目录
- 前言
- 解析Azure官网的演示功能
- 两个参数
- 三次发送
- 接收的二进制消息
- 用Node.js实现它
- 两个参数
- 创建WebSocket连接
- 三次发送
- 接收二进制消息拼接mp3
- 命令行工具
- 在uni-app中使用
- 新建一个云函数
- 下载播放mp3文件
- 方法1. 先上传到云存储,通过云存储地址访问
- 方法2. 利用云函数的URL化+集成响应来访问
- 小结
- 总结
前言
尝试过各种TTS的方案,一番体验下来,发现微软才是这个领域的王者,其Azure文本转语音服务的转换出的语音效果最为自然,但Azure是付费服务,注册操作付费都太麻烦了。但在其官网上竟然提供了一个完全体的演示功能,能够完完整整的体验所有角色语音,说话风格...
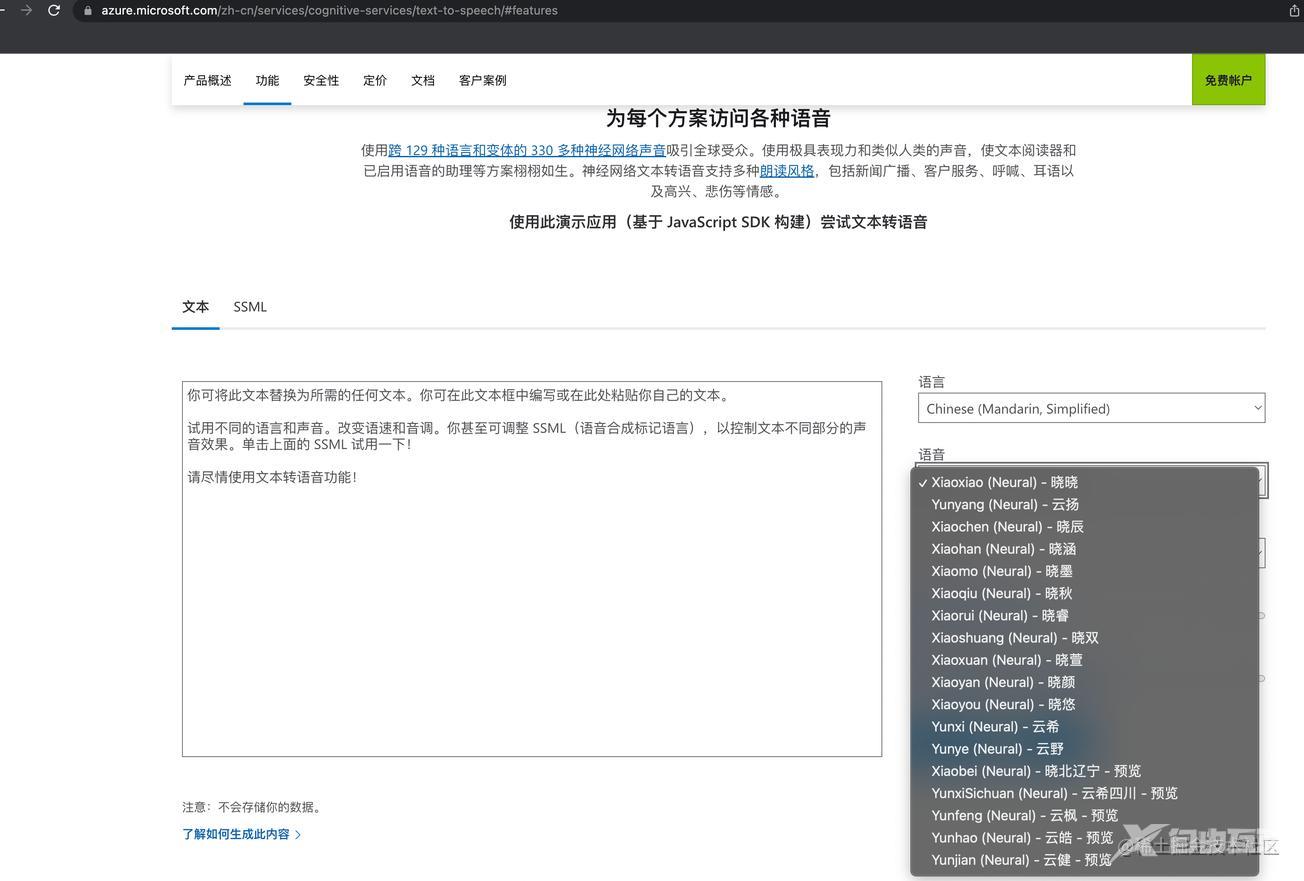
但就是不能下载成mp3文件,所以有一些小伙伴逼不得已只好通过转录电脑的声音来获得音频文件,但这样太麻烦了。其实,能在网页里看到听到的所有资源,都是解密后的结果。也就是说,只要这个声音从网页里播放出来了,我们必然可以找到方法提取到音频文件。
本文就是记录了这整个探索实现的过程,请尽情享用~
本文大部分内容写于今年年初一直按在手里未发布,我深知这个方法一旦公之于众,可能很快会迎来微软的封堵,甚至直接取消网页体验的入口和相关接口。
解析Azure官网的演示功能
