1、获取小说名称、章节页链接、章节名 list_html = requests.get(url=url,headers=headers)selector =etree.HTML(list_html.text)lis =selector.xpath('/html/body/div[3]/div[2]/div[1]/div[2]/ul/li/a/@href') #提取所有章节页titl
1、获取小说名称、章节页链接、章节名
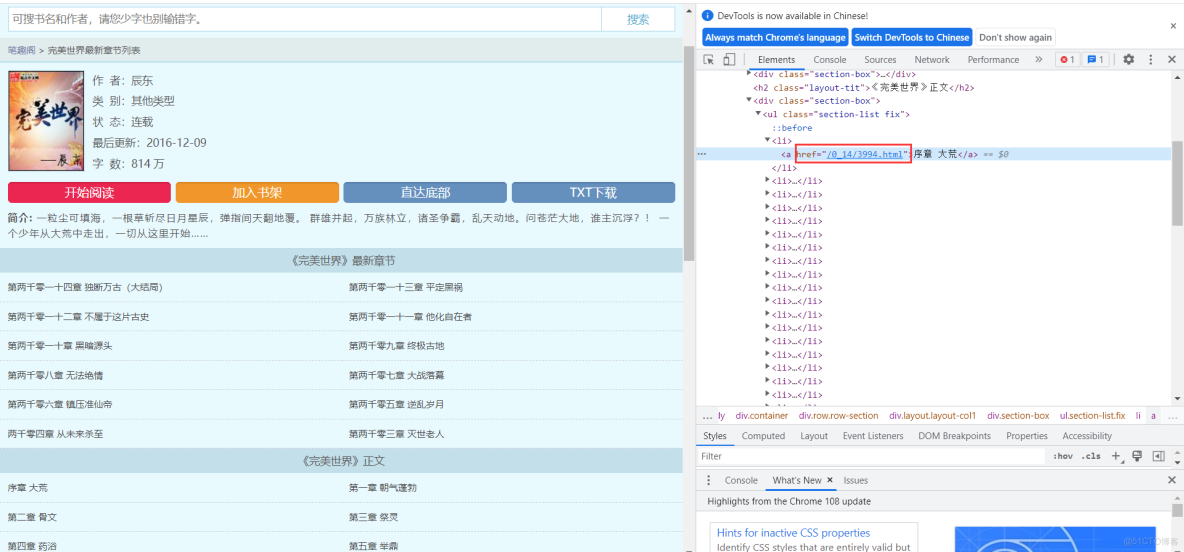
2、拼接所有章节页链接
lis =["http://www.bqge.com" + i for i in lis] #拼接所有章节完整链接3、提取章节名和内容并下载
for li,chapter in zip(lis,chapters): req = requests.get(url=li,headers=headers) sel = etree.HTML(req.text) content = sel.xpath('////*[@id="content"]/p/text()') #获取小说内容 content = '\n'.join(content) #连接小说内容,#用换行符\n 拼接列表 this_chapter =f'\n{chapter}\n{content}' with open(file=file_name,mode='a',encoding='UTF-8') as f: f.write(this_chapter) print(f'{chapter}--下载完成!') #打印下载4、翻页爬取
if __name__ == '__main__': urls = ['http://www.bqge.com/0_14/{}/'.format(str(i)) for i in range(1,44)] for url in urls: get_info(url) time.sleep(1)5、代码
import requestsfrom lxml import etreeimport timeheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}def get_info(url): list_html = requests.get(url=url,headers=headers) selector =etree.HTML(list_html.text) lis =selector.xpath('/html/body/div[3]/div[2]/div[1]/div[2]/ul/li/a/@href') #提取所有章节页 title = selector.xpath('/html/body/div[3]/div[1]/div/div/div[2]/div[1]/h1/text()')[0] chapters = selector.xpath('/html/body/div[3]/div[2]/div[1]/div[2]/ul/li/a/text()') #获取章节标题 print(title,chapters) file_name = f'完美世界/{title}.txt' #定义本地存储名称 lis =["http://www.bqge.com" + i for i in lis] #拼接所有章节完整链接 for li,chapter in zip(lis,chapters): req = requests.get(url=li,headers=headers) sel = etree.HTML(req.text) content = sel.xpath('////*[@id="content"]/p/text()') #获取小说内容 content = '\n'.join(content) #连接小说内容,#用换行符\n 拼接列表 this_chapter =f'\n{chapter}\n{content}' with open(file=file_name,mode='a',encoding='UTF-8') as f: f.write(this_chapter) print(f'{chapter}--下载完成!') #打印下载if __name__ == '__main__': urls = ['http://www.bqge.com/0_14/{}/'.format(str(i)) for i in range(1,44)] for url in urls: get_info(url) time.sleep(1)