Java 流(Stream)处理操作完成之后,我们可以收集这个流中的元素,使之汇聚成一个最终结果。这个结果可以是一个对象,也可以是一个集合,甚至可以是一个基本类型数据。
以记录 Record 为例:
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Record {
private String col1;
private String col2;
private int col3;
}
记录 Record 包含三个属性:列1(col1)、列2(col2)和 列3(col3)。
创建四个记录实例:
Record r1 = new Record("a", "1", 1);
Record r2 = new Record("a", "2", 2);
Record r3 = new Record("b", "3", 3);
Record r4 = new Record("c", "4", 4);
添加到列表:
List<Record> records = new ArrayList<>(); records.add(r1); records.add(r2); records.add(r3); records.add(r4);
收集所有记录的 列1 值,以列表形式存储结果
List<String> col1List = records.stream()
.map(Record::getCol1)
.collect(Collectors.toList());
log.info("col1List: {}", Json.toJson(col1List));
输出结果:
col1List: ["a","a","b","c"]
收集所有记录的 列1 值,且去重,以集合形式存储
Set<String> col1Set = records.stream()
.map(Record::getCol1)
.collect(Collectors.toSet());
log.info("col1Set: {}", Json.toJson(col1Set));
输出结果:
col1Set: ["a","b","c"]
收集记录的 列2 值和 列3 值的对应关系,以字典形式存储
Map<String, Integer> col2Map = records.stream()
.collect(Collectors.toMap(Record::getCol2, Record::getCol3));
log.info("col2Map: {}", Json.toJson(col2Map));
输出结果:
col2Map: {"1":1,"2":2,"3":3,"4":4}
记录的 列2 不能有重复值,否则会抛出 Duplicate key 异常。
收集所有记录中 列3 值最大的记录
Record max = records.stream()
.collect(Collectors.maxBy(Comparator.comparing(Record::getCol3)))
.orElse(null);
log.info("max: {}", Json.toJson(max));
输出结果:
max: {"col1":"c","col2":"4","col3":4}
收集所有记录中 列3 值的总和
int sum = records.stream()
.collect(Collectors.summingInt(Record::getCol3));
log.info("sum: {}", sum);
输出结果:
sum: 10
流的收集需要通过 Stream.collect() 方法完成,方法的参数是一个 Collector(收集器) ;收集结果时,需要根据收集结果的目标类型,传递特定的收集器实例,如上:
Collectors.toList()
Collectors.toSet()
Collectors.toMap()
Collectors.maxBy()
Collectors.summingInt()
Collectors(java.util.stream.Collectors) 是一个工具类,内置若干收集器,我们可以通过调用不同的方法快速获取相应的收集器实例。
收集器(java.util.stream.Collector)本质是一个 接口 ,包含以下五个方法:
Supplier supplier()
BiConsumer<A, T> accumulator()
BinaryOperator combiner()
Function<A, R> finisher()
Set characteristics()
以 Collectors.toList() 为例演示收集器的工作过程。
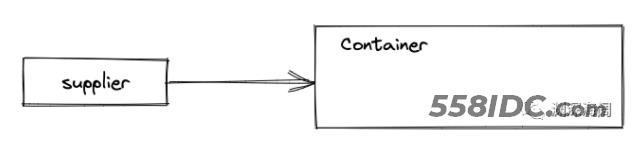
创建一个中间结果容器
supplier() 方法会返回一个 Supplier 实例,调用该实例的 get() 方法,会创建一个中间结果容器。
@Override
public Supplier<List<String>> supplier() {
return new Supplier<List<String>>() {
@Override
public List<String> get() {
List<String> container = new ArrayList<>();
return container;
}
};
}
考虑到收集的元素类型 String,这里的中间结果容器类型为 ArrayList 。
根据收集过程的需要,中间结果容器可以是任意的数据结构。
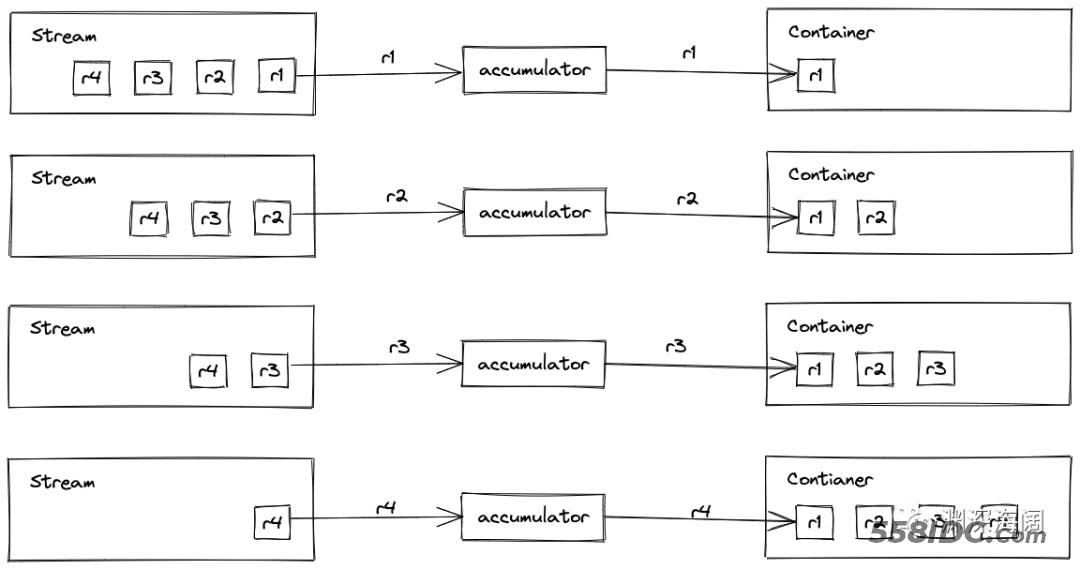
逐一遍历流中的每个元素,处理完成之后,添加到中间结果
accumulator() 方法会返回一个 BiConsumer 实例,它有一个 accept() 方法,
参数1:中间结果 参数2:流中遍历到的某个元素
遍历过程是 Java 自动完成的,每遍历一个元素,会自动调用 BiConsumer.accept 方法。我们只需要在方法中实现元素的处理过程,然后把元素的处理结果添加到中间结果中就可以了。
@Override
public BiConsumer<List<String>, String> accumulator() {
return new BiConsumer<List<String>, String>() {
@Override
public void accept(List<String> container, String col) {
container.add(col);
}
};
}
这个示例中,流中的元素不需要任何处理,直接添加至中间结果即可。
中间结果转换成最终结果
finisher() 方法会返回一个 Fuction 实例,它有一个 apply() 方法,
参数:中间结果 返回:最终结果
遍历过程结束之后,Java 会自动调用 Function.apply() 方法,将中间结果转换成最终结果。

@Override
public Function<List<String>, List<String>> finisher() {
return new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> container) {
return container;
}
};
}
这个示例中,中间结果就是最终结果,不需要任何处理,直接返回中间结果即可。
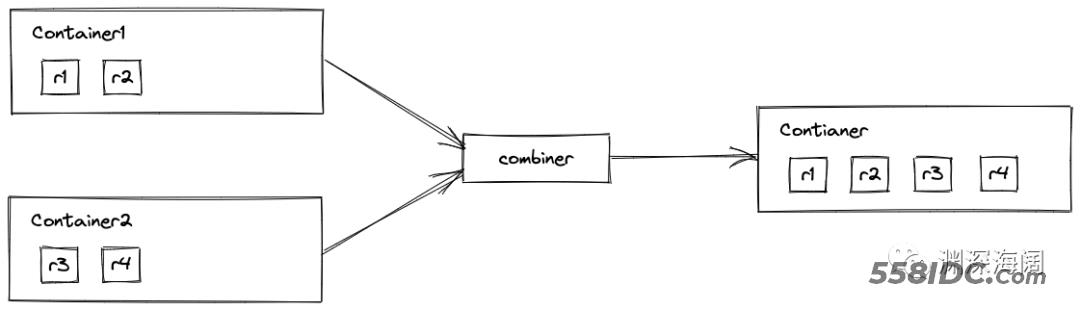
combiner()是做什么的?