使用Chrome浏览器打开调试面板,当我们在Azure官网中点击播放功能时,可以从network标签中监控到一个wss://的请求,这是一个websocket的请求。
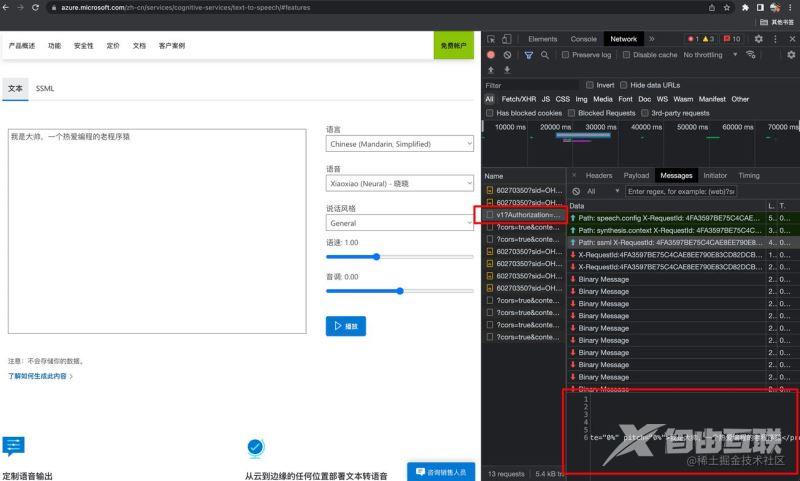
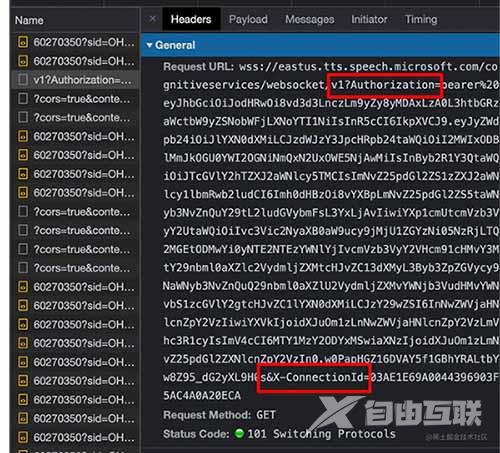
两个参数
在请求的URL中,我们可以看到有两个参数分别是Authorization和X-ConnectionId
有意思的是,第一个参数就在网页的源码里,使用axios对这个Azure文本转语音的网址发起get请求就可以直接提取到
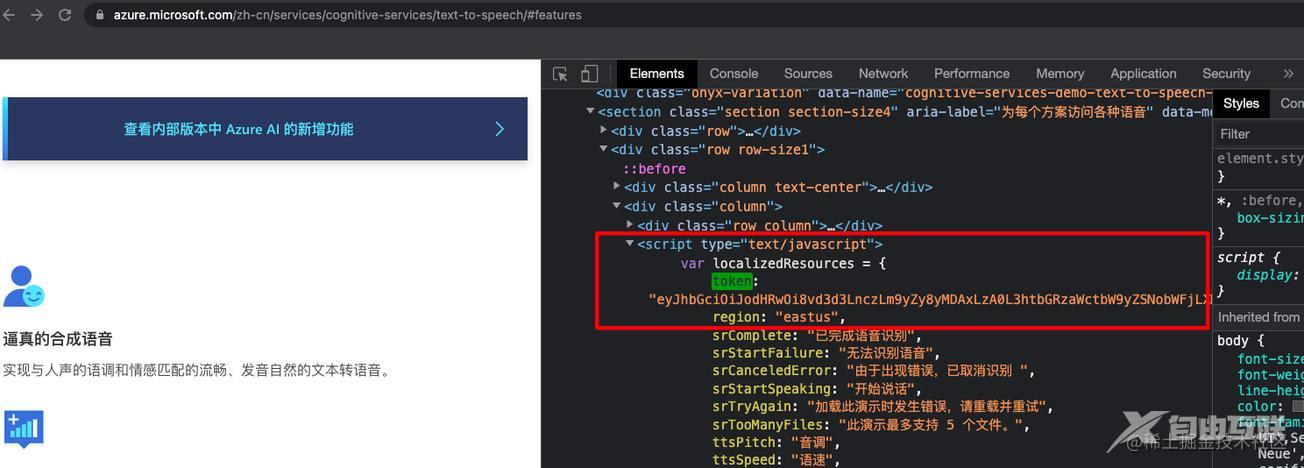
const res = await axios.get("https://azure.microsoft.com/en-gb/services/cognitive-services/text-to-speech/");
const reg = /token: \"(.*?)\"/;
if(reg.test(res.data)){
const token = RegExp.$1;
}
通过查看发起请求的JS调用栈,加入断点后再次点击播放


可以发现第二个参数X-ConnectionId来自一个createNoDashGuid的函数
this.privConnectionId = void 0 !== t ? t : s.createNoDashGuid(),
这就是一个uuid v4格式的字符串,nodash就是没有-的意思。
三次发送
