目录
- 组件说明
- Zipkin
- sleuth
- 基本术语
- Zipkin 数据持久化
组件说明
Zipkin
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以及解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
sleuth
sleuth是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位 。主要体现在,一个请求可能需要调用很多个服务 ,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位 。
基本术语
Span (跨度):基本工作单元,发送一个远程调度任务 就会产生一个 Span , Span 是一个 64 位 ID 唯一标识的, Trace 是用另一个 64 位 ID 唯一标识的, Span 还有其他数据信息,比如摘要、时间戳事件、Span 的 ID 、以及进度 ID 。
Trace (跟踪):一系列 Span 组成的一个树状结构。请求一个微服务系统的 API 接口,这个 API 接口,需要调用多个微服务,调用每个微服务都会产生一个新的 Span ,所有由这个请求产生的 Span 组成了这个 Trace 。
Annotation (标注):用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
cs - Client Sent - 客户端发送一个请求,这个注解描述了这个 Span 的开始
sr - Server Received - 服务端获得请求并准备开始处理它,如果将其 sr 减去 cs 时间戳便可得到网络传输的时间。
ss - Server Sent (服务端发送响应) – 该注解表明请求处理的完成 ( 当请求返回客户端) ,如果 ss 的时间戳减去 sr 时间戳,就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应) - 此时 Span 的结束,如果 cr 的时间戳减去cs 时间戳便可以得到整个请求所消耗的时间
Sleuth配合ZIPKIN的使用
所有服务都加入以下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
使用docker安装zipkin:docker run -d -p 9411:9411 openzipkin/zipkin
所有微服务加入以下配置:
#服务追踪,url填自己的服务器地址 spring.zipkin.base-url=http://192.168.56.10:9411/ #关闭服务发现 spring.zipkin.discovery-client-enabled=false spring.zipkin.sender.type=web #配置采样器 spring.sleuth.sampler.probability=1
启动服务,进行一系列业务操作,再进入配置中输入的url:http://192.168.56.10:9411/
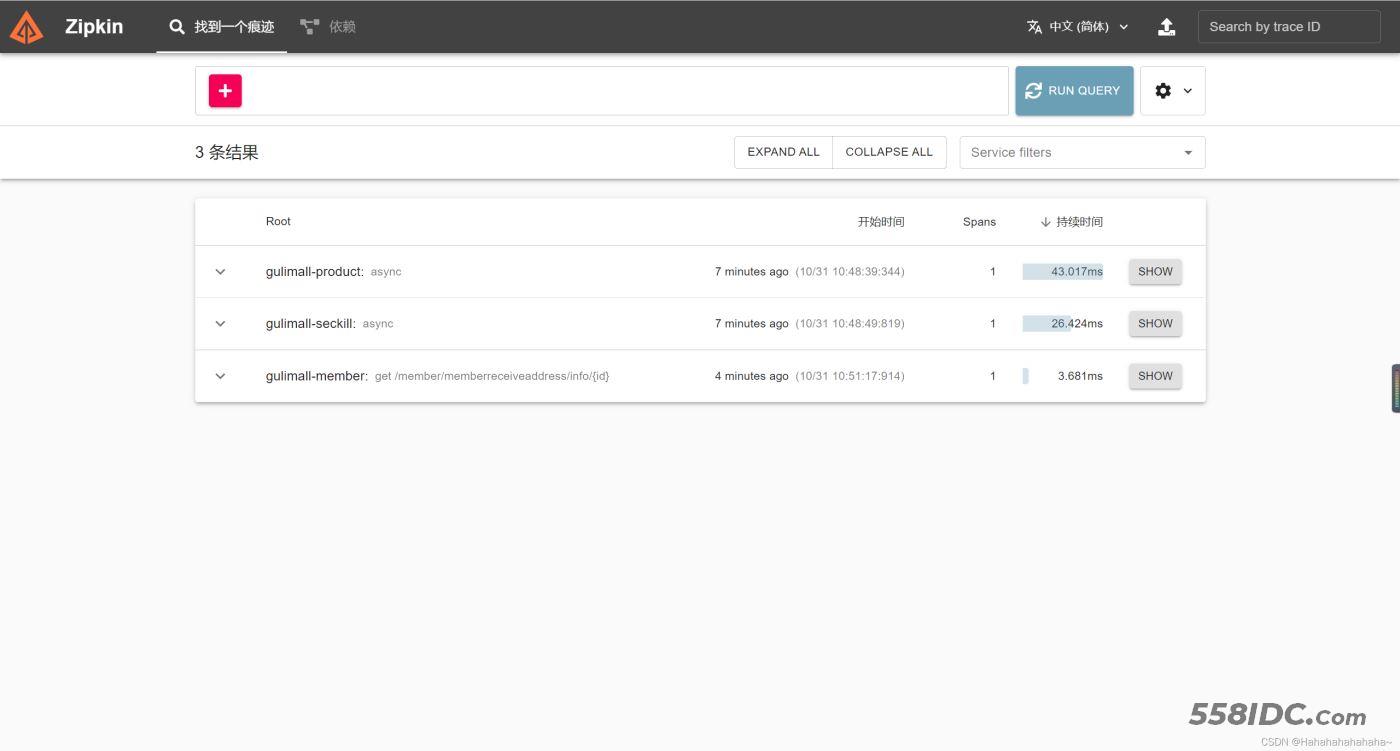
Zipkin 数据持久化
Zipkin 默认是将监控数据存储在内存的,如果 Zipkin 挂掉或重启的话,那么监控数据就会丢 失。所以如果想要搭建生产可用的 Zipkin,就需要实现监控数据的持久化。数据可以存到内存,mysql,elasticsearch和Cassandra中。 Zipkin 支持的这几种存储方式中,内存显然是不适用于生产的。而使用 MySQL 的话,当数据量大时,查询较为缓慢,也不建议使用。 Twitter 官方使用的是 Cassandra作为 Zipkin 的存储数据库,但国内用 Cassandra 的公司较少,而且 Cassandra 相关文档也不多。 综上,故采用 Elasticsearch 是个比较好的选择。 使用docker进行配置(前提已经安装了Elasticsearch): docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200 openzipkin/zipkin-dependencies 附:使用 es 时 Zipkin Dependencies 支持的环境变量

到此这篇关于SpringCloud集成Sleuth和Zipkin的文章就介绍到这了,更多相关SpringCloud集成Sleuth和Zipkin内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!