目录
- 1. Entity Framework的简介
- 2.Code First的使用
- 3.EF的一些坑
- EF的缓存机制
- Attach的使用
- 按需修改
- AsNoTracking的使用
最近公司需要使用EF(Entity Framework)的CodeFirst,虽然之前接触过EF的使用,但是却从来没有使用过CodeFirst,所以便从网上和其他地方学习了一下,所以在此记录一下, 以便以后忘记的时候,可以回顾一下。
1. Entity Framework的简介
Entity Framework是一种数据库的持久化框架,是微软开发的基于ADO.NET的ORM(Object Relational Mapping,对象关系映射)框架
它严格来说是由三种编程方式:
- 第一种是 "DB First",指的是数据库优先,根据数据库取映射实体
- 第二种是“Model First”指的是模型优先,根据模型取生成数据库中的表,
- 第三种是“Code First”指的是代码优先,根据代码去生成数据库中的表,还有另外一种是来自数据库的“Code First”
2.Code First的使用
按照下面的操作安装EF的最新版本
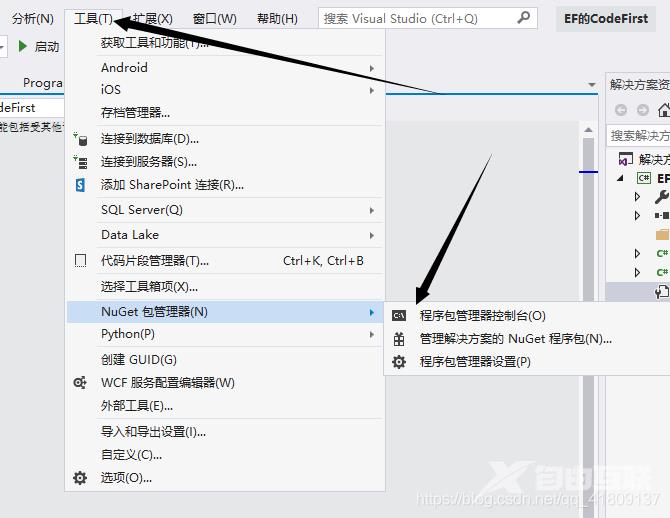
然后输入“install-package entityframework” 命令
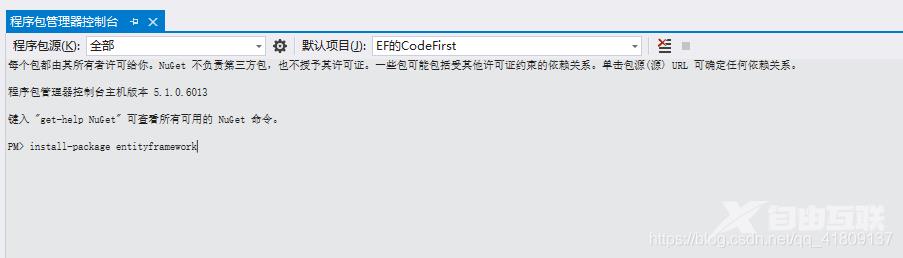
安装成功后,开始写代码
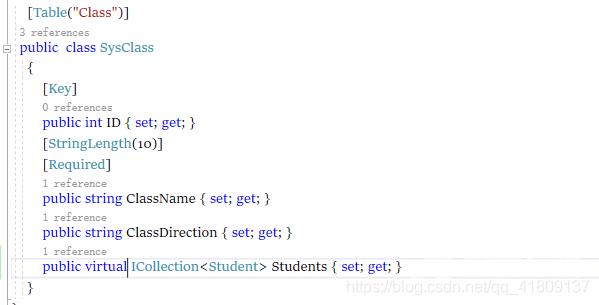
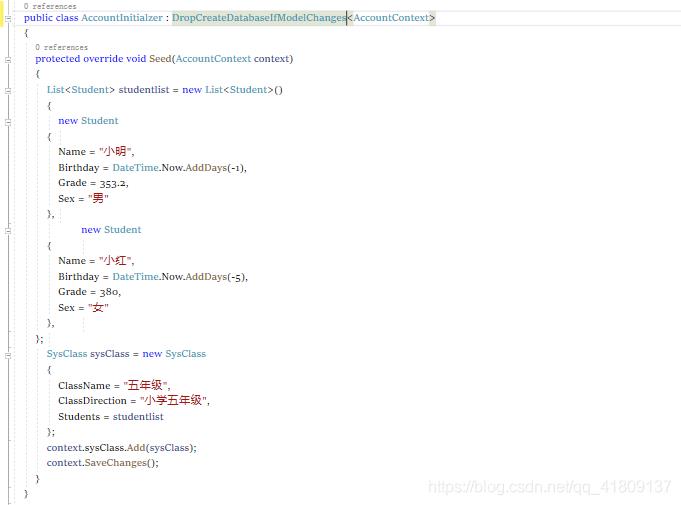
首先我们先新建几个实体类“Student”和“SysClass”,一个学生类一个班级类,因为class
在.net中是保留字,所以我们为班级类起名“SysClass”,但是“Class”在数据库中不是保留字多以我们可以怎样做在“SysClass”类上打上特性**[Table(“Class”)]**,然后在其他字段上添加几个必要的属性,“SysClass”的Students属性上有个virtual,指明这个是外键。

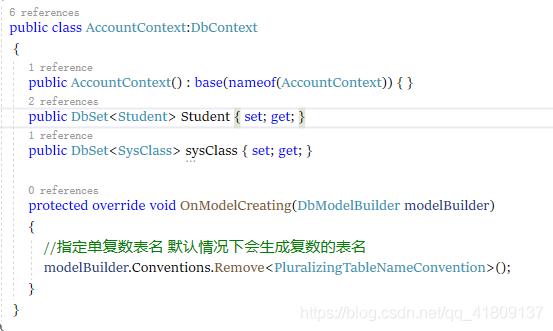
然后再新建一个“AccountContext”类这个类,继承自"DBContext"(System.Data.Entity) 这个类封装了对数据库的一些配置和释放,当然CRUD(增删改查)也可以通过这个类来实现。