请求时URL里的两个参数已经搞定了,我们继续分析这个webscoket请求,从Message标签中可以看到
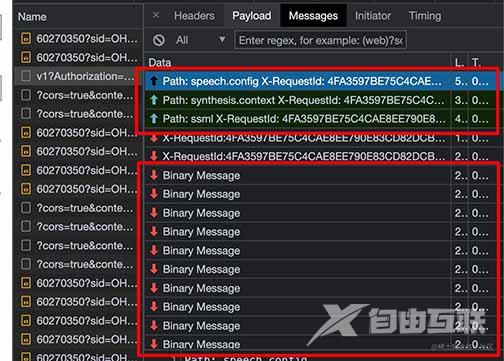
每次点击播放时,都向服务器上报了三次数据,明显可以看出来三次上报数据各自的作用
第一次的数据:SDK版本,系统信息,UserAgent
Path: speech.config
X-RequestId: 818A1E398D8D4303956D180A3761864B
X-Timestamp: 2022-05-27T16:45:02.799Z
Content-Type: application/json
{"context":{"system":{"name":"SpeechSDK","version":"1.19.0","build":"JavaScript","lang":"JavaScript"},"os":{"platform":"Browser/MacIntel","name":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36","version":"5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36"}}}
第二次的数据:转语音输出配置,从outputFormat可以看出来,最终的音频格式为audio-24khz-160kbitrate-mono-mp3,这不就是我们想要的mp3文件吗?!
