前言
最近在处理游戏敏感词之类的东西,为了加强屏蔽处理,所以需要过滤掉字符串中的除汉字之外的是其他东西如数字,符号,英文字母等。
首先我查阅资料并写了个函数:
示例:返回输入字符串中汉字的个数:
std::string StrWithOutSymbol(const std::string &source)
{
string sourceWithOutSymbol;
int i = 0;
while (source[i] != 0)
{
if (source[i] & 0x80 )
{
sourceWithOutSymbol += source[i];
sourceWithOutSymbol += source[i + 1];
i += 2;
else
{
i ++;
}
}
return
sourceWithOutSymbol;
}
这个函数的原理是ord($str)&0x80来判断汉字
80对应的二进制代码为1000 0000,最高位为一,代表汉字汉字编码格式通称为10格式一个汉字占2字节,但只代表一个字符
"Windows中,中文简体字符集的编码是同时用1个字节和2个字节来表示的。当高位是0x00~0x7f时,为一个字节,高位为0x80以上时用2个字节表示"
当你发现一个字节的内容大于0x7f,那它肯定是个(跟另外一个字节拼凑成一个)汉字,如何判断肯定大于0x7f呢?
0x7f(1111111)后面一个数就是0x80(10000000),所以想要大于0x7f,这个字节的最高位都肯定是1,我们只需要判断这个最高位是否为1就行了。
判断方法:
位与(相同的位都是1的才为1,否则为0):
如:要判断一个数的第三位是否是1,只要跟4(100)位与,判断一个数的第2位是否为1就跟2(10)位与.
同理判断第八位是否为1只要跟(10000000)也就是0x80位与了.
这里为什么不用>0x7f?php可能还行,但在其他强类型语言里面,1个字节的最高位用来标示负数,一个负数肯定不可能大于0x7f(最大的整数)
再举个例子:
a的assic码是97(1100001)
A的assic码是65(1000001)b的assic码是98(1100010)
B的assic码是66(1000010)
发现一个规律:一个a-z的字母,只要是小写字母,第六位肯定是1,我们可以用这个来判断大小写:
这时候只要跟用以个字母跟0x20(100000)来位与判断:
if(ord($a)&0x20){
//大写
}
如何把所有字母改成大写?第六位的1改成0就行了:
$a='a'; $a = chr(ord($a)&(~0x20)); echo $a;
然后我信心满满的吧这个函数加入到项目中去,点击运行,输入中文进行检查,当!项目报错了????数组越界????
这是为什么,我又定位到报错的地方,发现我使用的cocos-lua,在向c++传递字符串的时候传进来的字符串是以UTF-8来进行编码的,我又去找UIF-8的编码规则发现
UTF-8编码规则:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。UTF-8转换表表示如下:
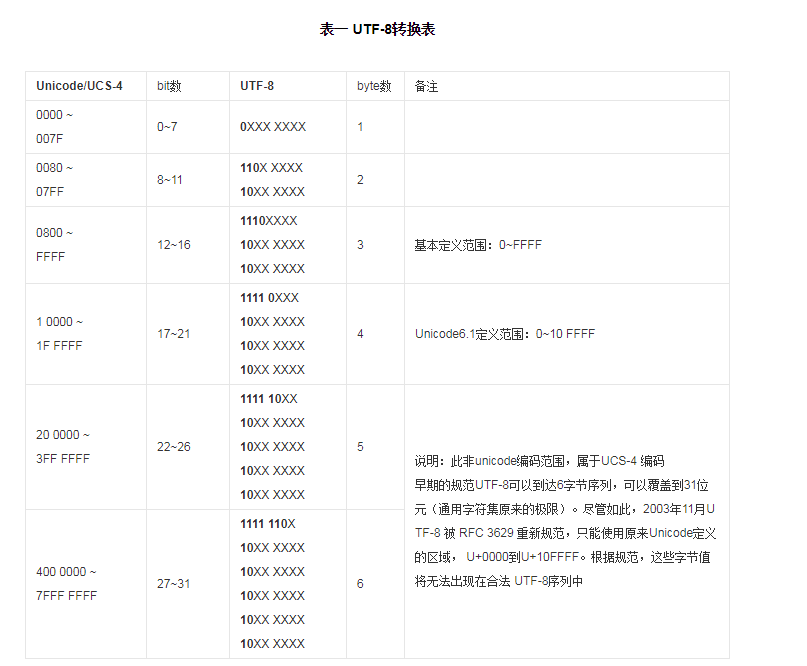
而我之前的是按照GBK编码进行操作的,GBK每个中文字符只占两个字节,而utf-8的话中文可能占3个字节,四个字节,甚至是五个六个,所以用刚才那样的函数就会有越界的情况发生,所以对用UTF-8进行编码的字符串,就需要进行另外的处理,所以我写了一个新函数:
对UTF-8编码的字符串进行中文筛选的函数:
std::string censorStrWithOutSymbol(const std::string &source)
{
string sourceWithOutSymbol;
int i = 0;
while (source[i] != 0)
{
if (source[i] & 0x80 && source[i] & 0x40 && source[i] & 0x20)
{
int byteCount = 0;
if (source[i] & 0x10)
{
byteCount = 4;
}
else
{
byteCount = 3;
}
for (int a = 0; a < byteCount; a++)
{
sourceWithOutSymbol += source[i];
i++;
}
}
else if (source[i] & 0x80 && source[i] & 0x40)
{
i += 2;
}
else
{
i += 1;
}
}
return sourceWithOutSymbol;
}
点击运行,成功了!舒服。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对自由互联的支持。