一、场景
最近买了华为云的云服务器,也搞了一个域名,使用halo开源建站工具搭建自己的个人博客。虽然访问量不大,但是毕竟是自己的博客,数据安全性还是需要好好考虑的,需要考虑数据备份。虽然可以直接脚本打包好相关的文件,然后下载到本地,再上传到百度网盘。不过感觉这种方式不够智能,也比较麻烦。刚好也开通了百度网盘超级会员,所以就构思打包好之后就直接上传到百度网盘。这样就基本不用自己做什么,只需要定时上去看看上传是否ok就行了。

很好,需求确定了,接下来就是具体开发过程了!!!

二、环境
软件
版本
python
3.6.8
百度网盘平台 Python SDK
V0.0.1
halo
1.6.1

三、正文
先展示整个流程的思维导图,看下图:
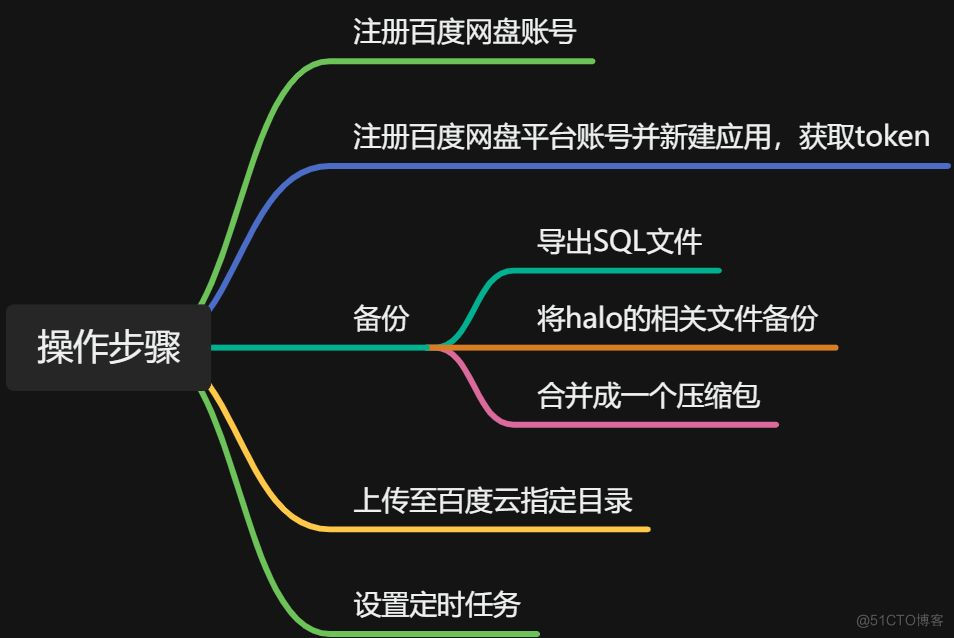
1. 注册百度网盘账号
请没有百度网盘的小伙伴自行点击以下链接百度网盘官网进行注册!
2. 注册百度网盘平台账号并新建应用,获取token
2.1 注册百度网盘平台账号并新建应用
请点击百度网盘开放平台进行注册,注册之后,点击右上角的控制台进入,如下图:

进入之后,会看到以下界面(博主是已经创建好应用了,所以会有两个应用):

点击创建应用按钮,进入应用创建流程,可以选择智能设备或者软件,这里我推荐使用智能设备,这样不用填写回调地址,可以直接根据接口获取对应的token。如果创建完毕,就可以看到以下信息界面:

这里的信息都保留着,接下来就会用到的。

2.2 获取python SDK
在百度网盘开放平台的开放支持里面,点击进去文档中心,可以看到以下界面:

我们点击SDK,下载python SDK,然后解压到自己的python项目里面,如图:

demo目录里面有很多示例,大家可以看看,也可以自己做针对性的改造。我这里主要用到了demo/auth、demo/upload两个文件的东西。
2.3 验证获取token
这里,我们可以查看demo/auth的源码,主要关注 以下代码:
# 获取授权链接oauthtoken_devicecode()# 获取 鉴权tokenoauthtoken_devicetoken()接下来,我给大家讲一下具体流程:

2.3.1 获取授权链接
看下面源码,把client_id设置为 2.1新建应用的AppKey,然后运行以下代码
def oauthtoken_devicecode(): """ devicecode get device code """ # Enter a context with an instance of the API client with openapi_client.ApiClient() as api_client: # Create an instance of the API class api_instance = auth_api.AuthApi(api_client) client_id = "" # str | scope = "basic,netdisk" # str | # example passing only required values which don't have defaults set try: api_response = api_instance.oauth_token_device_code(client_id, scope) pprint(api_response) except openapi_client.ApiException as e: print("Exception when calling AuthApi->oauth_token_device_code: %s\n" % e)获取结果如下:
{'device_code': '设备码', 'expires_in': 300, 'interval': 5, 'qrcode_url': '二维码链接', 'user_code': '授权码', 'verification_url': '鉴权链接'}2.3.2 进行授权,获取鉴权码
我们在已经登录百度网盘的浏览器上面,直接复制鉴权链接打开,然后输入我们的授权码,如下图