Path: synthesis.context
X-RequestId: 091963E8C7F342D0A8E79125EA6BB707
X-Timestamp: 2022-05-27T16:48:43.340Z
Content-Type: application/json
{"synthesis":{"audio":{"metadataOptions":{"bookmarkEnabled":false,"sentenceBoundaryEnabled":false,"visemeEnabled":false,"wordBoundaryEnabled":false},"outputFormat":"audio-24khz-160kbitrate-mono-mp3"},"language":{"autoDetection":false}}}
第三次的数据:要转语音的文本信息和角色voice name,语速rate,语调pitch,情感等配置
Path: ssml X-RequestId: 091963E8C7F342D0A8E79125EA6BB707 X-Timestamp: 2022-05-27T16:48:49.594Z Content-Type: application/ssml+xml <speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US"><voice name="zh-CN-XiaoxiaoNeural"><prosody rate="0%" pitch="0%">我叫大帅,一个热爱编程的老程序猿</prosody></voice></speak>
接收的二进制消息
既然从前三次上报的信息已经看出来返回的格式就是mp3文件了,那么我们是不是把所有返回的二进制数据合并就可以拼接成完整的mp3文件了呢?答案是肯定的!
每次点击播放后接收的所有来自websocket的消息的最后一条,都有明确的结束标识符
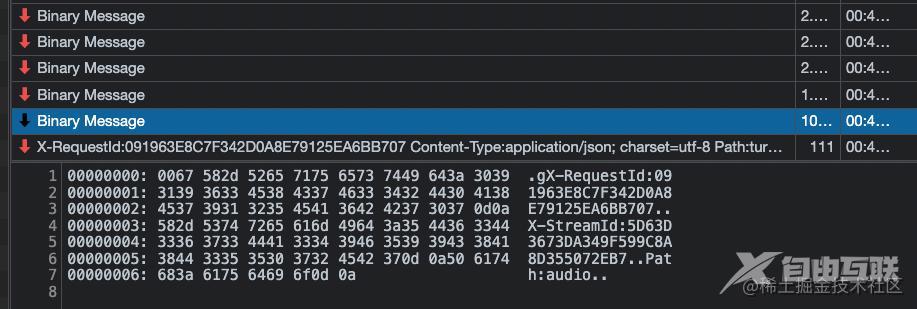

turn.end代表转换结束!
用Node.js实现它
既然都解析出来了,剩下的就是在Node.js中重新实现这个过程。
两个参数
- Authorization,直接通过axios的get请求抓取网页内容后通过正则表达式提取
const res = await axios.get("https://azure.microsoft.com/en-gb/services/cognitive-services/text-to-speech/");
const reg = /token: \"(.*?)\"/;
if(reg.test(res.data)){
const Authorization = RegExp.$1;
}
- X-ConnectionId,直接使用
uuid库即可
//npm install uuid
const { v4: uuidv4 } = require('uuid');
const XConnectionId = uuidv4().toUpperCase();
创建WebSocket连接
//npm install nodejs-websocket
const ws = require("nodejs-websocket");
const url = `wss://eastus.tts.speech.microsoft.com/cognitiveservices/websocket/v1?Authorization=${Authorization}&X-ConnectionId=${XConnectionId}`;
const connect = ws.connect(url);
三次发送
第一次发送
function getXTime(){
return new Date().toISOString();
}
const message_1 = `Path: speech.config\r\nX-RequestId: ${XConnectionId}\r\nX-Timestamp: ${getXTime()}\r\nContent-Type: application/json\r\n\r\n{"context":{"system":{"name":"SpeechSDK","version":"1.19.0","build":"JavaScript","lang":"JavaScript","os":{"platform":"Browser/Linux x86_64","name":"Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0","version":"5.0 (X11)"}}}}`;
connect.send(message_1);
第二次发送
const message_2 = `Path: synthesis.context\r\nX-RequestId: ${XConnectionId}\r\nX-Timestamp: ${getXTime()}\r\nContent-Type: application/json\r\n\r\n{"synthesis":{"audio":{"metadataOptions":{"sentenceBoundaryEnabled":false,"wordBoundaryEnabled":false},"outputFormat":"audio-16khz-32kbitrate-mono-mp3"}}}`;
connect.send(message_2);
第三次发送
const SSML = `
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US">
<voice name="zh-CN-XiaoxiaoNeural">
<mstts:express-as style="general">
<prosody rate="0%" pitch="0%">
我叫大帅,一个热爱编程的老程序猿
