结果。
@Testpublic void testQueryDinamicDto(){
userDtoRepository.save(User.builder().name("jack").email("123456@126.com").sex("man").address("shanghai").build());
UserOnlyName userDto = userDtoRepository.findByUser("jack", null);
System.out.println(userDto.getName() + ":" + userDto.getEmail());
UserOnlyName userDto2 =userDtoRepository.findByUser(User.builder().email("123456@126.com").build());
System.out.println(userDto2.getName() + ":" + userDto2.getEmail());
}
通过上⾯的实例可以看得出来,我们采⽤了 :email is null or s.email = :email 这种⽅式来实现动态查询的效果,实际⼯作中也可以演变得很复杂。
本章小结
我们知道定义⽅法名可以获得想要的结果,@Query 注解亦可以获得想要的结果,nativeQuery 也可以获得想要的结果,那么我们该如何做选择呢?
我们一般遵循以下原则:
1.能⽤⽅法名表示的,尽量⽤⽅法名表示,因为这样语义清晰、简单快速,基本上只要编译通过,⼀定不会有问题;
2.能⽤ @Query ⾥⾯的 JPQL 表示的,就⽤ JPQL,这样与 SQL ⽆关,万⼀哪天换数据库了,基本上代码不⽤改变;
3.最后实在没有办法了,可以选择 nativeQuery 写原始 SQL。
好的架构师写代码时报错的顺序是:编译 < 启动 < 运⾏,即越早发现错误越好。