实现父类的构造函数,传入的参数是nameof(AccountContext),指明的是使用哪个的数据库的连接串,OnModelCreating()这个方法可以重写也可以不重写,这个方法主要是为了指明是否需要在将代码映射到数据库时,是否生成复数的表名,默认情况下是自动生成复数的表名。
然后在新建一个“AccountInitialzer”类,用来初始化数据库的,他继承自“DropCreateDatabaseIfModelChanges”,表明是当实体改变时,删除数据库中的表,然后在根据代码映射的实体新建数据库中的表,然后重写它的Seed方法,
这个方法是当数据库初始化的时候,插入一些测试的数据,它还有可以继承DropCreateDatabaseAlways,但是这种方法比较狠,每次都会从删除数据库中的表,在根据代码去重新生成数据库,不介意使用,需要注意的是Seek这个方法,不是运行程序都会执行的,他只在第一次创建数据库会被执行,或者当数据库中的表和代码映射的实体不一致时,他也会执行。
最后我们开始配置数据库的连接串 name 指的是数据库连接串的名字 也是我们“AccountContext”的类传入的参数, initial catalog 是创建的数据库的名字,我们这里不指明创建的数据库的位置,当然也可以指明创建的数据库位置,不指明的他会在你数据库的文件夹中创建新的数据库,还有就是 providerName=“System.Data.SqlClient” 这个一定要带上,否则可能会出错。

然后我们在指明我们需要使用的AccountContext 和AccountInitialzer ,向程序指明我们新建创建数据库时,需要使用的类。
注意type里面配置的是程序集的名称,而不是命名空间的名称,还有就是disableDatabaseInitialization这个参数,false是指明启用这个配置,true这是禁用。

然后我们在控制台继续敲代码,这里的Using语法,说明一下我们对DBcontext这个类查看定义发现,这个类是实现了IDisposable接口,这就意味着,它是可以被释放的托管资源,避免内存越占越多,造成的程序性能的较低,同时这也是一个好的编程习惯。
运行程序后,我们发现程序运行正常

