目录
- 概述
- 线程池介绍
- 线程池创建
- ThreadPoolExecutor创建
- Executors创建
- newFixedThreadPool
- newCachedThreadPool
- newSingleThreadExecutor
- newScheduledThreadPool
- newWorkStealingPool
- 线程池关键API和例子
- 提交执行任务API
- 关闭线程池API
- 线程池监控API
- 扩展API
- 使用注意事项
概述
线程池在平时的工作中出场率非常高,基本大家多多少少都要了解过,可能不是很全面,本文和大家基于jdk8学习下线程池的全面使用,以及分享下使用过程中遇到的一些坑。
线程池介绍
因为线程资源十分宝贵,每次创建和销毁线程的开销都比较大,另一方面,如果创建太多的线程,也会消耗系统大量资源,降低系统吞吐量,甚至导致服务不可用。为了解决这些问题,提出一种基于池化思想管理和使用线程的机制,就是我们的线程池。
线程池的核心思想就是能做到线程的复用,线程池中的线程执行完成不会销毁,而是存留在内存里,等待执行其他的任务。
jdk中的线程池采用的是一种生产者—消费者模型,如下图:
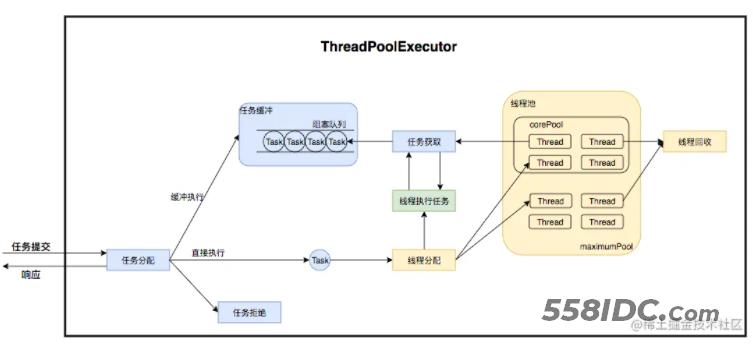
- 外部提交任务到线程池中,如果线程数量小于指定阈值的话,直接创建线程
- 如果提交任务大于阈值,会存到队列中
- 线程池中的工作线程执行前面的任务完成后,不会销毁,而是去从队列中获取任务,继续执行。
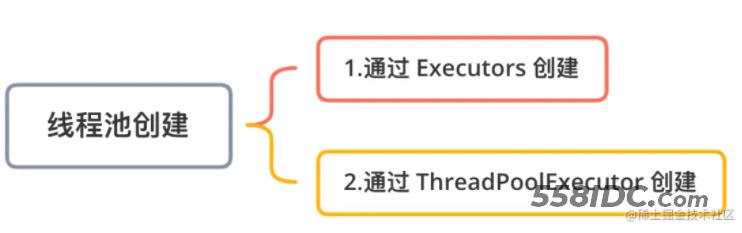
线程池创建
线程池提供如下2种方式创建方式:
ThreadPoolExecutor创建
下面是线程池类ThreadPoolExecutor最全参数的构造函数
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
1.corePoolSize: 核心线程数,线程池中始终存活的线程数量
2.maximumPoolSize:最大线程数,线程池中容纳最大的线程数量,这里引入一个"救急线程"的概念,可以想象为"临时工",它的数量=maximumPoolSize-corePoolSize,这部分线程会超过一定时间后销毁。
3.keepAliveTime:"救急线程"的可以存活的时间,当超过这段时间这些线程没有任务执行,就会被回收。
4.unit:单位,和keepAliveTime配合使用。
5.workQueue: 阻塞队列,用来存储提交的多余的任务,等待工作线程执行完毕后获取,它有下面7个类型:
6.threadFactory: 线程工厂,用于创建线程,可以指定线程名。
7.handler: 拒绝策略,如果任务超限时执行的策略,内置了4种可选,默认AbortPolicy,也可以自定义。
通过这些参数创建好线程后,提交一个线程的执行流程图如下:
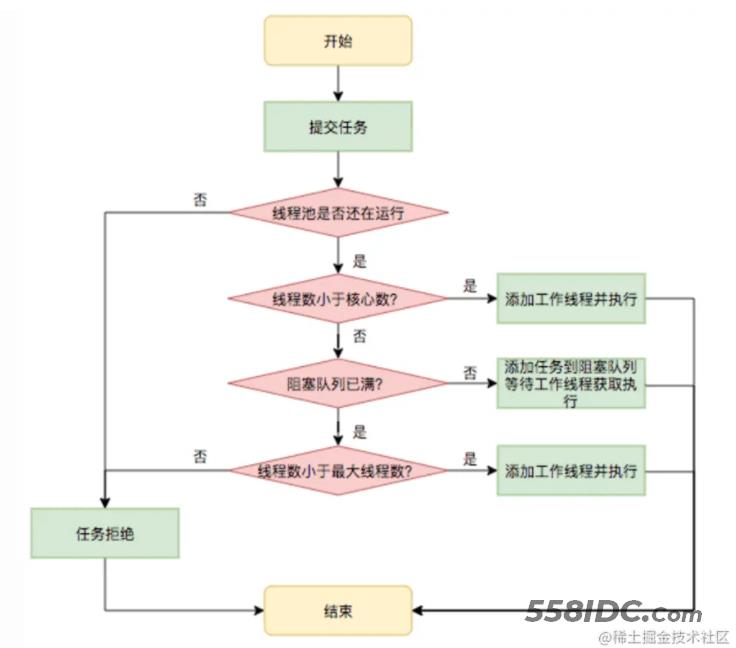
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满, 若线程数小于最大线程数,创建救急线程,否则执行拒绝策略。
Executors创建
由于上面线程池的构造方法比较复杂,jdk也为我们提供了一种便利的方式,通过Executors工厂创建多种不同的线程池。
newFixedThreadPool
创建一个固定大小的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 核心线程数等于最大线程数
- 阻塞队列是无界的,可以不限制任务数量,可能会因为任务太多OOM
- 使用默认的线程工厂和拒绝策略
- 适用于任务量已知、相对耗时的任务
newCachedThreadPool
创建一个核心线程为0,最大线程数不限的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- 核心线程数为0,最大线程数不限制,来一个任务就会创建一个线程,过一段时间会销毁,这样可能会导致线程过多而导致系统资源耗尽。
- 队列采用了 SynchronousQueue 实现,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)。
- 适合任务数比较密集,但每个任务执行时间较短的情况。
newSingleThreadExecutor
创建只有一个线程的线程池。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- 核心线程数和最大线程数都为1,任务数多于 1 时,会放入无界队列排队。
- 适用于只有一个任务执行情况。
问题: newSingleThreadExecutor和newFixedThreadPool(1)区别是什么呢?
