看似问题简单,好多人搞不懂真正的区别,下面我们从底层的角度给大家分析一下
从C语言的角度来看,所有的文件都可简单的分为两类:一类是文本文件,另外一类是二进制文件。
1、文本文件:
所谓的文本文件,就是按照字符的编码规则(比如ASCII),1:1的根据你敲的字符形成的机器码文件。后缀习惯是以.txt结尾。一个典型的文本编辑器就是大家熟悉的记事本程序(notepad.exe)。
假设我们在记事本程序里面写入了如下的“ABC回车123回车abc”,并且保存为文件名为a.txt文件。如下图所示
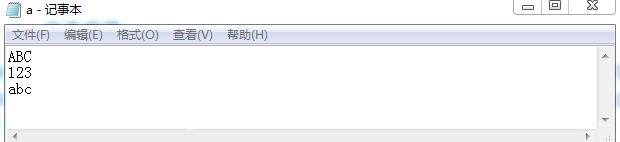
a.txt
我们的问题是,在保存后,计算机究竟保存了什么样的信息?
我们用一个能够查看底层二进制代码的程序打开后,可以看到如下信息

a.txt底层二进制代码
41 42 43 0D 0A 31 32 33 0D 0A 61 62 63 0D 0A(十六进制)
根据ANSI ASII规范表
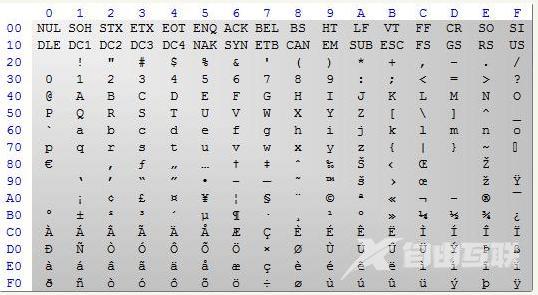
很明显:41->A ,42->B,43->C,换一行的回车,是由两个控制符 0D(CR)和0A(LF) 决定的。其他的字符依次类推。
可见一个标准的ASCII文本文件,就是按照ASCII表的编码规则来进行1:1转换的。当然如果你是按照unicode编码,所有的字符按照两个字节代表一个字符的方式进行编码。在解析Unicode编码的文本文件时,就要按照两个字节为一个字符的方式进行二进制到文本的转换,这样才能正确解析。
有人可能要问,如果一个人用word保存的这些字符,是不是文本文件呢?答案是,不是。因为word文件在保存时,添加了很多的特定的格式化信息。我们以保存一个字符A为例,看看word 2010中的A在保存后,底层究竟是什么样的。下图截取了部分
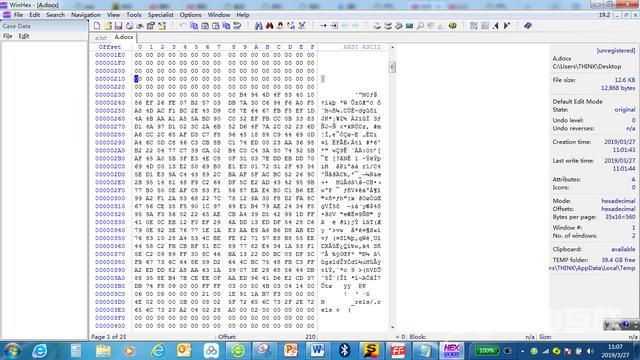
word文件底层代码截图
这只是一部分,可见又一大堆只有微软才了解的代码。
2、二进制文件
二进制文件是可以认为是所有非文本文件都称之为二进制文件。
要打开二进制文件,需要有形成这类文件的程序的内置的解析器,才能解读。这也解释了为什么不同的文件比如pdf,docx等文件,在编程的时候,必须要有相应的文档解析类函数来完成的原因了。
当然你完全可以用二进制方式打开任何一个文本文件,因为底层上就是那些代码,你只需要读取每一个字节,查找转化成相应字符予以显示就可以了,因为是你知道ASCII表的规则。
文本区别二进制文件