ModelScope之NLP:基于ModelScope框架的afqmc数据集利用StructBERT预训练模型的文本相似度算法实现文本分类任务图文教程之详细攻略
目录
基于ModelScope框架的afqmc数据集利用StructBERT预训练模型的文本相似度算法实现文本分类任务图文教程
建立在线环境
打开在线Notebook—Jupyterlab
基于PAI-DSW在Jupyterlab内建模
案例设计思路
1、载入数据集
2、数据预处理
3、模型训练与评估
训练
评估
完整代码
官方文档:
https://www.modelscope.cn/docs/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8Notebook%E8%BF%90%E8%A1%8C%E6%A8%A1%E5%9E%8B
基于ModelScope框架的afqmc数据集利用StructBERT预训练模型的文本相似度算法实现文本分类任务图文教程
建立在线环境
基于PAI-DSW在Jupyterlab内建模地址:https://dsw-gateway-cn-hangzhou.data.aliyun.com/dsw-14046/lab/workspaces/auto-a/tree/NLP_test20221016.ipynb
打开在线Notebook—Jupyterlab
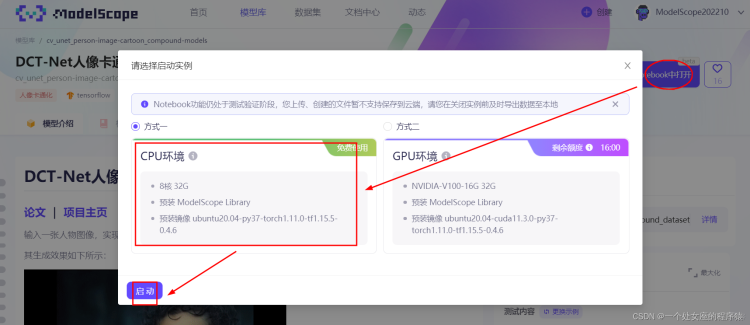
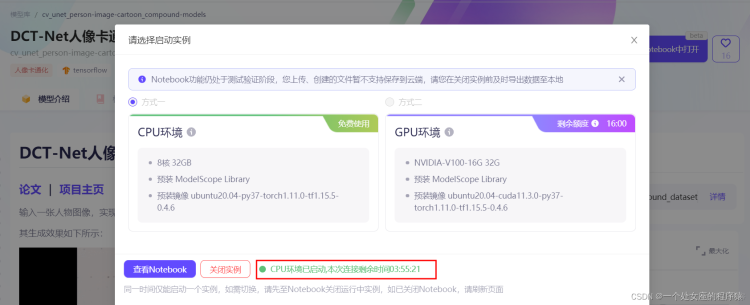
打开CPU实例通常需要2-5分钟,打开GPU实例通常需要8-10分钟,请耐心等待
基于PAI-DSW在Jupyterlab内建模
第一次运行,需要加载相关的库和数据集
案例设计思路
1、载入数据集
afqmc(Ant Financial Question Matching Corpus)数据集
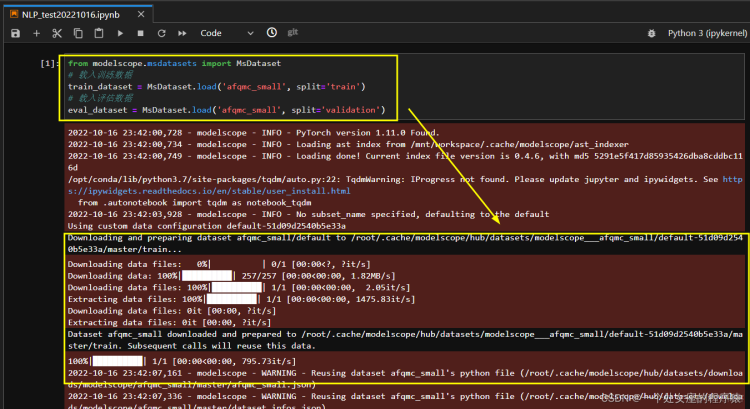
2、数据预处理
在ModelScope中,数据预处理与模型强相关,因此,在指定模型以后,ModelScope框架会自动从对应的modelcard中读取配置文件中的preprocessor关键字,自动完成预处理的实例化。
3、模型训练与评估
训练
根据参数实例化trainer对象,最后,调用train接口进行训练
/opt/conda/lib/python3.7/site-packages/transformers/modeling_utils.py:736: FutureWarning: The `device` argument is deprecated and will be removed in v5 of Transformers."The `device` argument is deprecated and will be removed in v5 of Transformers.", FutureWarning
2022-10-16 23:43:35,985 - modelscope - INFO - epoch [1][1/1] lr: 1.000e-03, eta: 0:02:25, iter_time: 16.119, data_load_time: 2.028, loss: 0.0859
Total test samples: 100%|██████████| 3/3 [00:01<00:00, 1.58it/s]
2022-10-16 23:43:37,994 - modelscope - INFO - Saving checkpoint at 1 epoch
2022-10-16 23:43:38,568 - modelscope - INFO - epoch(eval) [1][1] accuracy: 1.0000
2022-10-16 23:44:04,388 - modelscope - INFO - epoch [2][1/1] lr: 5.500e-03, eta: 0:02:47, iter_time: 25.817, data_load_time: 2.032, loss: 0.0985
Total test samples: 100%|██████████| 3/3 [00:01<00:00, 1.60it/s]
2022-10-16 23:44:06,398 - modelscope - INFO - Saving checkpoint at 2 epoch
2022-10-16 23:44:06,971 - modelscope - INFO - epoch(eval) [2][1] accuracy: 1.0000
2022-10-16 23:44:40,386 - modelscope - INFO - epoch [3][1/1] lr: 1.000e-03, eta: 0:02:55, iter_time: 33.411, data_load_time: 2.034, loss: 0.0743
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.32it/s]
2022-10-16 23:44:42,802 - modelscope - INFO - Saving checkpoint at 3 epoch
2022-10-16 23:44:43,388 - modelscope - INFO - epoch(eval) [3][1] accuracy: 1.0000
2022-10-16 23:45:21,681 - modelscope - INFO - epoch [4][1/1] lr: 1.000e-03, eta: 0:02:50, iter_time: 38.290, data_load_time: 2.035, loss: 0.0754
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.13it/s]
2022-10-16 23:45:24,400 - modelscope - INFO - Saving checkpoint at 4 epoch
2022-10-16 23:45:24,988 - modelscope - INFO - epoch(eval) [4][1] accuracy: 1.0000
2022-10-16 23:46:01,486 - modelscope - INFO - epoch [5][1/1] lr: 1.000e-04, eta: 0:02:30, iter_time: 36.494, data_load_time: 2.035, loss: 0.0687
