目录
- 骨骼识别的应用场景
- 骨骼识别的实现原理
- 环境准备
- 代码实战
- 运行与效果
- 总结
骨骼识别的应用场景
如今,当前疫情大环境之下。很多人,因为居家办公或者其他原因闷在家里不能外出健身。那么,借助骨骼识别和卷积神经网络模型,计算机视觉开发者可以通过相对应的API,结合相对轻量化一些的卷积神经网络模型,来构建如Keep这类的线上锻炼监督APP。
用户通过将摄像头对准自己,使得神经网络能过精确地通过人体骨骼框架,判断出用户是否有在“认认真真”的做运动。
骨骼网络也可以应用在3D模型构建中,通过将获取到的骨骼网络信息,与Unity或虚幻等引擎中的3D模型进行动态绑定,即可得到属于自己的虚拟人物形象。
骨骼识别的实现原理
通过观察MediaPipe的官方文档,我们可以看到
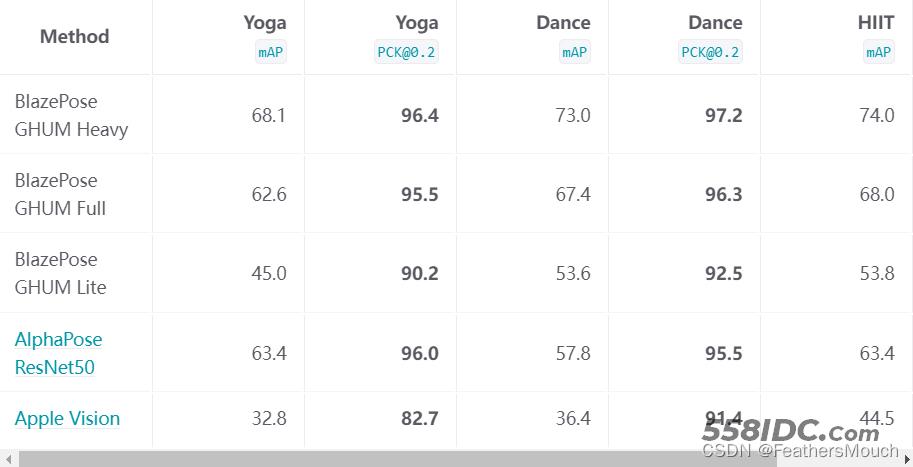
MediaPipe是通过两套深度神经网络:即基于GHUM模型的BlazePose和ResNet50模型的AlphaPose。
以下是MediaPipe官方对于模型的概述:
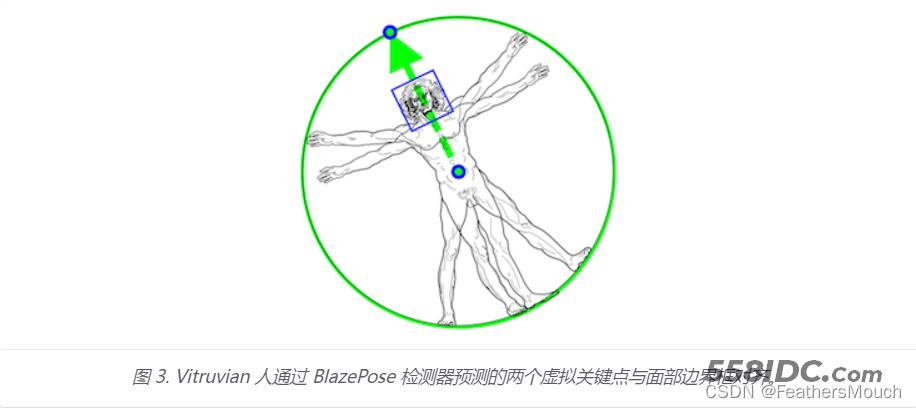
该检测器的灵感来自我们自己的轻量级BlazeFace模型,用于MediaPipe 人脸检测,作为人体检测器的代理。它明确地预测了两个额外的虚拟关键点,将人体中心、旋转和比例牢牢描述为一个圆圈。受莱昂纳多的《维特鲁威人》的启发,我们预测了一个人臀部的中点、包围整个人的圆的半径以及连接肩部和臀部中点的连线的倾斜角。
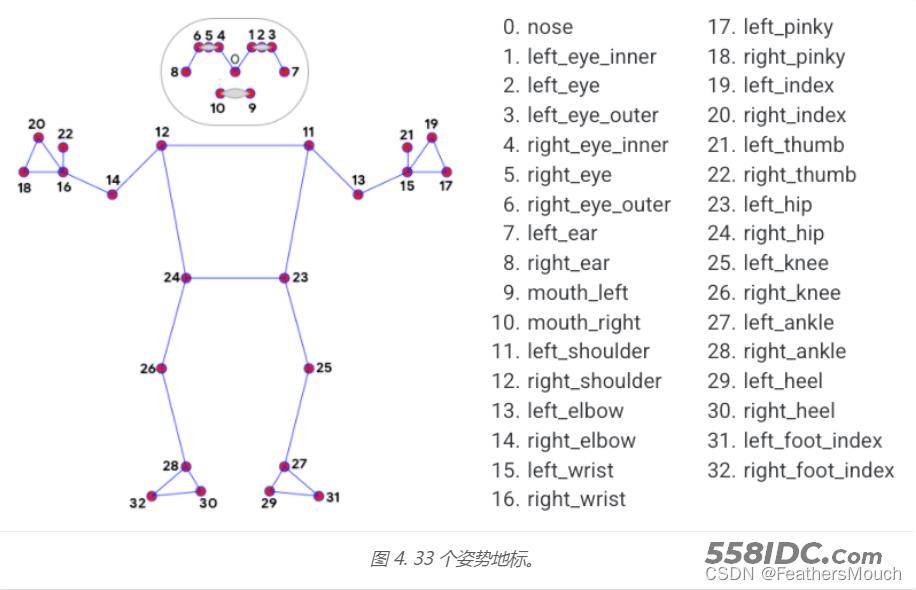
另外,MediaPipie通过从GHUM模型中获取到33个定位点,用于对人体骨骼的完整检测,见下图:
环境准备
请确保你的Python环境中包含如下的库,才能顺利完成依赖处理并安装mediapipe
- numpy
- tensorflow
- opencv
使用pip install mediapipe来安装mediapipe模块
pip install mediapipe
代码实战
我这里准备了一个特别视频用于检测骨骼API检测。但是在开始之前,我们要先把我们使用的模块导入进来
import time import cv2 import mediapipe as mp import sys
首先我们初始化MediaPipe标志点绘制器和MediaPipe姿态检测器
# 初始化MediaPipe绘图工具,以及样式 mp_drawing = mp.solutions.drawing_utils mp_drawing_styles = mp.solutions.drawing_styles mp_pose = mp.solutions.pose
初始化OpenCV窗口
# 初始化OpenCV窗口
window = cv2.namedWindow("Gi", cv2.WINDOW_FULLSCREEN)
使用cv2.VideoCapture()读取视频
cap = cv2.VideoCapture('data.flv')
设置捕获器的缓冲区大小
# 设置视频缓冲区 cap.set(cv2.CAP_PROP_BUFFERSIZE, 2)
初始化FPS计数器和FPS计数时间
