前言: 有时候 我们抓取一些页面,发现一些url 有重定向, 返回 301 ,或者302 这种情况。 那么我们如何获取真实的URL呢? 或者跳转后的URL呢? 这里我使用 requests 作为演示 假设我们要
前言:
有时候 我们抓取一些页面,发现一些url 有重定向, 返回 301 ,或者302 这种情况。 那么我们如何获取真实的URL呢? 或者跳转后的URL呢?
这里我使用 requests 作为演示
假设我们要访问 某东的电子商务网站,我只记得网站好像是 http://jd.com
import requests
def request_jd():
url = 'http://jd.com/'
#allow_redirects= False 这里设置不允许跳转
response = requests.get(url=url, allow_redirects=False)
print(response.headers)
print(response.status_code)
看结果 返回response header 中有一个属性 Location ,代表重定向了 'Location': 'https://www.jd.com'

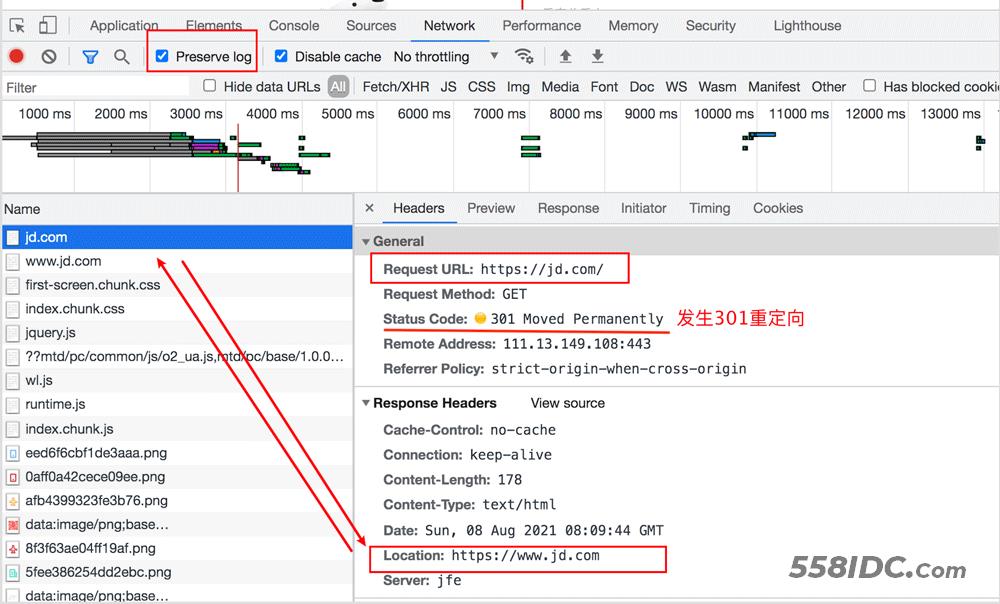
我们在浏览器中 chrome network 面板 ,抓包观察。 注意把 preserve log 这个选项勾选上。
从 浏览器的response header 中 我们可以看到 Location, 从 General 我们可以看到 status code 301 ,发生了跳转。
方法1:
你现在知道如何获取跳转后的URL了吗,直接从response header,获取 Location 即可。
在request.header 中 返回header 的key是不区分大小写的, 所以全小写也是可以正确取值的。
import requests
def request_jd():
url = 'http://jd.com/'
response = requests.get(url=url, allow_redirects=False)
#return response.headers.get('location')
return response.headers.get('Location')
方法2:
其实默认情况下, requests 会自动跳转,如果发生了重定向,会自动跳到location 指定的URL,我们只需要访问URL, 获取response, 然后 response.url 就可以获取到真实的URL啦。
import requests
def request_jd():
url = 'http://jd.com/'
response = requests.get(url=url)
return response.url
到此这篇关于python3中requests库重定向获取URL的文章就介绍到这了,更多相关python获取URL 内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!