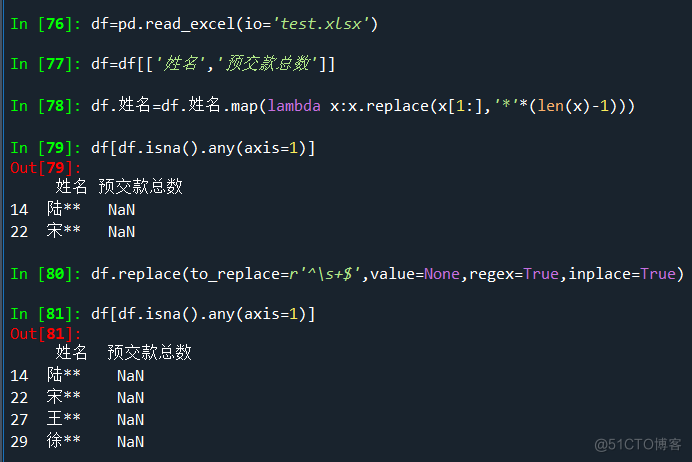
数据清洗过程中,得到excel或csv形式的数据后,通常需要进行清理。假设初步获得的dataframe是df。 1、找出NaN值所在的行 df[df.isna().any(axis=1)],可获得含有NaN的行。 但是,有时在原始exc
数据清洗过程中,得到excel或csv形式的数据后,通常需要进行清理。假设初步获得的dataframe是df。
1、找出NaN值所在的行
df[df.isna().any(axis=1)],可获得含有NaN的行。
但是,有时在原始excel或csv中,如果单元格的值是空白字符,Tab字符等空白字符时,上面的办法无法进一步将这些行筛选出来。
2、找出NaN值与其它空白字符所在的行
(1)df.replace(to_replace=r'^\s+$',value=None,regex=True,inplace=True)
(2)df[df.isna().any(axis=1)]