# 初始化FPS计时器和计数器 fps_start_time = 0 fps = 0
定义图像处理函数processing()
# 定义Processing处理函数
def processing(image):
# 使用cv2.putText绘制FPS
cv2.putText(image, "FPS: {:.2f}".format(
fps), (10, 85), cv2.FONT_HERSHEY_SIMPLEX, 3, (0, 255, 0), 3)
# 使用image.flags.writeable = False将图像标记为只读,以加快处理速度
image.flags.writeable = False
# 使用cv2.resize将图像缩放到适合的尺寸
image = cv2.resize(image, (640, 480))
# 使用cv2.cvtColor将图像转换为RGB
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用MediaPipe Pose检测关键点
results = pose.process(image)
# 解锁图像读写
image.flags.writeable = True
# 将图像转换回BGR
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 使用draw_landmarks()绘制关键点
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
# 返回处理后的图像
return image
初始化MediaPipe Pose类并开始进行骨骼检测
# 初始化MediaPipe Pose类
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
# 当视频打开时
while cap.isOpened():
# 读取视频帧和状态
success, image = cap.read()
# 如果初始化失败,则推出进程
if not success:
print("")
exit(1)
# 初始化FPS结束点计时器
fps_end_time = time.time()
# 计算FPS
fps = 1.0 / (fps_end_time - fps_start_time)
# 重置FPS开始点计时器
fps_start_time = fps_end_time
# 创建线程处理图像
image = processing(image)
# 显示图像
cv2.imshow('Gi', image)
# 按下q键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
运行与效果
运行脚本
python Baby.py
运行结果如下图:

总结
MediaPipe提供众多的API供开发者使用,例如:目标识别,人脸识别,手部识别以及骨骼识别等等。通过内置的卷积神经网络模型进行探测,极大程度的节省了计算机视觉开发者的开发时间,提升了开发效率。
到此这篇关于MediaPipe API实现骨骼识别功能分步讲解流程的文章就介绍到这了,更多相关MediaPipe API骨骼识别内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!