</prosody>
</mstts:express-as>
</voice>
</speak>
`
const message_3 = `Path: ssml\r\nX-RequestId: ${XConnectionId}\r\nX-Timestamp: ${getXTime()}\r\nContent-Type: application/ssml+xml\r\n\r\n${SSML}`
connect.send(message_3);
接收二进制消息拼接mp3
当三次发送结束后我们通过connect.on('binary')监听websocket接收的二进制消息。
创建一个空的Buffer对象final_data,然后将每一次接收到的二进制内容拼接到final_data里,一旦监听到普通文本消息中包含Path:turn.end标识时则将final_data写入创建一个mp3文件中。
let final_data=Buffer.alloc(0);
connect.on("text", (data) => {
if(data.indexOf("Path:turn.end")>=0){
fs.writeFileSync("test.mp3",final_data);
connect.close();
}
})
connect.on("binary", function (response) {
let data = Buffer.alloc(0);
response.on("readable", function () {
const newData = response.read()
if (newData)data = Buffer.concat([data, newData], data.length+newData.length);
})
response.on("end", function () {
const index = data.toString().indexOf("Path:audio")+12;
final_data = Buffer.concat([final_data,data.slice(index)]);
})
});
这样我们就成功的保存出了mp3音频文件,连Azure官网都不用打开!
命令行工具
我已经将整个代码打包成一个命令行工具,使用非常简单
npm install -g mstts-js mstts -i 文本转语音 -o ./test.mp3
已全部开源: github.com/ezshine/mst…
在uni-app中使用
新建一个云函数
新建一个云函数,命名为mstts
由于mstss-js已经封装好了,只需要在云函数中npm install mstts-js然后require即可,代码如下
'use strict';
const mstts = require('mstts-js')
exports.main = async (event, context) => {
const res = await mstts.getTTSData('要转换的文本','CN-Yunxi');
//res为buffer格式
});
下载播放mp3文件
要在uniapp中播放这个mp3格式的文件,有两种方法
方法1. 先上传到云存储,通过云存储地址访问
exports.main = async (event, context) => {
const res = await mstts.getTTSData('要转换的文本','CN-Yunxi');
//res为buffer格式
var uploadRes = await uniCloud.uploadFile({
cloudPath: "xxxxx.mp3",
fileContent: res
})
return uploadRes.fileID;
});
前端用法:
uniCloud.callFunction({
name:"mstts",
success:(res)=>{
const aud = uni.createInnerAudioContext();
aud.autoplay = true;
aud.src = res;
aud.play();
}
})
- 优点:云函数安全
- 缺点:文件上传到云存储不做清理机制的话会浪费空间
方法2. 利用云函数的URL化+集成响应来访问
这种方法就是直接将云函数的响应体变成一个mp3文件,直接通过audio.src赋值即可访问`
exports.main = async (event, context) => {
const res = await mstts.getTTSData('要转换的文本','CN-Yunxi');
return {
mpserverlessComposedResponse: true,
isBase64Encoded: true,
statusCode: 200,
headers: {
'Content-Type': 'audio/mp3',
'Content-Disposition':'attachment;filename=\"temp.mp3\"'
},
body: res.toString('base64')
}
};
前端用法:
const aud = uni.createInnerAudioContext(); aud.autoplay = true; aud.src = 'https://ezshine-274162.service.tcloudbase.com/mstts'; aud.play();
- 优点:用起来很简单,无需保存文件到云存储
- 缺点:URL化后的云函数如果没有安全机制,被抓包后可被其他人肆意使用
小结
这么好用的tts库,如果对你有所帮助别忘了在github里点个star支持一下。
总结
到此这篇关于如何在uni-app使用微软的文字转语音服务的文章就介绍到这了,更多相关uni-app文字转语音服务内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!