newSingleThreadExecutor中创建的线程通过FinalizableDelegatedExecutorService 实现,采用装饰器模式,只对外暴露了 ExecutorService 接口,后续也无法修改线程池的大小。而Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改,对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改。
newScheduledThreadPool
创建可以执行延迟任务的线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
适用于一些延迟执行的调度任务
newWorkStealingPool
这是jdk8引入的一种方式,创建一个抢占式执行的线程池(任务执行顺序不确定)。
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
注意这个不是基于ThreadPoolExecutor 创建出来,而是基于ForkJoinPool 扩展,将任务按照工作线程均分。然后先工作完的线程去帮助没处理完的线程工作。以实现最快完成工作。
适合处理很耗的任务。
线程池关键API和例子
提交执行任务API
void execute(Runnable command)
提交执行Runnable任务,无返回值
Future<T> submit(Callable<T> task)
提交任务 callable任务,用返回值 Future 获得任务执行结果,主线程可以执行 FutureTask.get()方法来阻塞等待任务执行完成。
Future<?> submit(Runnable task)
提交Runnable任务,用返回值 Future 获得任务执行结果,主线程可以执行 FutureTask.get()方法来阻塞等待任务执行完成。
Future<T> submit(Runnable task, T result)
提交Runnable任务,用返回值 Future 获得任务执行结果,返回传入的result, 主线程可以执行 FutureTask.get()方法来阻塞等待任务执行完成。
List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
批量提交Callable任务,用返回值 Future 获得任务执行结果,主线程阻塞等待任务执行完成。
List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
带超时时间的批量提交Callable任务,用返回值 Future 获得任务执行结果,主线程阻塞等待任务执行完成或者过了超时时间。
T invokeAny(Collection<? extends Callable<T>> tasks)
提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
@Test
public void test1() throws ExecutionException, InterruptedException {
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5, 100,
100, TimeUnit.SECONDS, new ArrayBlockingQueue<>(50),
new ThreadPoolExecutor.DiscardPolicy());
for (int i = 0; i < 20; i++) {
// execute的方式提交任务
threadPool.execute(() -> {
log.info("execute ....");
});
}
// submit runnable
Future<String> futureCall = threadPool.submit(new Callable<String>() {
@Override
public String call() throws Exception {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "callable Result";
}
});
// 阻塞等待结果返回
String result = futureCall.get();
log.info("submit callable: {}", result);
// submit runnable
Future<String> future = threadPool.submit(new Runnable() {
@Override
public void run() {
log.info("submit runnable ....");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "submit result");
// 阻塞等待结果返回
result = future.get();
log.info("submit runnable: {}", result);
List<Callable<String>> callables = new ArrayList<>();
for (int i = 0; i < 5; i++) {
