目录
- 概述
- 介绍和使用
- 核心机制
- 实现机制
- 扩容机制
- 源码解析
- 成员变量
- 构造函数
- put方法
- get方法
- remove方法
- 总结
概述
HashTable是jdk 1.0中引入的产物,基本上现在很少使用了,但是会在面试中经常被问到,你都知道吗:
- HashTable底层的实现机制是什么?
- HashTable的扩容机制是什么?
- HashTable和HashMap的区别是什么?
介绍和使用
和HashMap一样,Hashtable也是一个散列表,它存储的内容是键值对(key-value)映射, 重要特点如下:
- 存储key-value键值对格式
- 是无序的
- 底层通过数组+链表的方式实现
- 通过synchronized关键字实现线程安全
- key、value都不可以为null(为null时将抛出NullPointerException)

以上是Hashtable的类结构图:
- 实现了Map接口,提供了键值对增删改查等基础操作
- 继承了Dictionary字典类,Dictionary是声明了操作"键值对"函数接口的抽象类。
- 实现了Cloneable接口,实现数据的浅拷贝
- 实现了Serializable接口,标记Hashtable支持序列化
使用案例:
@Test
public void test() {
Hashtable<String, String> table=new Hashtable<>();
Hashtable<String, String> table1=new Hashtable<>(16);
Hashtable<String, String> table2=new Hashtable<>(16, 0.75f);
table.put("T1", "1");
table.put("T2", "2");
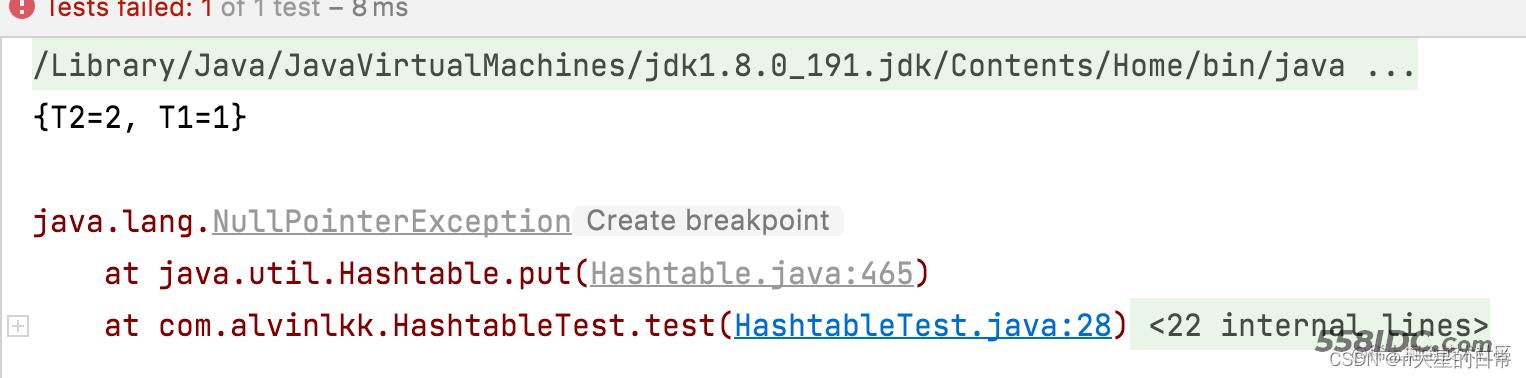
System.out.println(table);
// 报空指针异常
table.put(null, "3");
}
运行结果:
核心机制
实现机制
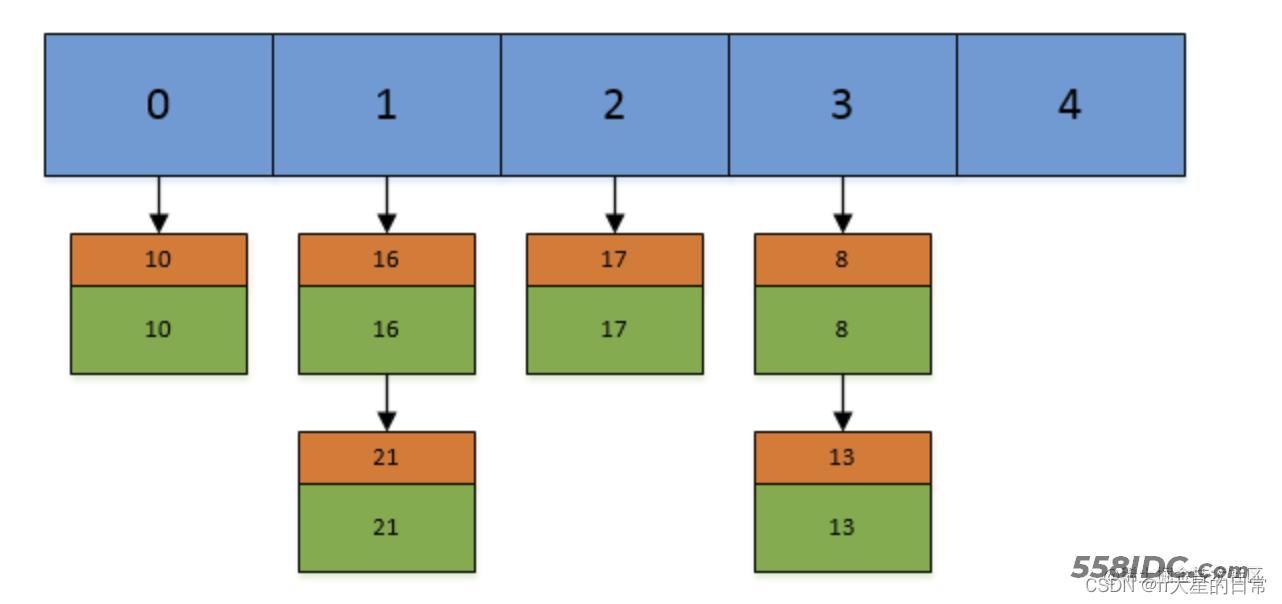
和HashMap相似,Hashtable底层采用数组+链表的数据结构,根据key找到数组对应的桶,相同的key通过链表维护,当数组桶的使用到达阈值后,会进行动态扩容。但是和HashMap不同的是,链表不会转换为红黑树。
扩容机制
扩容机制依赖两个成员变量,初始容量 和 加载因子。他们可以通过构造函数设置。
容量是值哈希表中桶的数量,初始容量就是哈希表创建时的容量。当容量达到阈值的时候,会进行扩容操作,每次扩容是原来容量的2倍加1,然后重新为hashtable中的每个元素重新分配桶的位置。
那阈值是多少呢,Hashtable的阈值,用于判断是否需要调整Hashtable的容量,等于"Hashtable当前的容量*加载因子"。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间。
源码解析
成员变量
// 内部采用Entry数组存储键值对数据,Entry实际为单向链表的表头 private transient Entry<?,?>[] table; // HashTable里键值对个数 private transient int count; // 扩容阈值,当超过这个值时,进行扩容操作,计算方式为:数组容量*加载因子 private int threshold; // 加载因子 private float loadFactor; // 修改次数,用于快速失败机制 private transient int modCount = 0;
Entry的数据结构如下:
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}
Entry是单向链表节点,next指向下一个entry
构造函数
// 设置指定容量和加载因子,初始化HashTable
public Hashtable(int initialCapacity, float loadFactor) {
// 非法参数校验
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
// 非法参数校验
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
// 容量最小为1
initialCapacity = 1;
this.loadFactor = loadFactor;
// 初始化数组
table = new Entry<?,?>[initialCapacity];
// 初始扩容阈值
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
// 设置指定容量初始HashTable,加载因子为0.75
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// 手动指定数组初始容量为11,加载因子为0.75
public Hashtable() {
this(11, 0.75f);
}
put方法
// 方法synchronized修饰,线程安全
public synchronized V put(K key, V value) {
// 如果value为空,直接空指针
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
// 得到key的哈希值
int hash = key.hashCode();
// 得到该key存在到数组中的下标
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 得到该下标对应的Entry
Entry<K,V> entry = (Entry<K,V>)tab[index];
// 如果该下标的Entry不为null,则进行链表遍历
