一、Hadoop的安装
1. 下载地址:https://archive.apache.org/dist/hadoop/common/我下载的是hadoop-2.7.3.tar.gz版本。
2. 在/usr/local/ 创建文件夹zookeeper
mkdir hadoop

3.上传文件到Linux上的/usr/local/source目录下
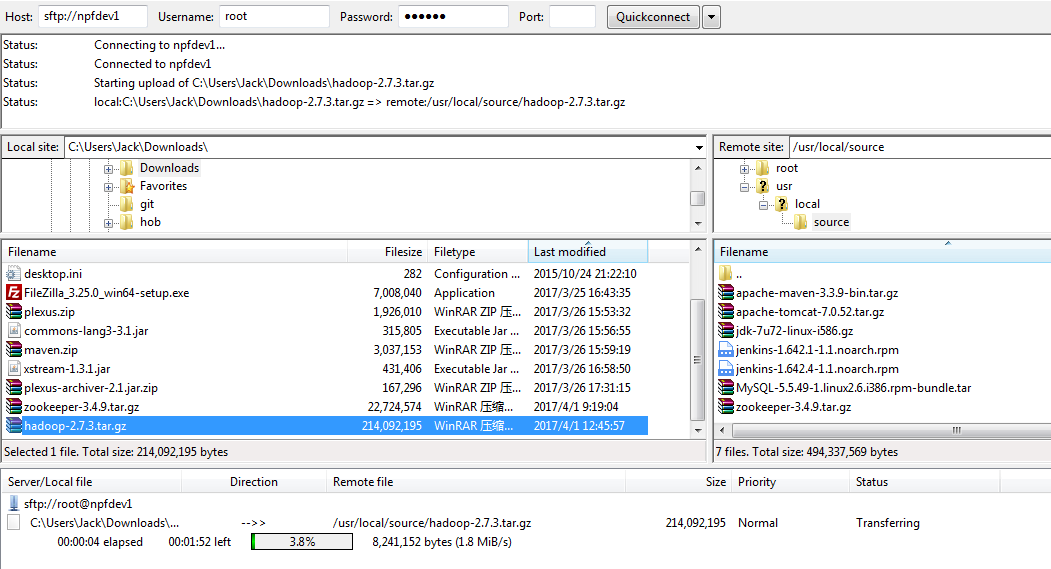
3.解压缩
运行如下命令:
tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop

4. 修改配置文件
进入到cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/ , 修改hadoop-env.sh

