本文分为两部分:
一、HTTP代理的逻辑
做过python爬虫的都知道,HTTP代理的设置时要在发送请求钱设置好,那HTTP代理的逻辑点在哪里呢?实际上,只需要在Scrapy 的项目结构中添加就好,具体代码如下:
# Scrapy 内置的 Downloader Middleware 为 Scrapy 供了基础的功能, # 定义一个类,其中(object)可以不写,效果一样 class SimpleProxyMiddleware(object): # 声明一个数组 proxyList = ['你购买的HTTP代理地址'] # Downloader Middleware的核心方法,只有实现了其中一个或多个方法才算自定义了一个 Downloader Middleware def process_request(self, request, spider): # 随机从其中选择一个,并去除左右两边空格 proxy = random.choice(self.proxyList).strip() # 打印结果出来观察 print("this is request ip:" + proxy) # 设置request的proxy属性的内容为代理ip request.meta['proxy'] = proxy # Downloader Middleware的核心方法,只有实现了其中一个或多个方法才算自定义了一个Downloader Middleware def process_response(self, request, response, spider): # 请求失败不等于200 if response.status != 200: # 重新选择一个代理ip proxy = random.choice(self.proxyList).strip() print("this is response ip:" + proxy) # 设置新的代理ip内容 request.mete['proxy'] = proxy return request return response每个 Downloader Middleware 定义了一个或多个方法的类,核心的方法有如下三个:
1.process_request(request, spider)
2.process_response(request,response, spider)
3.process_exception(request, exception, spider)
找到 setting.py 文件中的这块区域
#DDWNLQADER_MIDDLEWARES = {# *images.middlewares.ImagesDownloaderMiddleware": 543, # *images middlewares,LocalProxyMiddleware*: 100#}这部分需要修改,也就是取消注释,加上刚刚写的Middleware 类的路径
#DDWNLQADER_MIDDLEWARES = { 'scrapydownloadertest.middlewares.SimpleProxyMiddleware': 100,|}这样,我们就配置好了一个简单的HTTP代理,此时来到httpProxyIp.py 这个文件, 这个文件是我通过命令 scrapy genspider httpProxyIp icanhazip.com 生成的,创建成功内容如下:
# -*- coding: utf-8 -*-import scrapyclass HttpproxyipSpider(scrapy.Spider): name = 'httpProxyIp' allowed_domains = ['icanhazip.com'] start_urls = ['http://icanhazip.com/'] def parse(self, response): pass修改一下,最终代码如下所示:
# -*- coding: utf-8 -*-import scrapyfrom scrapy.cmdline import executeclass HttpproxyipSpider(scrapy.Spider): # spider 任务名 name = 'httpProxyIp' # 允许访问的域名 allowed_domains = ['icanhazip.com'] # 起始爬取的url start_urls = ['http://icanhazip.com/'] #spider 爬虫解析的方法,关于内容的解析都在这里完成; self表示实例的引用,response爬虫的结果 def parse(self, response): print('代理后的ip: ', response.text)#这个是main函数也是整个程序入口的惯用写法if __name__ == '__main__': execute(['scrapy', 'crawl', 'httpbin'])以上,就完成了Scrapy代理的设置和验证调试。
PS:icanhazi是一个显示当前访问者ip的网站,可以很方便的用来验证scrapy的HTTP代理设置是否成功。
二、如何配置动态的HTTP代理?