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.04it/s]
2022-10-16 23:46:04,510 - modelscope - INFO - Saving checkpoint at 5 epoch
2022-10-16 23:46:05,140 - modelscope - INFO - epoch(eval) [5][1] accuracy: 1.0000
2022-10-16 23:46:42,186 - modelscope - INFO - epoch [6][1/1] lr: 1.000e-04, eta: 0:02:04, iter_time: 37.042, data_load_time: 2.036, loss: 0.0656
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.26it/s]
2022-10-16 23:46:44,707 - modelscope - INFO - Saving checkpoint at 6 epoch
2022-10-16 23:46:45,311 - modelscope - INFO - epoch(eval) [6][1] accuracy: 1.0000
2022-10-16 23:47:22,378 - modelscope - INFO - epoch [7][1/1] lr: 1.000e-05, eta: 0:01:36, iter_time: 37.063, data_load_time: 2.037, loss: 0.0669
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.08it/s]
2022-10-16 23:47:25,202 - modelscope - INFO - Saving checkpoint at 7 epoch
2022-10-16 23:47:25,785 - modelscope - INFO - epoch(eval) [7][1] accuracy: 1.0000
2022-10-16 23:48:03,174 - modelscope - INFO - epoch [8][1/1] lr: 1.000e-05, eta: 0:01:05, iter_time: 37.297, data_load_time: 2.037, loss: 0.0723
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.01it/s]
2022-10-16 23:48:06,203 - modelscope - INFO - Saving checkpoint at 8 epoch
2022-10-16 23:48:06,807 - modelscope - INFO - epoch(eval) [8][1] accuracy: 1.0000
2022-10-16 23:48:43,083 - modelscope - INFO - epoch [9][1/1] lr: 1.000e-06, eta: 0:00:33, iter_time: 36.272, data_load_time: 2.039, loss: 0.0750
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.11it/s]
2022-10-16 23:48:45,899 - modelscope - INFO - Saving checkpoint at 9 epoch
2022-10-16 23:48:46,486 - modelscope - INFO - epoch(eval) [9][1] accuracy: 1.0000
2022-10-16 23:49:24,087 - modelscope - INFO - epoch [10][1/1] lr: 1.000e-06, eta: 0:00:00, iter_time: 37.598, data_load_time: 2.036, loss: 0.0705
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.32it/s]
2022-10-16 23:49:26,500 - modelscope - INFO - Saving checkpoint at 10 epoch
2022-10-16 23:49:27,696 - modelscope - INFO - epoch(eval) [10][1] accuracy: 1.0000
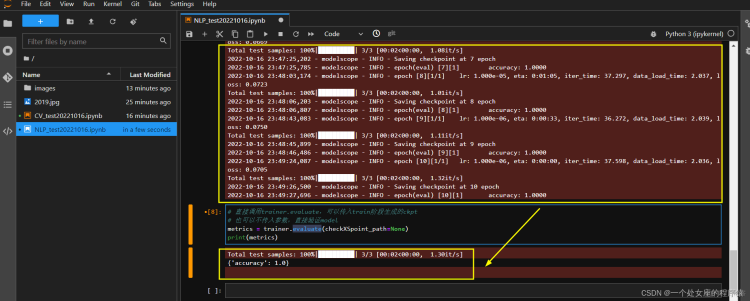
评估
训练完成以后,配置评估数据集,直接调用trainer对象的evaluate函数,即可完成模型的评估。
Total test samples: 100%|██████████| 3/3 [00:02<00:00, 1.30it/s]{'accuracy': 1.0}
完整代码
from modelscope.msdatasets import MsDataset# 载入训练数据
train_dataset = MsDataset.load('afqmc_small', split='train')
# 载入评估数据
eval_dataset = MsDataset.load('afqmc_small', split='validation')
# 指定文本分类模型
model_id = 'damo/nlp_structbert_sentence-similarity_chinese-base'
from modelscope.trainers import build_trainer
# 指定工作目录
tmp_dir = "/tmp"
# 配置参数
kwargs = dict(
model=model_id,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
work_dir=tmp_dir)
trainer = build_trainer(default_args=kwargs)
trainer.train()
# 直接调用trainer.evaluate,可以传入train阶段生成的ckpt
# 也可以不传入参数,直接验证model
metrics = trainer.evaluate(checkXSpoint_path=None)
print(metrics)