for(; entry != null ; entry = entry.next) {
// 遍历链表,如果存在key相等的节点,则替换这个节点的值,并返回旧值
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 如果数组下标对应的节点为空,或者遍历链表后发现没有和该key相等的节点,则执行插入操作
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
// 修改次数+1
modCount++;
Entry<?,?> tab[] = table;
// 判断是否需要扩容
if (count >= threshold) {
// 如果count大于等于扩容阈值,则进行扩容
rehash();
tab = table;
// 扩容后,重新计算该key在扩容后table里的下标
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
// 采用头插的方式插入,index位置的节点为新节点的next节点
// 新节点取代inde位置节点
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
// count+1
count++;
}
扩容rehash源码如下:
protected void rehash() {
// 暂存旧的table和容量
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// 新容量为旧容量的2n+1倍
int newCapacity = (oldCapacity << 1) + 1;
// 判断新容量是否超过最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0) {
// 如果旧容量已经是最大容量大话,就不扩容了
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
// 新容量最大值只能是MAX_ARRAY_SIZE
newCapacity = MAX_ARRAY_SIZE;
}
// 用新容量创建一个新Entry数组
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
// 模数+1
modCount++;
// 重新计算下次扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
// 将新Entry数组赋值给table
table = newMap;
// 遍历数组和链表,进行新table赋值操作
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
- rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素,重新计算索引位置一一复制到新的Hashtable中,这个过程是比较消耗时间的。
- Hashtable的索引求值公式是:
hash&0x7FFFFFFF%newCapacity。hash&0x7FFFFFF是为了保证正数,因为hashCode的值有可能为负值。
get方法
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
// 获取key对应的index
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 遍历链表,如果找到key相等的节点,则改变前继和后继节点的关系,并删除相应引用,让GC回收
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
remove方法
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
// 获取key对应的index
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 遍历链表,如果找到key相等的节点,则改变前继和后继节点的关系,并删除相应引用,让GC回收
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
总结
本文主要讲解了Hashtable的基本功能和源码解析,虽然Hashtable本身不常用了,但是它的直接子类Properties目前还在被大量使用当中,所以学习它还是有一定价值的。下面在总结下Hashtable和HashMap的区别:
- 线程是否安全:HashMap是线程不安全的,HashTable是线程安全的;HashTable内部的方法基本都经过 synchronized修饰; 如果想要线程安全的Map容器建议使用ConcurrentHashMap,性能更好。
- 对Null key 和Null value的支持:HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null;HashTable中key和value都不能为null,否则抛出空指针异常;
初始容量大小和每次扩充容量大小的不同:
- 创建时如果不指定容量初始值,Hashtable默认的初始大小为11,之后每次扩容,容量变为原来的2n+1。HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍;
- 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充 为2的幂次方大小。
底层数据结构:JDK1.8及以后的HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间,Hashtable没有这样的机制。
到此这篇关于Java Hashtable机制深入了解的文章就介绍到这了,更多相关Java Hashtable内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!