运行 vimhadoop-env.sh,修改JAVA_HOME

5.将Hadoop的执行命令加入到我们的环境变量里
在/etc/profile文件中加入:
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
执行/etc/profile文件:
source /etc/profile
6. 将npfdev1机器上的hadoop复制到npfdev2和npfdev3和npfdev4机器上。使用下面的命令:
首先分别在npfdev2和npfdev3和npfdev4机器上,建立/usr/local/hadoop目录,然后在npfdev1上分别执行下面命令:
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev2:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev3:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev4:/usr/local/hadoop/
记住:需要各自修改npfdev2和npfdev3和npfdev4的/etc/profile文件:
在/etc/profile文件中加入:
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
执行/etc/profile文件:
source /etc/profile
然后分别在npfdev1和npfdev2和npfdev3和npfdev4机器上,执行hadoop命令,看是否安装成功。并且关闭防火墙。
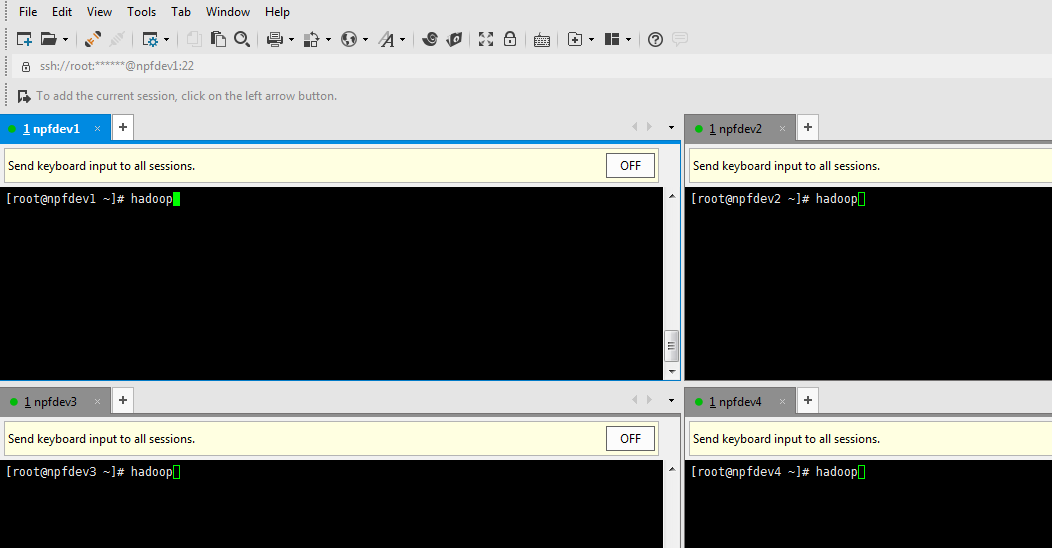
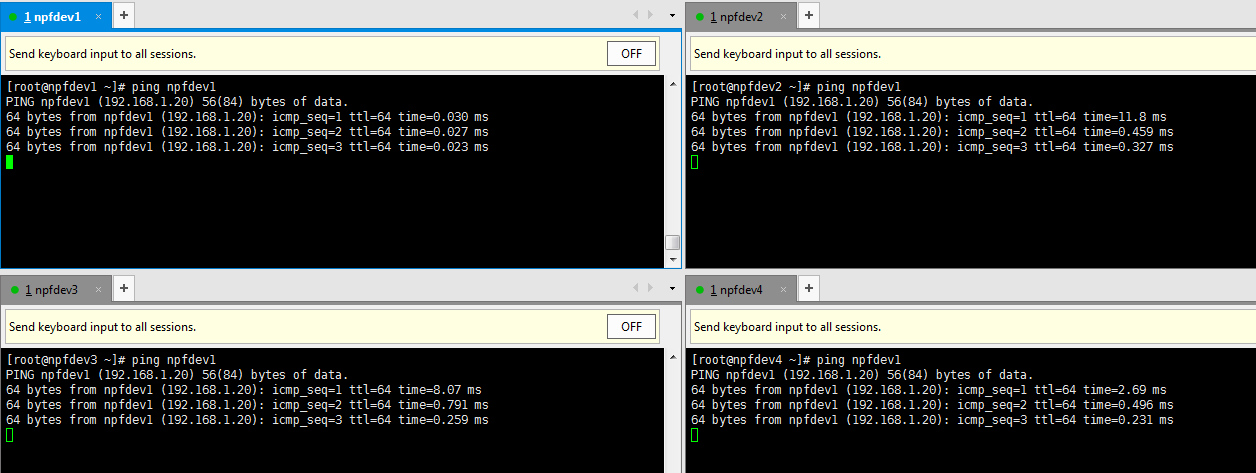
7. 确定所有机器之间可以相互ping通,使用下面的命令:
(1). ping npfdev1
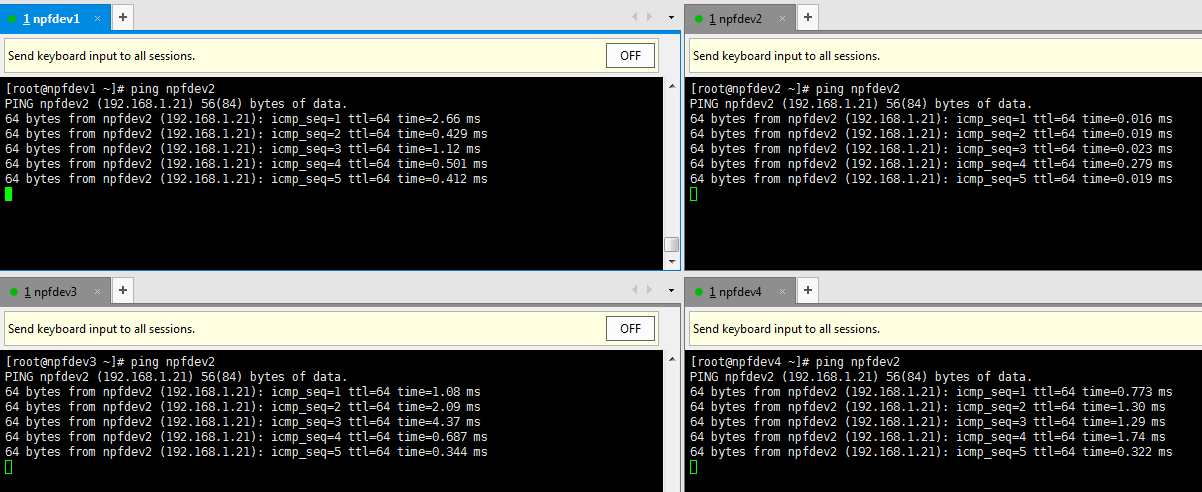
(2). ping npfdev2
(3). ping npfdev3
(4). ping npfdev4
8. 启动hadoop:
我们这里将npfdev1作为master,npfdev2和npfdev3和npfdev4分别作为三台slave。
(1).修改配置文件core-site.xml
进入 cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
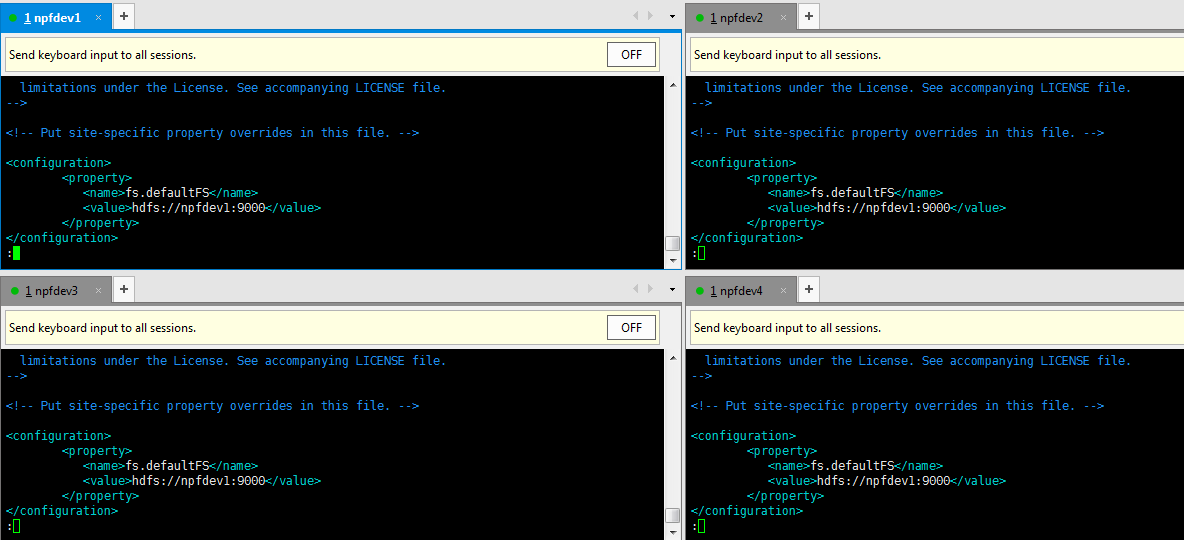
具体配置如下:
(2).在master机器npfdev1上启动namenode
首先需要格式化namenode,第一次使用需要格式化,后来就不需要了。
hdfs namenode -format

