目录 1. 需求概述 2. 代码实现 1. 需求概述 最近接到一份PDF资料需要打印,奈何页面是如图所示的A3格式的,奈何目前条件只支持打印A4。 我想要把每页的一个大页面裁成两个小的页面,
目录
- 1. 需求概述
- 2. 代码实现
1. 需求概述
最近接到一份PDF资料需要打印,奈何页面是如图所示的A3格式的,奈何目前条件只支持打印A4。
我想要把每页的一个大页面裁成两个小的页面,以便打印工作的顺利进行。
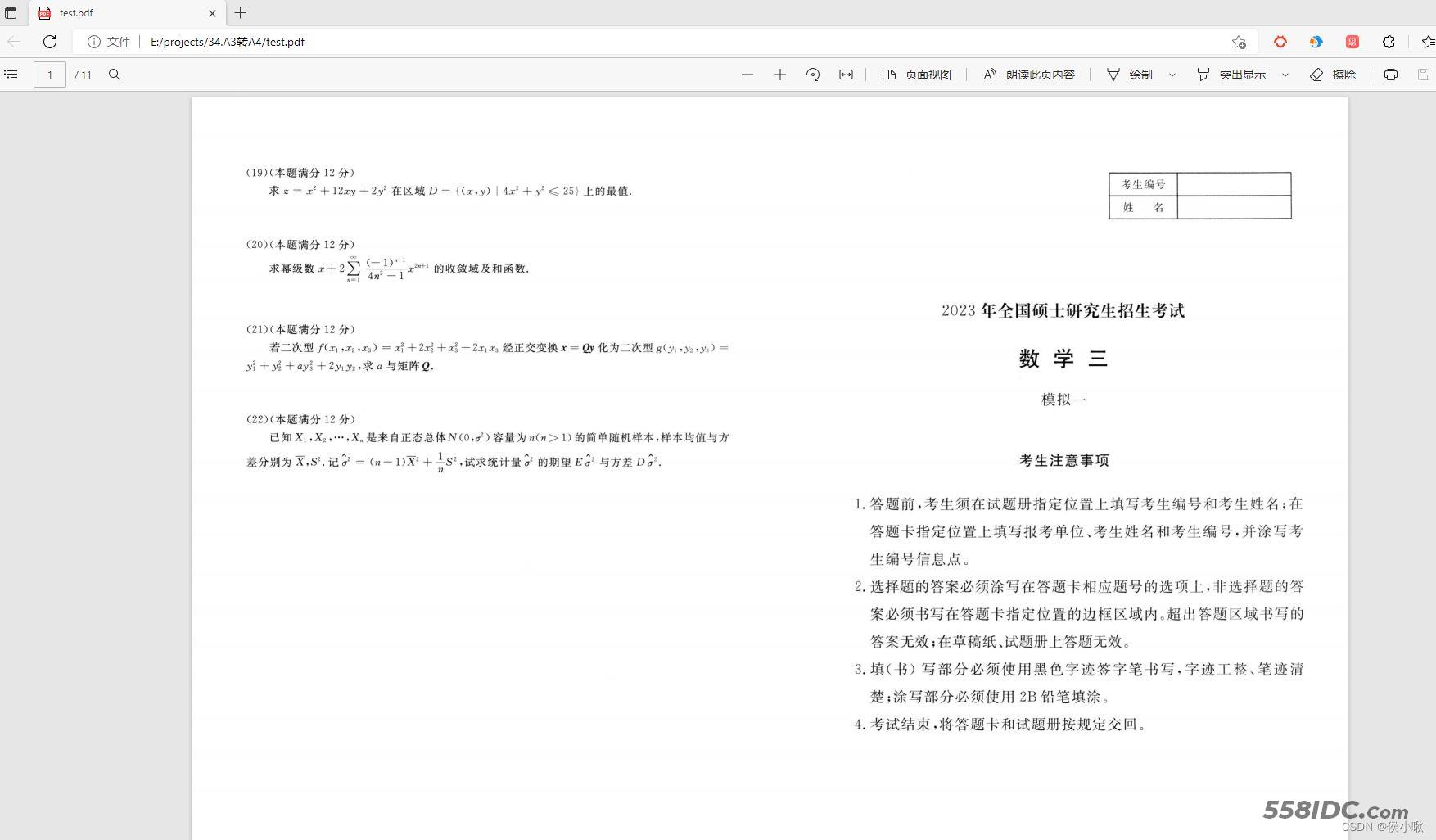
遂决定写一段python代码,来实现该功能。
2. 代码实现
首先在当前目录下创建一个python文件,并编辑以下代码。
导入相关库后,代码共定义三个函数,
第一个函数将pdf拆分为多个图片,放在自动新建的images1文件夹中。
第二个函数则将每个图片进行切割,切割后的图片放在自动创建的images2文件夹中。
第三个函数则将images2文件夹中的每个图片合并成为pdf。
import fitz
import time
import os
import cv2
from fpdf import FPDF
from PIL import Image
# 将pdf分割为图片,并建立一个images1文件夹保存之 传入要拆解的pdf文件名
def to_image(file_name):
dir1 = "images1"
if not os.path.exists(dir1):
os.mkdir(dir1)
time_start = time.time()
doc = fitz.open(file_name)
rotate = int(0)
zoom_x = 2.0
zoom_y = 2.0
trans = fitz.Matrix(zoom_x, zoom_y)
print("%s开始转换..." % file_name)
pg = 0
for page in doc:
timep_start = time.time()
pg += 1
pm = page.get_pixmap(matrix=trans, alpha=False)
new_full_name = dir1 + "/" + file_name.split(".")[0]
filename1 = "{0:s}{1:0>3d}.jpg".format(new_full_name, pg)
pm.save(filename1)
timep_end = time.time()
print('第 ' + str(pg) + ' 页生成图片累计用时:' + str(timep_end - timep_start))
