目录 前言 一 前期工作 1.设置GPU或者cpu 2.导入数据 二 数据预处理 1.加载数据 2.可视化数据 3.再次检查数据 三 搭建网络 四 训练模型 1.设置学习率 2.模型训练 五 模型评估 1.Loss和Accura
目录
- 前言
- 一 前期工作
- 1.设置GPU或者cpu
- 2.导入数据
- 二 数据预处理
- 1.加载数据
- 2.可视化数据
- 3.再次检查数据
- 三 搭建网络
- 四 训练模型
- 1.设置学习率
- 2.模型训练
- 五 模型评估
- 1.Loss和Accuracy图
- 2.总结
前言
环境:
- 语言环境:Python3.6
- 编译器:jupyter lab
- 深度学习环境:pytorch1.10
要求:
- 学习如何编写一个完整的深度学习程序(✔)
- 手动推导卷积层与池化层的计算过程(✔)
一 前期工作
环境:python3.6,1080ti,pytorch1.10(实验室服务器的环境)
1.设置GPU或者cpu
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2.导入数据
train_ds = torchvision.datasets.MNIST('data',
train=True,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
test_ds = torchvision.datasets.MNIST('data',
train=False,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
二 数据预处理
1.加载数据
设置数据尺寸
batch_size = 32
设置dataset
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size)
2.可视化数据
打印部分图片:
import numpy as np
# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]):
# 维度缩减
npimg = imgs.numpy().transpose((1, 2, 0))
# 将整个figure分成2行10列,绘制第i+1个子图。
plt.subplot(2, 10, i+1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off')

3.再次检查数据
输出数据的尺寸:
# 取一个批次查看数据格式 # 数据的shape为:[batch_size, channel, height, weight] # 其中batch_size为自己设定,channel,height和weight分别是图片的通道数,高度和宽度。 imgs, labels = next(iter(train_dl)) imgs.shape

三 搭建网络
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential,ReLU
num_classes = 10
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
# 卷积层
self.layers = Sequential(
# 第一层
Conv2d(3, 64, kernel_size=3),
MaxPool2d(2),
ReLU(),
# 第二层
Conv2d(64, 64, kernel_size=3),
MaxPool2d(2),
ReLU(),
Conv2d(64, 128, kernel_size=3),
MaxPool2d(2),
ReLU(),
Flatten(),
Linear(512, 256,bias=True),
ReLU(),
Linear(256, 64,bias=True),
ReLU(),
Linear(64, num_classes,bias=True)
)
def forward(self, x):
x = self.layers(x)
return x
打印网络结构:

vgg16网络搭建:未修改尺寸
from torch import nn
vgg16=torchvision.models.vgg16(pretrained=True)#经过训练的
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
# 卷积层
self.layers = Sequential(
vgg16
)
def forward(self, x):
x = self.layers(x)
return x
vgg16网络搭建:修改尺寸
四 训练模型
1.设置学习率
loss_fn = nn.CrossEntropyLoss() # 创建损失函数 learn_rate = 1e-2 # 学习率 opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2.模型训练
训练函数:
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
测试函数 :
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
具体训练代码 :
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
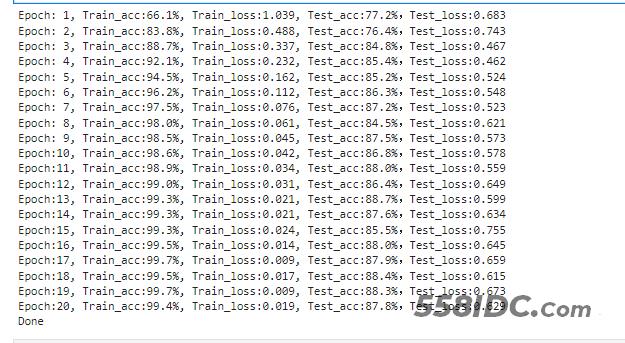
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')

五 模型评估
1.Loss和Accuracy图
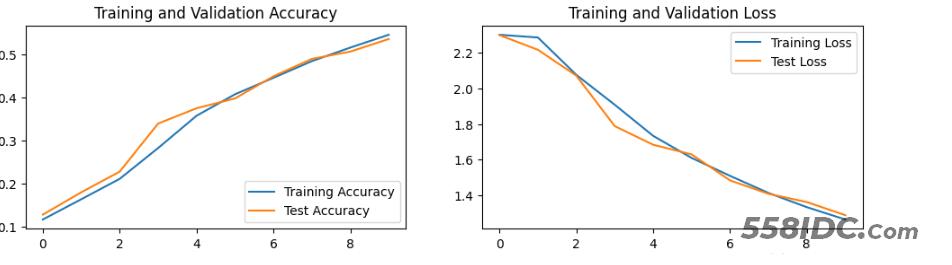
2.总结
- 1.本文与上篇文章区别在于灰色图像和彩色图像通道数一个为1,一个为3.所以这里的卷积输入都是3.
- 2.关于各层计算这里简单说一下,我们以范文举例:
卷积层:32->30因为((32-3)/1)+1=30
池化池:30->15因为30÷2=15
具体计算可以参考我题目开头的文章,这里不在赘述
我们可以看到本次训练效果不好,那我们可以利用经典网络vgg16进行修改,准确率提高到了百分之88了。
其代码如上:
到此这篇关于pytorch-实现mnist手写彩色数字识别的文章就介绍到这了,更多相关pytorch mnist内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!