聊聊Spring Boot 应用启动优化
随着业务发展,线上业务jar 包越来越大,动不动就几百兆,启动时间也越来越慢,严重影响效率。目前大部分java项目都是使用SpringBoot,这篇文章就来简单聊聊关于SpringBoot应用启动优化。
对于一个“历史悠久”的项目,业务代码自然是指数增长,而且在日常业务开发中,我们我都是在做加法,很少会去做删代码之类的操作。另外一般项目都会有很多中间件的初始化,比如:数据连接、redis连接、mq生产者和消费者注册、dubbo生产者和消费者注册、定时任务等;对于各种中间件的初始化,大部分都会在开源工具上封装一层,所以这里就不细说了。这篇主要从业务代码如何后置处理,以及bean加载两方面来简单聊聊启动优化。
启动时间分析
优化前要做的自然是分析启动过程,要分析启动过程,首先想到的应该是日志,将日志级别调为debug,然后分析日志。当然我们也可以借助第三方工具,比如:Async Profiler、JProfiler等。idea现在已经集成了Async Profiler,选择Run *** with Async Profiler启动项目,启动完成之后点击停止便可生成火焰图。

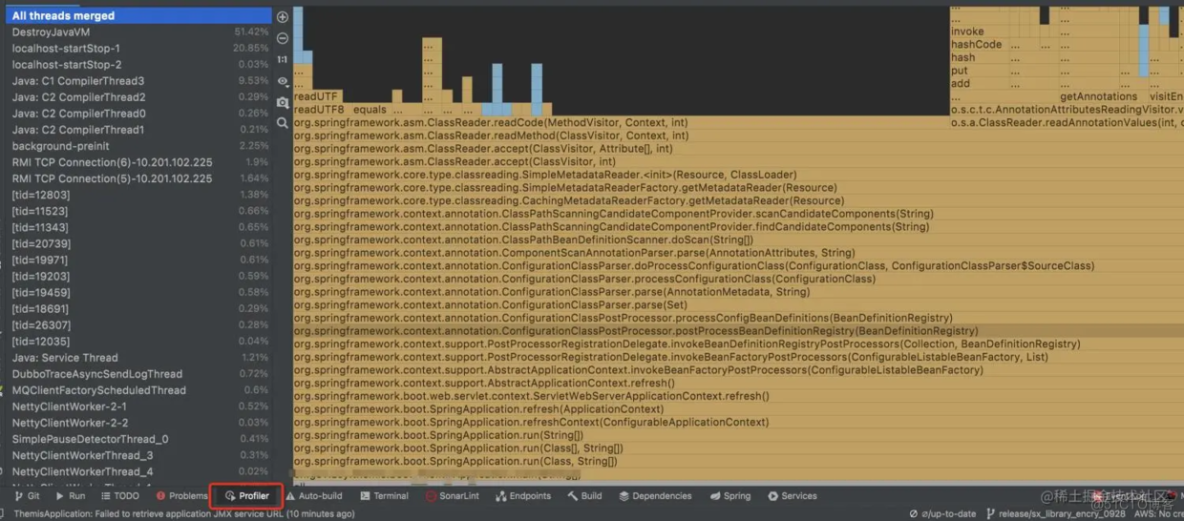
- 火焰图分析
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。 x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
启动优化
业务代码优化
大部分的耗时应该都在业务太大或者蕴含大量的初始化逻辑,比方数据库连接、Redis连接、各种连接池等等,对于业务方的倡议则是尽量减少不必要的依赖,能异步则异步。
启动时业务代码调整
很多业务场景需要在启动时预加载预处理数据等,我们经常都是使用@PostConstruct注解来实现。被这个注解修饰的方法会在该类中所有注入操作完成之后执行,并且是在main线程执行,如果执行时间过长,会导致启动阻塞。 [图片上传失败...(image-f9a690-1666662868502)]
类似加载数据到缓存这种,也可以在接口第一次调用时,将数据加载到缓存。也可以在项目启动完成后执行相应的方法,SpringBoot提供了两种启动完成执行的接口,分别是ApplicationRunner和CommandLineRunner,这两个接口都有一个run()方法,实现该方法,并使用@Component注解使其成为bean。如果存在多个实现这两个接口的类,为了使他们按一定顺序执行,可以使用@Order注解或实现Ordered接口。
加载优化
在Spring中提供了Bean后置处理器BeanPostProcessor,BeanPostProcessor提供了两个方法:
- postProcessBeforeInitialization:每一个bean对象的初始化方法调用之前回调
- postProcessAfterInitialization:每个bean对象的初始化方法调用之后被回调
@Component
public class BeanInitMetrics implements BeanPostProcessor, CommandLineRunner {
private Map<String, Long> stats = new HashMap<>();
private List<Metric> metrics = new ArrayList<>();
@Override
public void run(String... args) throws Exception {
/**
* 启动完成之后打印时间
*/
List<Metric> metrics = getMetrics();
log.info(JSON.toJSONString(metrics));
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
stats.put(beanName, System.currentTimeMillis());
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Long start = stats.get(beanName);
if (start != null) {
metrics.add(new Metric(beanName, Math.toIntExact(System.currentTimeMillis() - start)));
}
return bean;
}
public List<Metric> getMetrics() {
metrics.sort((o1, o2) -> {
try {
return o2.getValue() - o1.getValue();
}catch (Exception e){
return 0;
}
});