然后启动namenode:
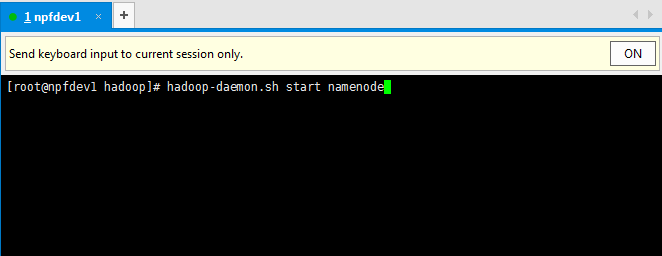
hadoop-daemon.sh start namenode
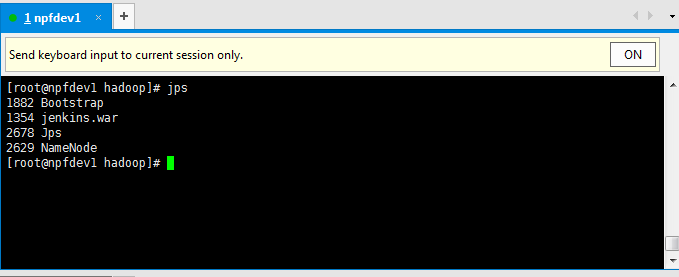
通过jps命令查看,如果有namenode的java进程,就说明我们启动namenode成功。
(3).在slave机器npfdev2,npfdev3,npfdev4上启动datanode

总结
以上所述是小编给大家介绍的Hadoop的安装与环境搭建教程图解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对自由互联网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!