目录
- Python查看数据类型与格式
- 先随机创一点数据用来测试
- 查看现有的数据是数据框类型还是数组矩阵类型
- 查看数据格式是字符串还是数字格式
- Python数据类型bytes
- 1 bytes类型的特性
- 2 bytes类型创建与转化
- 3 bytes类型切片迭代
Python查看数据类型与格式
一般我们拿到一个数据,会先看一下这个数据有多少行多少列,各个字段是什么,数据格式类型是什么。在开始讲数据格式前,需要先梳理一下各个数据类型。
我们常使用的库一般是numpy和pandas,Numpy下的核心是数组(array,ndarray),Pandas下的核心是数据框(Series,DataFrame)
先随机创一点数据用来测试
import pandas as pd import numpy as np df=pd.DataFrame(np.random.randint(5,10,size=(10,2)),columns=['a','b']) Array=np.random.randint(5,10,size=(10,2)) #假设我们不知道df和Array是什么数据类型
查看现有的数据是数据框类型还是数组矩阵类型
语法:type(XXX),适用于tuple/list/array/ndarray/Series/Dataframe
print(type(df)) #输出 class 'pandas.core.frame.DataFrame'这是DataFrame类型的数据 print(type(Array)) #输出class 'numpy.ndarray'这是多维数组 print(type(tuple(Array))) #输出'tuple'这是元组 print(type(list(df['a']))) #输出'class list'这是一个list类型
查看数据格式是字符串还是数字格式
这里需要区分一下Numpy和Pandas的查看方式略有不同,一个是dtype,一个是dtypes
print(Array.dtype) #输出int64 print(df.dtypes) #输出Df下所有列的数据格式 a:int64,b:int64
Python数据类型bytes
1 bytes类型的特性
Python 3.x之后,Python自带字符默认使用utf-8格式编码和显示
- Python默认字符串string数据类型是utf-8显示形式的序列
- bytes数据类型是utf-8格式的二进制形式的不可变序列
- bytearray数据类型是utf-8格式的二进制形式的可变序列
1.1 ASCII表
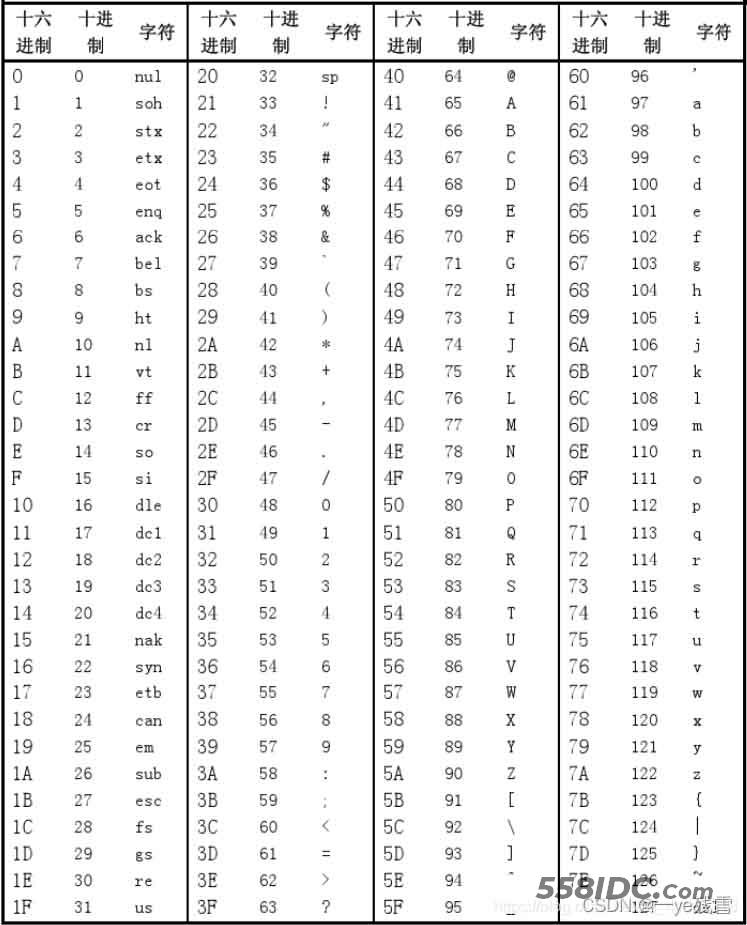
2 bytes类型创建与转化
2.1 bytes类型与数字
数字类型并不是字符串,无法直接生成对应的bytes类
Python对数字类型定义了特殊意义
① 当入参为数字时,表示创建nul(\x00)的向量
byte_str = bytes(10) print(byte_str) >>> b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
② 当入参为数字的序列时,直接转为bytes的序列,且对应值相同,将数字序列直接写入底层应该使用这种方法
byte_str = bytes([1, 10, 0xF]) print(byte_str) >>> b'\x00\x10\x0f'
③ 当二进制数据在[33, 126]区间时,属于ASCII表上可显示字符范围,会直接显示对应的字符
数字直接使用bytes创建
byte_str = bytes([33, 48, 126]) print(byte_str) >>> b'!0~'
2.2 bytes类型与ASCII字符
2.2.1 创建bytes数据
① 使用b''创建
byte_str = b'Python' print(byte_str) >>> b'Python'
② 使用bytes()创建不可变序列
byte_str = bytes('Python', encoding='utf-8')
print(byte_str)
>>> b'Python'
③ 使用bytearray()创建可变序列
byte_str = bytearray('Python', encoding='utf-8')
print(byte_str)
>>> bytearray(b'Python')
2.2.2 还原bytes数据
① 使用bytes.decode()还原不可变序列
byte_str = bytes('Python', encoding='utf-8')
utf_str = bytes.decode(byte_str)
print(utf_str)
>>> 'Python'
② 使用bytearray.decode()还原可变序列
byte_str = bytearray('Python', encoding='utf-8')
utf_str = bytearray.decode(byte_str)
print(utf_str)
>>> 'Python'
2.3 bytes类型与汉字
在UTF-8中,每个汉字用3个Byte表示
byte_str = bytes('我是', encoding='utf-8')
print(byte_str)
>>> b'\xe6\x88\x91\xe6\x98\xaf'
还原:
byte_str = b'\xe6\x88\x91\xe6\x98\xaf' utf_str = bytes.decode(byte_str) print(utf_str) >>> '我是'
3 bytes类型切片迭代
① 通过bytes[index]方式返回的是底层int类型
byte_str = b'a' print(type(byte_str[0])) print(byte_str[0]) >>> <class 'int'> >>> 97
byte_str = b'abc' print(type(byte_str[2])) print(byte_str[2]) >>> <class 'int'> >>> 99
② 通过for ... in bytes方式返回的是底层int类型
byte_str = b'abc' for byte in byte_str: print(type(byte)) print(byte) >>> <class 'int'> >>> 97 >>> <class 'int'> >>> 98 >>> <class 'int'> >>> 99
③ 通过bytes[start:end]方式返回的是底层bytes类型
byte_str = b'a' print(type(byte_str[:])) print(byte_str[:]) >>> <class 'bytes'> >>> b'a'
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。