初识 Spring Data JPA
入职公司(目前已从这家公司离职)后参与的第一个项目,架构师选定的数据库持久层方案就是 Spring Data JPA。在些之前笔者也是一直使用 MyBatis,未曾听说过 Spring Data JPA。使用 Spring Data JPA 之初也是各种不适应,也曾向架构师提过想换成 MyBatis 的想法,不过架构师一句话就劝服了我:“我们的项目要兼容多种主流数据库”。后来事实也确实证明使用 Spring Data JPA 是一个很正确的选择。因为著名的华为事件,公司领导居安思危,要求公司所有项目兼容国产数据库。我们负责的项目在兼容国产数据库的这件事上没费多大力气,不像公司其它项目费了老鼻子劲。
在这之后就对 Spring Data JPA 颇有好感。
Spring Data JPA 简介
Spring Data JPA 是 Spring Data 的一个子项目,通过提供基于 JPA (Java Persistence API)的 Respository 极大地减少了 JPA 作为数据访问方案的代码量。通过 Spring Data JPA 框架,开发者可以省略实现持久层业务逻辑的工作,唯一要做的就是声明持久层的接口,其他都交给 Spring Data JPA 来完成。
Spring Data JPA最顶层的接口是Repository,该接口是所有Repository类的父类。具体代码如下:
@Indexedpublic interface Repository<T, ID> {
}
Repository 接口间的继承关系如下图所示:
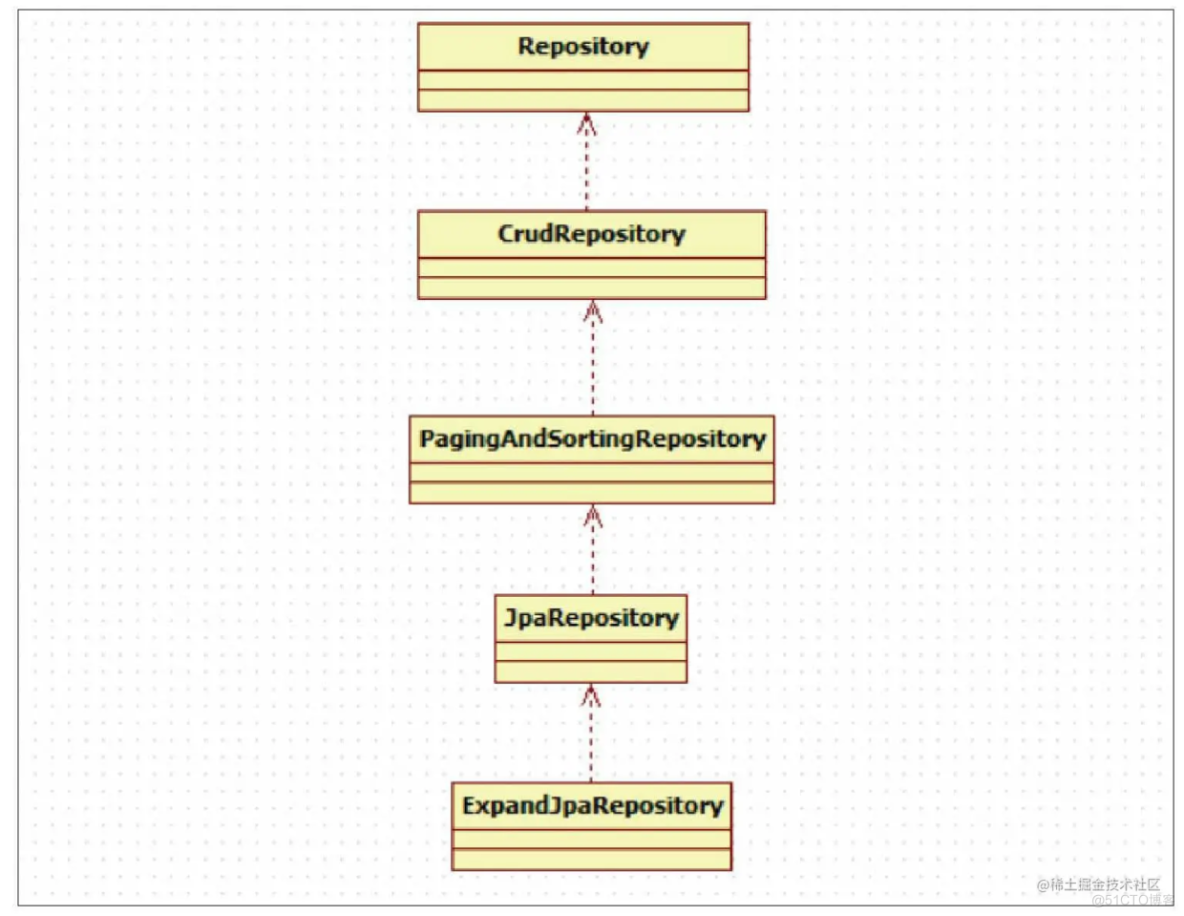
在项目开发中,我们一般都是实现 JapRepository 类。
集成 Spring Data JPA
1、引入 Maven 依赖
在 Spring Boot 项目中使用 Spring Data JPA,首先需要在 pom.xml 文件中引入依赖。
<dependency><groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
2、在 application.properties 中配置数据源信息及 JPA 属性
# 数据库配置spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.h2.console.enabled=true
# 配置JPA相关属性
spring.jpa.show-sql=true
# 设置日期类型属性返回格式
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
spring.jackson.time-zone=GMT+8
笔者这里只是演示 JPA 的使用,所以选择的是 H2 内存数据库。如果你使用的是其它类型的数据库,只需要将数据库配置信息改成对应数据库的配置信息就好。
3、定义 POJO 实体类
/*** 用户
*/
@Data
@Entity
@Table(name = "t_user")
public class User implements Serializable {
/**
* 主键
*/
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
/**
* 用户编号
*/
@Column(name = "user_code")
private String userCode;
/**
* 用户名称
*/
@Column(name = "user_name")
private String userName;
/**
* 创建时间
*/
@Column(name = "create_time")
private Date createTime;
}
实体类使用了@Entity、@Table、@Id等JPA注解修饰。
- @Entity:每个持久化 POJO 类都是一个实体 Bean,通过在类的定义中使用 @Entity 注解来进行声明。
- @Table:声明此对象映射到数据库对应的数据表。
- @Id:指定表的主键。
- @GeneratedValue:用于指定主键生成策略。
- @Column:指定字段在数据表中对应的列名。该注解不是必须,如果没有,默认使用属性名作为列名。
4、定义 Dao 接口
@Repositorypublic interface UserRepository extends JpaRepository<User, Integer> {
List<User> findByUserName(String userName);
}
这样便拥有了系统默认帮我们实现的方法,包括新增、批量保存、查询一个、查询多个、删除等。
另外,我们定义了一个根据用户名查询用户信息的方法。不需要写SQL,也不需要其他代码实现,JPA 会根据方法名自动生成 SQL 来查询数据库。
