目录
- 下载tensorflow的代码
- 转换
- 第一个改成自己的数据路径:
- 第二个修改range的返回类型
- 修改bytes
- 读写方式调整
- 匹配python3
- 跑一下验证
下载tensorflow的代码
地址:
https://github.com/tensorflow/models.git
然后进入目录:
cd models/research/slim/datasets/
下载Imagenet2012数据集
可以到官网注册下载,或者:
https://www.jb51.net/article/262851.htm
我这里把数据放到了tensorflow路径下:
./models/research/slim/datasets/imagenet2012
models也就是上边下载的tensorflow代码的路径,imagenet2012是自己创建的目录,然后下载完后:

红色的是我要用的数据集,本身我的目的是要做评估,应该用不到ILSVRC2012_bbox_train_v2.tar,但是转数据的时候报找不到某些文件,因此也加上了它,后缀V3 V2代表不同的任务。
蓝色的需要先创建一下目录后续解压数据集要用到。
处理数据参考的是华为的文档:
https://support.huawei.com/enterprise/zh/doc/EDOC1100191905/a8d9a8a2
可以准备一个解压脚本,解压到对应目录:
#!/bin/bash # mkdir -p train val bbox imagenet_tf tar -xvf ILSVRC2012_img_train.tar -C train/ tar -xvf ILSVRC2012_img_val.tar -C val/ tar -xvf ILSVRC2012_bbox_train_v2.tar -C bbox/ tar -xvf ILSVRC2012_bbox_val_v3.tgz -C bbox/
转换
先上脚本,然后说一下执行前如何修改脚本里用到的python文件的内容。
python preprocess_imagenet_validation_data.py ./imagenet2012/val/ imagenet_2012_validation_synset_labels.txt python process_bounding_boxes.py ./imagenet2012/bbox/ imagenet_lsvrc_2015_synsets.txt | sort > imagenet_2012_bounding_boxes.csv python build_imagenet_data.py --output_directory=./imagenet2012/imagenet_tf --validation_directory=./imagenet2012/val
三个脚本均在 ./models/research/slim/datasets 目录下,我们知道tensorflow本身跨版本之前的代码有很大的区别,像 build_imagenet_data.py 等大多数脚本已经是2年前的了,现在的好多新的环境,比如python3中,直接执行会报很多错误,看下怎么改,参考:
https://www.jb51.net/article/186963.htm
第一个改成自己的数据路径:
蓝色改成自己对应的红色:
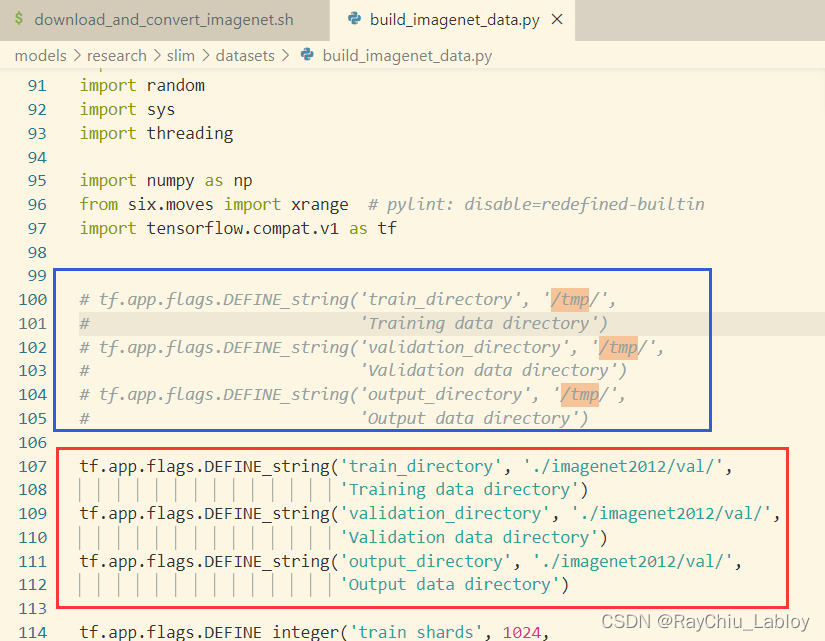
可以看到train 数据路径和 output的路径都和val路径一样,否则找不到 n01440764 ,这里我觉得我的数据还是有问题。
第二个修改range的返回类型
大概500行左右:
# 原来 shuffled_index = range(len(filenames)) ,加list()改为以下: shuffled_index = list(range(len(filenames)))
修改bytes
蓝色改为红色,绿色很多网友说要改,但是我这里改了反而报错。

读写方式调整
蓝色改为红色:

匹配python3
加判断:

然后就可以转换了,结果是:

跑一下验证
python eval_image_classifier.py \ --checkpoint_path='./weights' \ --eval_dir='./log/' \ --dataset_name=imagenet \ --dataset_split_name=validation \ --dataset_dir='./datasets/imagenet2012/imagenet_tf/' \ --model_name=resnet_v1_50
执行后会打印出如下内容:
eval/Accuracy[0.51]
eval/Recall_5[0.973333336]
Accuracy表示模型的分类准确率,Recall_5表示前5次的准确率
到此这篇关于将imagenet2012数据为tensorflow的tfrecords格式并跑验证的文章就介绍到这了,更多相关tensorflow imagenet2012数据内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!