final int j = i;
callables.add(new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(2000);
return "callable" + j;
}
});
}
List<Future<String>> futures = threadPool.invokeAll(callables);
for (Future<String> stringFuture : futures) {
String invoke = stringFuture.get();
log.info("invoke result: {}", invoke);
}
String invokeAny = threadPool.invokeAny(callables);
log.info("invoke any: {}", invokeAny);
}
关闭线程池API
shutdown()
优雅关闭线程池,不会接收新任务,但已提交任务会执行完,包括等待队列里面的。
List<Runnable> shutdownNow()
立即关闭线程池,不会接收新任务,也不会执行队列中的任务,并用 interrupt 的方式中断正在执行的任务,返回队列中的任务。
isShutdown()
返回线程池是否关闭
isTerminated()
如果在关闭后所有任务都已完成,则返回true。注意,除非先调用shutdown或shutdownNow,否则istterminated永远不会为true。
boolean awaitTermination(long timeout, TimeUnit unit)
阻塞直到所有任务在关闭请求后完成执行,或发生超时,或当前线程被中断(以先发生的情况为准)。如果该执行程序终止,则为True;如果在终止前超时,则为false。
线程池监控API
long getTaskCount():获取已经执行或正在执行的任务数long getCompletedTaskCount(): 获取已经执行的任务数int getLargestPoolSize():获取线程池曾经创建过的最大线程数,根据这个参数,我们可以知道线程池是否满过int getPoolSize():获取线程池线程数int getActiveCount(): 获取活跃线程数(正在执行任务的线程数)
扩展API
ThreadPoolExecutor留下了3个扩展接口供我们使用。
protected void beforeExecute(Thread t, Runnable r): 任务执行前被调用protected void afterExecute(Runnable r, Throwable t): 任务执行后被调用protected void terminated(): 线程池结束后被调用
@Test
public void test3() {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 1, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1)) {
@Override protected void beforeExecute(Thread t, Runnable r) {
System.out.println("beforeExecute is called");
}
@Override protected void afterExecute(Runnable r, Throwable t) {
System.out.println("afterExecute is called");
}
@Override protected void terminated() {
System.out.println("terminated is called");
}
};
executor.submit(() -> System.out.println("this is a task"));
executor.shutdown();
}
运行结果:
使用注意事项
1.创建线程池的时候,根据阿里巴巴规范,创建线程池的时候根据使用场景自定义ThreadPoolExecutor的方式,尽量避免是使用Executors。
2.只有当任务都是同类型并且互相独立,线程池的性能才能达到最佳。
- 如果将运行时间较长的与运行时间较短的任务混合在一起,可能造成"拥塞"。
- 如果提交的任务依赖于其他任务,比如某任务等待另一任务的返回值或执行结果,而这他们是提交到同一个Executor中,这种情况就会发生线程饥饿锁。
3.在线程池中会导致从ThreadLocal中获取数据发生混乱,应该尽量避免使用。
4.如果使用submit提交任务,会吞掉异常日志,在线程池中尽量使用try catch捕获异常。
到此这篇关于一文了解Java 线程池的正确使用姿势的文章就介绍到这了,更多相关Java 线程池内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!