如果有的方法不想遵循 JPA 的命名规则,可以随便定义方法名,然后在方法上加上 @Query 注解定制查询数据库的 SQL。
@Query("from User where userCode = ?1")List<User> findUserByUserCodeTypeA(String userCode);
@Query("from User where userCode = :usercode")
List<User> findUserByUserCodeTypeB(@Param("usercode") String userCode);
@Query(value = "select * from t_user where user_code = :usercode", nativeQuery = true)
List<User> findUserByUserCodeTypeC(@Param("usercode") String userCode);
注意:上面的方法名只是方便演示,实际的项目中笔者是不会取这种方法名的。这种类型的方法名可以称得上是代码中的坏味道了。好的方法名,见名知义。
动态查询
面对比较复杂的查询的时候,上面的两种实现方式就不是那么优雅了。为了处理动态查询的需求,Spring Data JPA 提供了一个 JpaSpecificationExecutor 接口。JpaSpecificationExecutor 接口包含如下方法:
- long count(@Nullable Specification spec):返回符合条件的记录的数量。
- List findAll(@Nullable Specification spec):返回所有符合条件的记录。
- Page findAll(@Nullable Specification spec, Pageable pageable):返回符合条件的记录,Pageable 参数用于控制排序和分页。
- List findAll(@Nullable Specification spec, Sort sort):返回所有符合条件的记录,Sort 参数用于控制排序。
- Optional findOne(@Nullable Specification spec):返回一条符合条件的记录,如果符合条件的实体有多个,该方法将会引发异常。
概括地讲,一个 Dao 接口要拥有动态查询的能力,就必须继承 JpaSpecificationExecutor 接口。
Spring Data JPA 支持动态查询的关键在于 Specification 参数,Specification 用于封装多个代表查询条件的 Predicate 对象。
Specification 接口定义了一个 toPredicate() 方法,该方法返回的 Predicate 对象就是 Criteria 查询的查询条件,程序通常使用 Lambda 表达式实现 toPredicate() 方法来定义动态查询条件。
CriteriaBuilder是 JPA Criteria 查询的核心API,它的作用就是用于生成各种查询条件。
下面我们通过一个具体的实例来讲述下 JPA 动态查询的使用方法。
修改与 User 实体对应的 Dao 接口,继承 JpaSpecificationExecutor 接口。
@Repositorypublic interface UserRepository extends JpaRepository<User, Integer>,
JpaSpecificationExecutor<User> {
// ...
}
动态查询用户数据:
List<User> userList = userRepository.findAll(((root, criteriaQuery, criteriaBuilder) -> {// 定义集合,用于存放动态查询条件
List<Predicate> predicateList = Lists.newArrayList();
predicateList.add(criteriaBuilder.like(root.get("userCode").as(String.class), "%0%"));
predicateList.add(criteriaBuilder.like(root.get("userName").as(String.class), "%汪%"));
return criteriaBuilder.and(predicateList.toArray(new Predicate[predicateList.size()]));
}));
userList.forEach(System.out::println);
上面的代码,通过 Java 8 的箭头函数,我们生成了一个包含多个查询条件的 Predicate 对象。当然,上面的代码只是为了演示动态查询的功能。实际项目中通常会将生成查询条件的方法封装成工具类。