免费的可用率太低了,我用的是青果网络提供的服务。在控制台那可以获取台哦是工具,可以直接线上简单对接调试,测试HTTP代理资源替换、释放和通道配额等信息。
1.请求方式
请求方式包括POST和GET,默认POST请求,根据自己的需求选择;右侧网址则是接口网址完整信息,包括选择的key、接口方法等参数信息。

2.key
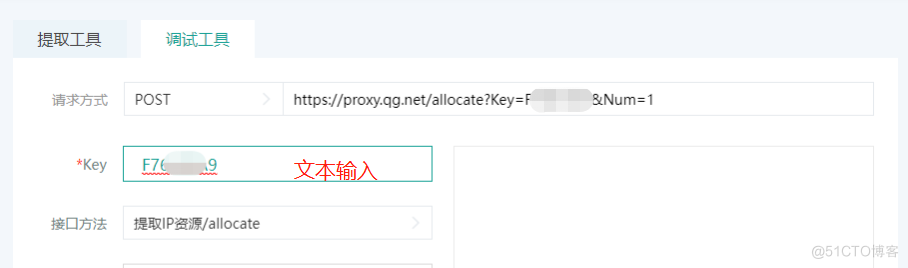
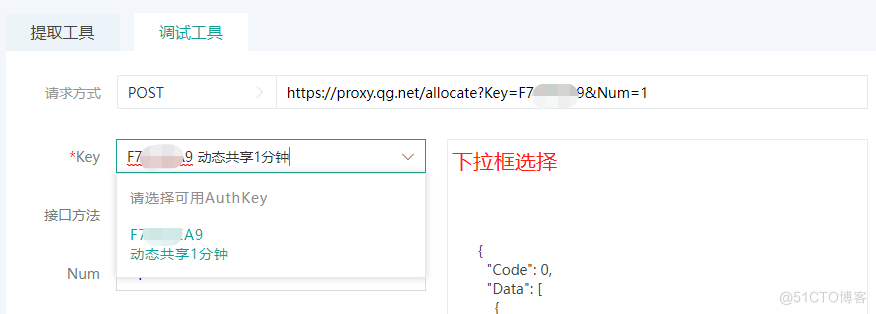
key为必选项,是对接接口的必要信息。key的选择根据登录状态不同,可操作性不同。未登录时,需手动输入key值,已登录时,可下拉选择已购买的代理业务key,key信息附带业务资源配置和业务备注信息,方便辨别业务。
未登录状态:
已登录状态:
3.接口方法
接口方法主要是选择要调试的接口类型,包括资源相关、IP白名单、信息查询三大模块,各个接口说明详情如下图:
接口类型
API
描述
通用资源管理相关
- allocate
- extract
- replace
- release
- query
- 调用 allocate申请HTTP代理资源
- 调用extract获取IP资源池全部可用的IP信息
- 调用replace用于释放并申请新的HTTP代理,更换IP资源
- 调用release释放申请到的IP,以便于再次进行IP申请
- 调用query查询用户可用的HTTP代理资源列表
独占代理专用相关
- monopolize_resources
- monopolize_resources
- monopolize_resources
-monopolize_resources/newest_ips
-monopolize_resources/idle
- 用POST调用接口申请独占资源
-用GET调用接口查询可用的独占资源
- 用DELETE调用接口释放独占资源
-用PUT调用接口请求重拨独占资源
-用GET调用接口查询空闲的独占资源
白名单管理相关
- whitelist/query
- whitelist/add
- whitelist/del
- 调用 whitelist/query用于查询IP的白名单
- 调用whitelist/add用于添加IP的白名单
- 调用whitelist/del用于删除IP的白名单
资源信息查询
- info/quota
- resources
- 调用 info/quota查询IP提取余量
- 调用resources查询平台可用的HTTP代理资源列表
4.参数类型
调试工具中各个参数根据不同的接口类型对应显示,各个参数有不同的含义,详情如下:
参数名
是否必选
描述
Key
是
要申请IP的业务的Key值,下拉选择即可;
IP
是
HTTP代理;多个以逗号分割;*代表全部;
Num
否
申请的IP个数,默认1个,最大不超过套餐内IP数量最大值;
KeepAlive
否
IP生存周期,其中动态独享默认24小时,动态共享默认购买的套餐存活周期时长;
AreaId
否
区域ID;默认随机;
ISP
否
运营商ID;默认随机;1:电信,2:移动,3:联通,4:BGP
Detail
否
是否获取代理IP的详情,默认为 0关闭,1为开启;
Distinct
否
申请的IP是否去重,默认为0不去重,1为开启去重;动态共享代理、动态独享代理适用。
DataFormat
否
数据格式,本接口取值:json、html、txt ,默认为 json格式
DataSeparator
否
分隔符,自定义
5.结果参数说明
点击“测试”,右侧文本框区域显示接口请求结果,返回结果参数说明:
参数名
描述
Code
申请IP结果编码:0(成功)-1(失败)。
TaskID
接口请求任务ID,可通过该IP释放该任务所申请到的IP;
Total
获取到的代理IP总数量
Available
获取到的代理IP可用数量
Used
获取到代理IP已使用数量
Num
申请的代理IP数量
TotalNum
总IP数,主要是资源查询
Data
代理IP数据信息,包含节点IP、端口、失效日期
Msg
公共参数,本接口取值:区域ID.
部分转载自: https://www.lsjlt.com/news/160957.html