点击继续之后,就可以看oauthtoken_devicetoken()方法,代码如下,其中 code为上一步的设备码,client_id为应用的AppKey,client_secret为应用的SecretKey。
def oauthtoken_devicetoken(): """ get token by device code """# Enter a context with an instance of the API client with openapi_client.ApiClient() as api_client: # Create an instance of the API class api_instance = auth_api.AuthApi(api_client) code = "" # str | client_id = "" # str | client_secret = "" # str | # example passing only required values which don't have defaults set try: api_response = api_instance.oauth_token_device_token(code, client_id, client_secret) pprint(api_response) except openapi_client.ApiException as e: print("Exception when calling AuthApi->oauth_token_device_token: %s\n" % e)运行方法之后,可以获取以下结果:
{ 'access_token': '鉴权码', 'expires_in': 过期时间,单位秒, 'refresh_token': '刷新token,有效期一年', 'scope': 'basic netdisk', 'session_key': '', 'session_secret': ''}我们可以将结果保存到一个token_info.json文件里面。作为下一步的使用。

好了,获取token这关键一步已经完成了。接下来就是搞具体的开发流程啦!!!
3. 具体备份流程
3.1 导出SQL文件
我们可以导出mysql一个库的数据进行备份,这样以后做博客迁移,只需要执行SQL,就可以实现文章的迁移了。

在这里,我们主要使用mysqldump的命令将整个库进行导出,脚本如下,大家根据实际情况进行修改:
mysqldump -h116.x.x.63 -P3306 -u用户名 -p'用户密码' halodb --max_allowed_packet=512M --set-gtid-purged=OFF > dump.sql下图是我导出来的结果:

具体的源码如下:
def dumpSql(nowtime, store_dir_path): logger.info("进行数据库备份") sql_path = store_dir_path + "/halodb_" + nowtime + ".sql" if os.path.exists(sql_path): logger.info("存在历史数据 "+sql_path+",进行重命名") os.rename(sql_path,sql_path+"_bak") bash_shell = "mysqldump -h116.x.x.63 -P3306 -u用户名 -p'用户密码' halodb --max_allowed_packet=512M --set-gtid-purged=OFF > " + sql_path result = os.popen(bash_shell) logger.info("执行命令的结果为:" + result.read())3. 2 备份halo相关文件
目前我们的halo数据的默认路径为/root/.halo/下面,包括配置文件、附件、日志及主题文件。我们为了以后可以使用,就直接打包整个/root/.halo目录,但是需要排除掉日志文件。不然随着时间的迁移,会导致我们的数据越来越大。Linux打包排除额外目录的,可以参考我的博客 《Linux tar 打包排除某些文件夹》,我这里就不具体展开了。核心代码如下:
def dumpHalo(nowtime, store_dir_path): logger.info("进行 博客数据备份") halo_path = store_dir_path + "/halodb_" + nowtime + ".tar.gz" if os.path.exists(halo_path): logger.info("存在历史数据 "+halo_path+",进行重命名") os.rename(halo_path,halo_path+"_bak") bash_shell = " tar -zcf "+halo_path+" --exclude=/root/.halo/logs /root/.halo" result = os.popen(bash_shell) logger.info(bash_shell+ " 执行命令的结果为:" + result.read())
3.3 将以上两个文件打包成压缩包
因为sql文件和halo的文件都是单独的,所以需要都压缩到一起,形成一个压缩包,减少压缩频次。当然,我们也需要考虑可能有备份文件的情况,所以需要考虑进行排除。源码具体如下:
def tarDumpResult(store_dir_path): tarName = store_dir_path+".tar.gz" bash_shell = " tar -zcf "+tarName+" --exclude=*_bak "+store_dir_path if os.path.exists(tarName): logger.info("存在历史数据 "+tarName+",进行重命名") os.rename(tarName,tarName+"_bak") logger.info("开始打包整体数据,命令为:"+bash_shell) result = os.popen(bash_shell) logger.info("执行命令的结果为:" + result.read())4. 上传文件至百度网盘
接下来就是关键一步,将压缩好的文件给上传到百度网盘。这里大概分成以下几步:
4.1 创建目录
一般我们应用的上传目录统一为:/apps/具体应用名称/下午,我们可以在百度网盘的这个目录下面,新建 halo博客备份目录,然后作为我们文件上传的父级目录。然后就可以在上面,按天进行目录创建,然后上传文件。结果如下:

目录的核心源码为:
def mkdir(dirName, access_token,logger): blockList = getBlockList(dirName, False,logger) fileSize = 0 isDir = 1 id = precreate(dirName, dirName, blockList, fileSize, isDir, access_token,logger) if (id is not None): create(dirName, dirName, id, blockList, fileSize, isDir, access_token,logger)4.2 上传文件
按照 4.1创建好目录之后,就可以将文件上传到指定目录下面,如图:

上传文件的源码为:
def uploadFile(filePath, fileName, access_token,logger): blockList = getBlockList(filePath,True,logger) fileSize = os.path.getsize(filePath) isDir = 0 id = precreate(filePath, fileName, blockList, fileSize, isdir=isDir, access_token=access_token,logger=logger) if (id is not None): upload(filePath, fileName, id, blockList, fileSize, access_token=access_token,logger=logger) create(filePath, fileName, id, blockList, fileSize, isdir=isDir, access_token=access_token,logger=logger)
5. 设置定时任务
脚本编写完毕之后,就可以打包放到服务器上面,然后使用crontab进行定时任务设置,如下:
0 1 * * * sh /root/BaiduPanProject/startBackHalo.sh这里设置的是每天凌晨1点进行数据备份,从百度网盘的截图来看,任务是有按时处理的。我也贴一下其中一天的日志给大家看看。
2022-12-02 01:00:01,857 - __main__ - INFO - 开始进行博客 halo 备份2022-12-02 01:00:01,857 - __main__ - INFO - 进行数据库备份2022-12-02 01:00:02,715 - __main__ - INFO - 执行命令的结果为:2022-12-02 01:00:02,715 - __main__ - INFO - 进行 博客数据备份2022-12-02 01:00:03,590 - __main__ - INFO - 执行命令的结果为:2022-12-02 01:00:03,590 - __main__ - INFO - 开始打包整体数据,命令为: tar -zcf /root/mysqlbackup/20221202.tar.gz --exclude=*_bak /root/mysqlbackup/202212022022-12-02 01:00:03,915 - __main__ - INFO - 执行命令的结果为:2022-12-02 01:00:03,915 - __main__ - INFO - 64c2ac696d279a5df19ed3f2022-12-02 01:00:04,319 - __main__ - INFO - 预上传结果返参为:2022-12-02 01:00:04,320 - __main__ - INFO - {'path': '/apps/主机文件接入/halo博客备份/20221202', 'uploadid': 'N1-', 'return_type': 1, 'block_list': [], 'errno': 0, 'request_id': 89234848072658169}2022-12-02 01:00:04,320 - __main__ - INFO - uploadId=N1-2022-12-02 01:00:04,727 - __main__ - INFO - 创建文件结果返参:2022-12-02 01:00:04,727 - __main__ - INFO - {'ctime': 1669914004, 'fs_id': 7938101217951, 'isdir': 1, 'mtime': 1669914004, 'path': '/apps/主机文件接入/halo博客备份/20221202', 'status': 0, 'errno': 0, 'name': '/apps/主机文件接入/halo博客备份/20221202', 'category': 6}2022-12-02 01:00:04,752 - __main__ - INFO - 663b65e54251862490398498f30e2022-12-02 01:00:05,071 - __main__ - INFO - 预上传结果返参为:2022-12-02 01:00:05,071 - __main__ - INFO - {'path': '/apps/主机文件接入/halo博客备份/20221202/20221202.tar.gz', 'uploadid': 'N1-', 'return_type': 1, 'block_list': [0], 'errno': 0, 'request_id': 89234850203106}2022-12-02 01:00:05,071 - __main__ - INFO - uploadId=N1-2022-12-02 01:00:07,260 - __main__ - INFO - 上传分片结果:2022-12-02 01:00:07,260 - __main__ - INFO - {'md5': '663b65e5425149039298498f30e', 'request_id': 7770563615756}2022-12-02 01:00:07,745 - __main__ - INFO - 创建文件结果返参:2022-12-02 01:00:07,746 - __main__ - INFO - {'category': 6, 'ctime': 1669914007, 'from_type': 1, 'fs_id': 892662682184, 'isdir': 0, 'md5': '437034e1ev90a80a85b6d3bf4c6', 'mtime': 1669914007, 'path': '/apps/主机文件接入/halo博客备份/20221202/20221202.tar.gz', 'server_filename': '20221202.tar.gz', 'size': 10420731, 'errno': 0, 'name': '/apps/主机文件接 入/halo博客备份/20221202/20221202.tar.gz'}
四、扩展
4. 1 添加日志文件输出
一开始开发的时候,是直接print输出的,但是很简陋,也没有持久化到日志文件里面,到时有问题不好检索。所以就考虑加入日志输出,主要代码如下:
import logging# 文件持久化到上一层目录 logslogging.basicConfig(level=logging.INFO,filename="../logs/log"+nowtime+".log", format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')logger = logging.getLogger(__name__)# 使用logger.info("开始进行博客 halo 备份")五、总结
通过平台联动,减少自己的工作量,一定程度上解放了自己的双手!!!

六、源码相关
如果需要本篇博文的源码,可以关注我的公众号枫夜之求索阁,输入“halo备份”,就会返回相关的下载链接。
求赞、求关注

如果我的文章对大家产生了帮忙,可以在文章底部点个赞或者收藏;
如果有好的讨论,可以留言;
如果想继续查看我以后的文章,可以点击关注
也可以扫描以下二维码,关注我的公众号:枫夜之求索阁,查看我最新的分享!