我们在检查一下数据库,win+r 输入命令 ssms 打开数据库发现,数据库也被正常创建了,这里说明一下,这里除了生成了我们需要的表以外,还生成了表“dbo__MigrationHistory”,这个表是记录数据库迁移使用的,以后再做说明,每次数据库表结构的更新,都会在这里存下数据。
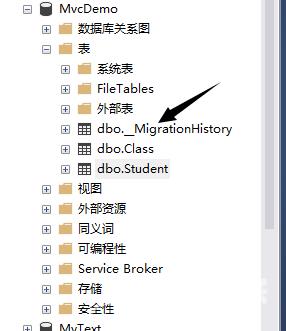
这样我们的Code First就完成了。
3.EF的一些坑
看了上面的文章是不是觉得CodeFirst还是很简单的,通过是用EF 我们甚至不再需要学习数据库的一些知识,甚至可以让我们不再关心数据库内部的实现,只需要我们修改代码,便可以修改掉数据库中的表结构,Code First用的好,我们甚至都不必去打开一次数据库。
但是EF看着好用,其实它内部的坑或者或一些比较让人忽略的东西还是有不少的。
我们重新改造一下控制台的代码,添加 context.Database.Log +=c=> Console.WriteLine©; 这句话会帮我们记录数据的日志。
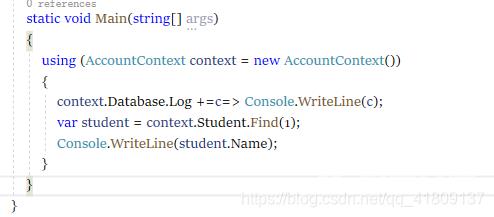
我们执行查询操作 发现控制台多了许多代码,这就是数据库的日志,当然,我们看到的这条sql语句,就是我们执行 var student = context.Student.Find(1); 这句话时,生成的sql语句,是不是用起来很方便,但是我们只需要查询主键是1的数据,他却给我们生成了这么长的一条sql语句,是不是看起来感觉EF其实也笨笨的,所以这就是EF不适合大型项目的原因。
EF的缓存机制
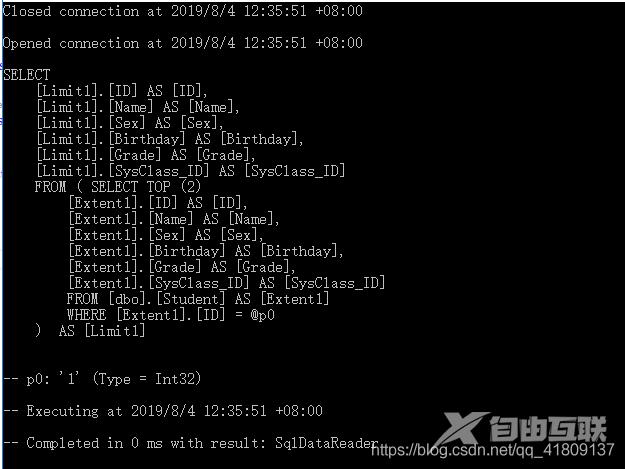
我们输入这样的代码,两次查询主键是1的学生
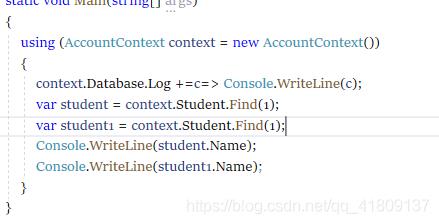
我们查看日志,发现只生成了一条sql。
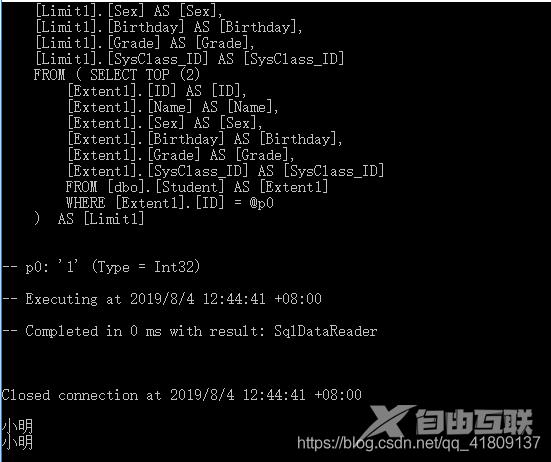
我们再次修改代码,我们都只是查询主键是1的学生,只不过是换了一种方式,我们在查看日志。
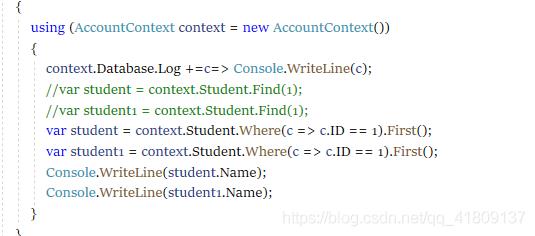
这里我们发现,它生成了两条相同的sql
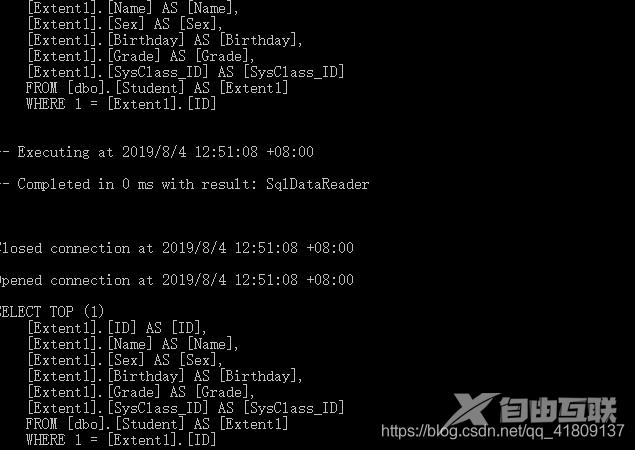