time_end = time.time()
print('拆解累计用时:' + str(time_end - time_start))
# 将images1文件夹中的每个图片,左右分割为两张,并新建images2文件夹以保存文件
def cut_img():
for img in os.listdir("images1"):
image = cv2.imread("images1/" + img)
x0 = int(image.shape[1]/2)
dir2 = "images2"
if not os.path.exists(dir2):
os.mkdir(dir2)
img1 = image[:, 0:x0]
img2 = image[:, x0:]
cv2.imwrite(dir2 + "/" + img[:-4] + '1.jpg', img1)
cv2.imwrite(dir2 + "/" + img[:-4] + '2.jpg', img2)
# 将images2文件夹中的图片合并成为一个pdf,按照文件名的顺序 传入输出的pdf文件名
def makePdf(pdfFileName):
listPages = ["images2/" + imgFileName for imgFileName in os.listdir('images2')]
cover = Image.open(listPages[0])
width, height = cover.size
pdf = FPDF(unit="pt", format = [width, height])
for page in listPages:
pdf.add_page()
pdf.image(page, 0, 0)
pdf.output(pdfFileName, "F")
# 执行
if __name__ == "__main__":
to_image("test.pdf")
cut_img()
makePdf("result.pdf")
处理后得到的文件,即result.pdf,打开后效果如下图所示:
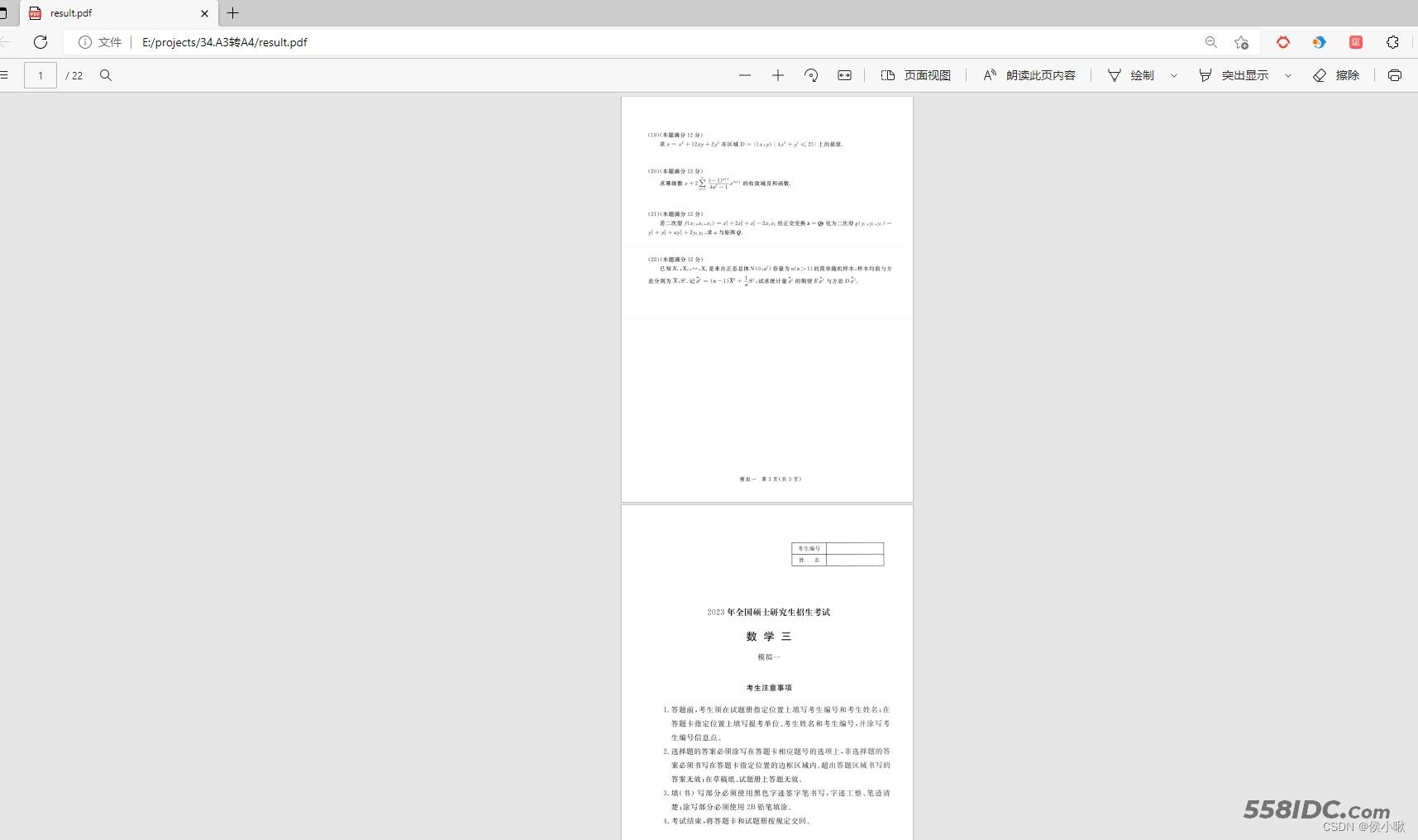
可以看到页面成功地被分割,并由原来的11页变成了22页。非常的完美,打印工作可以顺利进行了。
到此这篇关于Python操作PDF文件之实现A3页面转A4的文章就介绍到这了,更多相关Python PDF A3页面转A4内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!