log.info("metrics {}", JSON.toJSONString(metrics));
return UnmodifiableList.unmodifiableList(metrics);
}
@Data
public static class Metric{
public Metric(String name, Integer value) {
this.name = name;
this.value = value;
this.createDate = new Date();
}
private String name;
private Integer value;
private Date createDate;
}
}
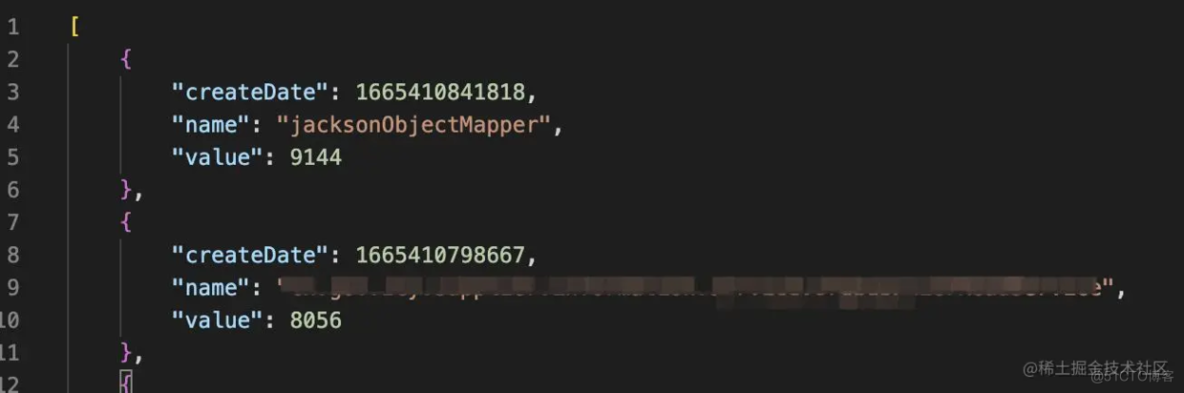
value即为bean初始化所花时间,单位为毫秒,根据启动时间排序后便能知道那些bean初始化耗时大,然后处理相应的bean即可。
spring-contex-index
随着业务发展,项目越来越大,Spring扫描的类也越来越多,启动速度自然也会越来越慢,Spring从5开始提供了spring-context-indexer,可以通过在编译时创建候选对象的静态列表来提高大型应用程序的启动性能。 官方介绍:

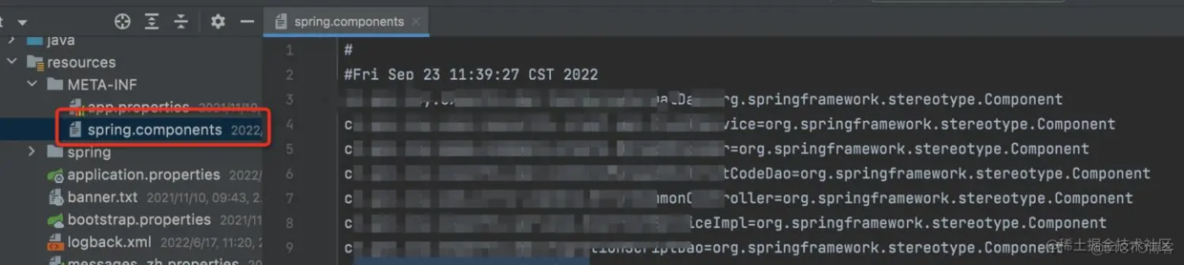
在项目中使用了@Indexed之后,编译打包的时候会在项目中自动生成META-INT/spring.components文件。当Spring应用上下文执行ComponentScan扫描时,META-INT/spring.components将会被CandidateComponentsIndexLoader读取并加载,转换为CandidateComponentsIndex对象,这样的话@ComponentScan不在扫描指定的package,而是读取CandidateComponentsIndex对象,从而达到提升性能的目的。 引入依赖,在启动类上使用@Indexed注解修饰即可
<dependency><groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<optional>true</optional>
</dependency>
需要注意是使用该模式之后,需要依赖的所有模块都使用此模式,不然会出现找不到bean的情况。假设应用中存在一个包含META-INT/spring.components资源的a.jar,b.jar仅存在模式注解,那么使用@ComponentScan扫描这两个JAR中的package时,b.jar中的模式注解不会被识别,因此会出现找不到b.jar中的bean的情况。 对于引入的jar中存在bean,且jar中没有使用Indexed模式,可以在项目资源路径创建META-INT/spring.components文件,将jar中的bean手动添加到文件中,编译时不会覆盖手动添加。
延迟加载
SpringBoot2.2开始提供了应用测试级别的延迟加载,将spring.main.lazy-initialization设置为true意味着应用程序中的所有bean将使用延迟初始化。这样做可以大大加快应用启动速度,不过首次访问速度会变慢,所以这种方式在测试预发环境使用比较合适。 除了使用spring.main.lazy-initialization配置设置延迟加载也可以在启动时方法中使用SpringApplication和SpringApplicationBuilder来设置项目为延迟加载
SpringApplication application = new SpringApplication(ExpertsWebApplication.class);application.setLazyInitialization(Boolean.TRUE);
application.run(args);new SpringApplicationBuilder(ExpertsWebApplication.class)
.lazyInitialization(Boolean.TRUE).build(args)
.run();
以上配置方式影响上下文中的所有bean。 如果想为特定bean配置延迟初始化,可以通过@Lazy注解来完成。 官网介绍 [图片上传失败...(image-dd0ca4-1666662868501)]
其他方面优化
- 很多大项目都是经过漫长的迭代才变得越来越庞大,所以及时清理无用代码是非常有必要的;如果有必要,可以拆分服务。
- 在有些项目中,可能会存在分布式定时任务、mq消费等,像定时任务通常会使用elasticjob,而elasticjob是每个定时任务单独初始化,初始化过程会连接zookeeper。一般我们都会选择在项目启动过程去初始化,如果定时任务过多,启动过程自然也就变慢。类似这种情况,可以考虑像业务代码一样放到启动后初始化或者异步初始化。