目录 Python自动化办公之删除重复文件 思路介绍 源码解说 知识拓展 Python自动化办公之删除重复文件 思路介绍 两层判断: 1.先判断文件大小是否为相同,大小不同则不是重复文件,予以
目录
- Python自动化办公之删除重复文件
- 思路介绍
- 源码解说
- 知识拓展
Python自动化办公之删除重复文件
思路介绍
两层判断:
1.先判断文件大小是否为相同,大小不同则不是重复文件,予以保留;
2.文件大小相同再判断文件md5,md5相同,则是重复文件,予以删除。
源码解说
from pathlib import Path
import hashlib
def getmd5(filename):
# 接收文件路径,返回文件md5值
with open(filename, 'rb') as f:
data = f.read()
file_md5 = hashlib.new("md5", data).hexdigest()
return file_md5
def main():
path = r"F:\FileRecv\删除文件测试"
all_size = {}
total_file = 0
total_delete = 0
# 获取路径内的所有文件名,默认是升序排列,相同文件将会保留日期时间最新的
all_files = Path(path).glob('*.*')
# 降序排列,相同文件将会保留文件名最短的(即日期时间最久的)
all_files = sorted(all_files, reverse=True)
# 遍历文件路径内的所有文件
for file in all_files:
# 获取文件所占字节大小,作为数据字典的键
size = file.stat().st_size
# name_and_md5列表用于存储文件绝对路径和md5值,作为数据字典的值
name_and_md5 = [file, '']
# 针对重复文件进行处理,生成字典存储相关信息
# 字典all_size中key是size,value是name_and_md5列表
# 针对相同size的文件,再调用getmd5函数,获取文件的md5值
# 文件size不同(不在all_size.keys()中),则自动判断为不同的文件,予以保留
if size in all_size.keys():
# 调用getmd5函数,获取文件的md5值
new_md5 = getmd5(file)
if all_size[size][1] == '':
all_size[size][1] = getmd5(all_size[size][0])
# 判断md5值存在,即文件重复,则删除文件。md5值不存在,则把md5值加入列表中
if new_md5 in all_size[size]:
file.unlink()
total_delete += 1
else:
all_size[size].append(new_md5)
else:
all_size[size] = name_and_md5
total_file += 1
print(f'文件总数:{total_file}')
print(f'删除个数:{total_delete}')
if __name__ == '__main__':
main()
效果图:

代码说明:特别感谢瑜亮老师提供的代码!
知识拓展
pathlib和os,os.path常用的函数对应关系
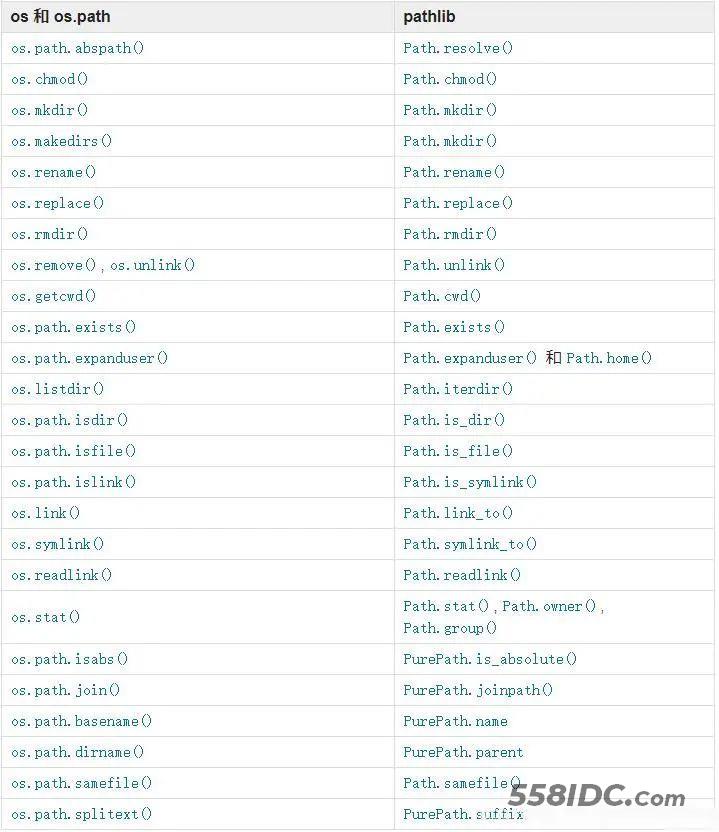
pathlib常用方法介绍:
Path(path).name # 返回文件名+文件后缀
Path(path).stem # 返回文件名
Path(path).suffix # 返回文件后缀
Path(path).suffixes # 返回文件后缀列表
Path(path).root # 返回根目录
Path(path).parts # 返回文件
Path(path).anchor # 返回根目录
Path(path).parent # 返回父级目录
Path(path).parents # 返回所有上级目录的列表
Path.exists() # 判断 Path 路径是否是一个已存在的文件或文件夹
Path.is_dir() # 判断 Path 是否是一个文件夹
Path.is_file() # 判断 Path 是否是一个文件
Path.mkdir() # 创建文件夹
Path.rmdir() # 删除文件夹,文件夹必须为空
Path.unlink() # 删除文件
到此这篇关于详解如何使用Python实现删除重复文件的文章就介绍到这了,更多相关Python删除重复文件内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!