这里我们发现,find会优先去缓存中去查询数据,而where则会每次都会生成新的sql去执行查询,就算查询条件相同,where也会生成新的sql。所以where可以保证我们每次都能取到最新的数据,而find则不行,之所以出现这种情况,我是这么理解的,find查询的数据的每次都只能返回一条,数据量小,不会占用太多的内存,但是where我们发现返回的是IQueryable类型的数据,这样就不能保证返回的数据量小了,因此为了性能的这个就不会放到缓存中去了。
Attach的使用
我们修改一下代码:
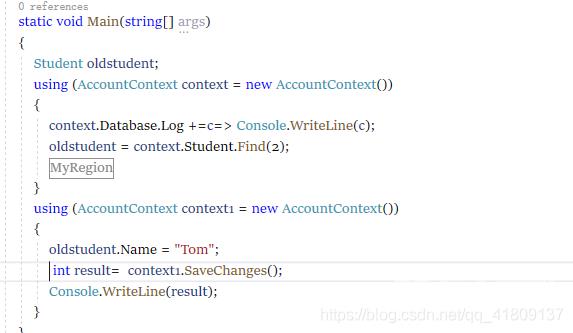
我们先查询一个学生,然后在修改它的Name属性,然后保存,这里result返回的是0,意思是没有执行成功,我们查看数据库发现确实没有修改成功。
这里就要说明一下了,这里我们使用的是两个AccountContext对象,context对象查询出了学生student,context对象便开始监管这个对象,我们用context1这个对象修改是,因为context1这个对象,根本就不知道student是谁,当然会修改失败了。
这样我们在修改一下代码:
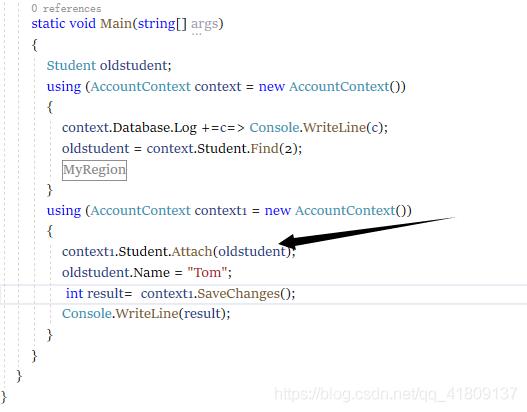
我们发现返回的是1,当在查看数据库时,发现数据库的信息被修改了。
Attach是将查出来的student让context1进行监管,就相当于与这个student对象是被context1查出来的一样,但也是有区别的,所以我们就修改成功了。
需要注意的是如果被修改的对象的属性在Attach之前,会修改失败的,因为那时候,context1还没有对student进行监管。
比如这样,就会修改失败,
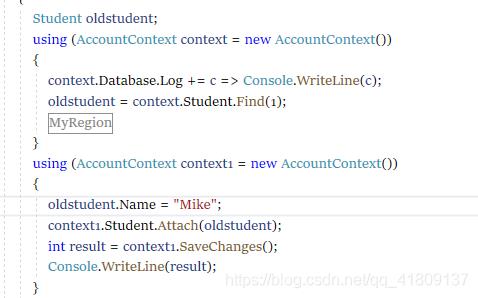
按需修改
EF是支持按需修改的,我们修改代码:
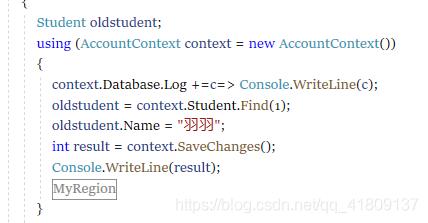
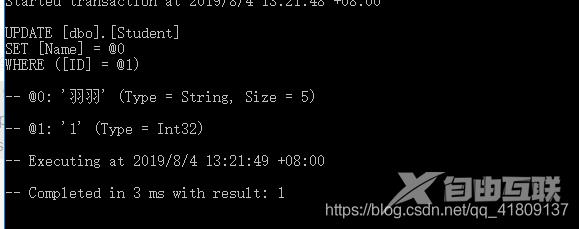
查看日志,发现只修改了Name属性,
AsNoTracking的使用
我们再次修改代码

我们在查询到的数据中添加AsNoTracking()的方法,再次修改实体,发现修改失败了,这里解释一下AsNoTracking()这个方法,他表示不再追踪这条数据,也就是context这个对象不再监管oldstudent这个对象,所以会修改失败的,虽然一定程度上可以提高性能,但是介意不要使用。
好了,本篇文章就到此为止了。以后再介绍EF的其他知识点。以上为个人经验,希望能给大家一个参考,也希望大家多多支持易盾网络。