流中的元素可以被并行处理,这样的流称为并行流。并行流相当于把一个大流切分成多个小流,内部使用多线程,并行处理这些小流。每一个小流遍历完成之后,都会产生一个小的中间结果,需要将这些小的中间结果合并成一个大的中间结果。
假设有两个小流,收集开始时,会创建两个中间结果:
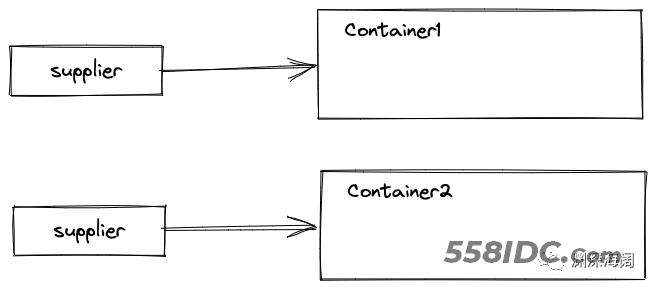
中间结果也是通过 Supplier.get() 方法创建的。
并行遍历两个小流,将各自流的处理结果添加到各自的中间结果中:
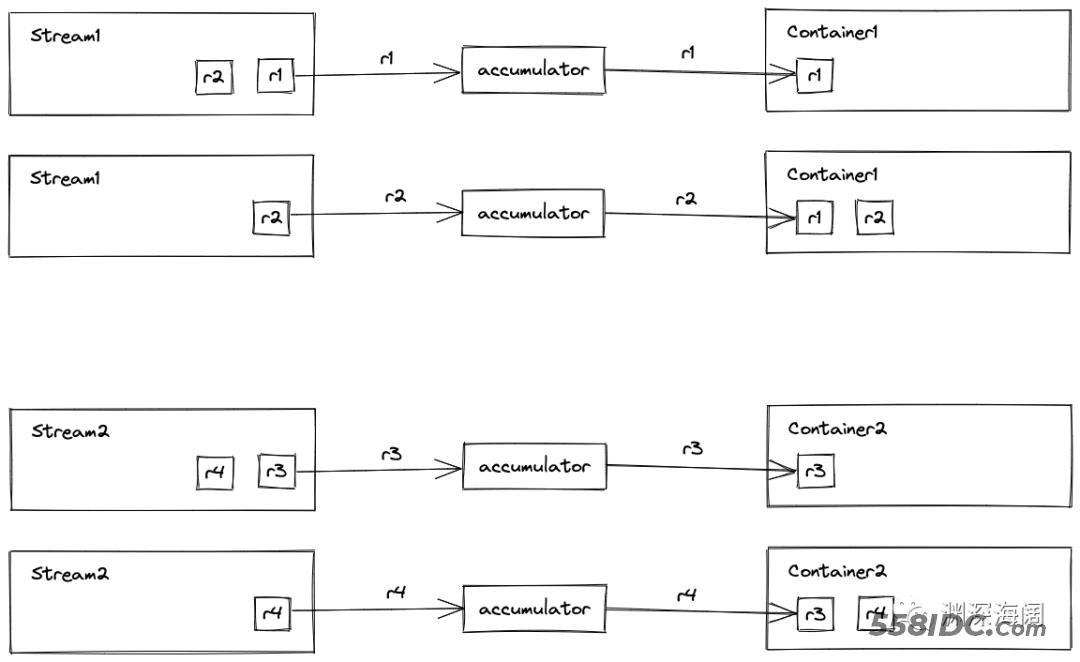
combiner() 方法会返回一个 BinaryOperator 实例,它有一个 apply() 方法:
参数1:中间结果1 参数2:中间结果2 返回:中间结果
Java 会在合适的时机自动调用 BinaryOperator.apply() 方法,将小的中间结果合并成大的中间结果。
@Override
public BinaryOperator<List<String>> combiner() {
return new BinaryOperator<List<String>>() {
@Override
public List<String> apply(List<String> container1, List<String> container2) {
container1.addAll(container2);
return container1;
}
};
}
characteristics()是什么的?
characteristics() 会返回一个 Characteristics(枚举)集合实例,用于设定收集器的特性,支持以下三个值:
CONCURRENT
收集器支持并发使用
UNORDERED
收集器不保证元素顺序
IDENTITY_FINISH
收集器中间结果可直接转换成最终结果
Java 可以根据这些特性值,保证收集器正确地、有效率地执行。
完整代码
Collector<String, List<String>, List<String>> collector = new Collector<String, List<String>, List<String>>() {
@Override
public Supplier<List<String>> supplier() {
return new Supplier<List<String>>() {
@Override
public List<String> get() {
List<String> container = new ArrayList<>();
return container;
}
};
}
@Override
public BiConsumer<List<String>, String> accumulator() {
return new BiConsumer<List<String>, String>() {
@Override
public void accept(List<String> container, String col) {
container.add(col);
}
};
}
@Override
public BinaryOperator<List<String>> combiner() {
return new BinaryOperator<List<String>>() {
@Override
public List<String> apply(List<String> container1, List<String> container2) {
container1.addAll(container2);
return container1;
}
};
}
@Override
public Function<List<String>, List<String>> finisher() {
return new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> container) {
return container;
}
};
}
@Override
public Set<Characteristics> characteristics() {
return new HashSet<>();
}
};
col1List = records.stream()
.map(Record::getCol1)
.collect(collector);
log.info("col1List: {}", Json.toJson(col1List));
到此这篇关于Java 流处理之收集器的文章就介绍到这了,更多相关Java 收集器内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!